Apache Hadoop er en softwareramme, der behandler og lagrer big data på tværs af klyngen af råvarehardware. Hadoop er baseret på MapReduce-modellen til at behandle enorme mængder data på en distribueret måde.
Denne MapReduce-tutorial fik flere funktioner i MapReduce. Når du har læst dette, vil du tydeligt forstå, hvorfor MapReduce passer bedst til behandling af enorme mængder data.
Først vil vi se en lille introduktion til MapReduce-rammen. Derefter vil vi udforske forskellige funktioner i MapReduce.
Lad os starte med introduktionen til MapReduce-rammen.
Introduktion til MapReduce
MapReduce er en softwareramme til at skrive applikationer, der kan behandle enorme mængder data på tværs af klynger af billige noder. Hadoop MapReduce er behandlingsdelen af Apache Hadoop.
Det er også kendt som hjertet af Hadoop. Det er den mest foretrukne databehandlingsapplikation. Adskillige aktører i e-handelssektoren, såsom Amazon, Yahoo og Zuventus, osv. bruger MapReduce-rammen til databehandling af store mængder.
Lad os nu studere de forskellige funktioner i Hadoop MapReduce.
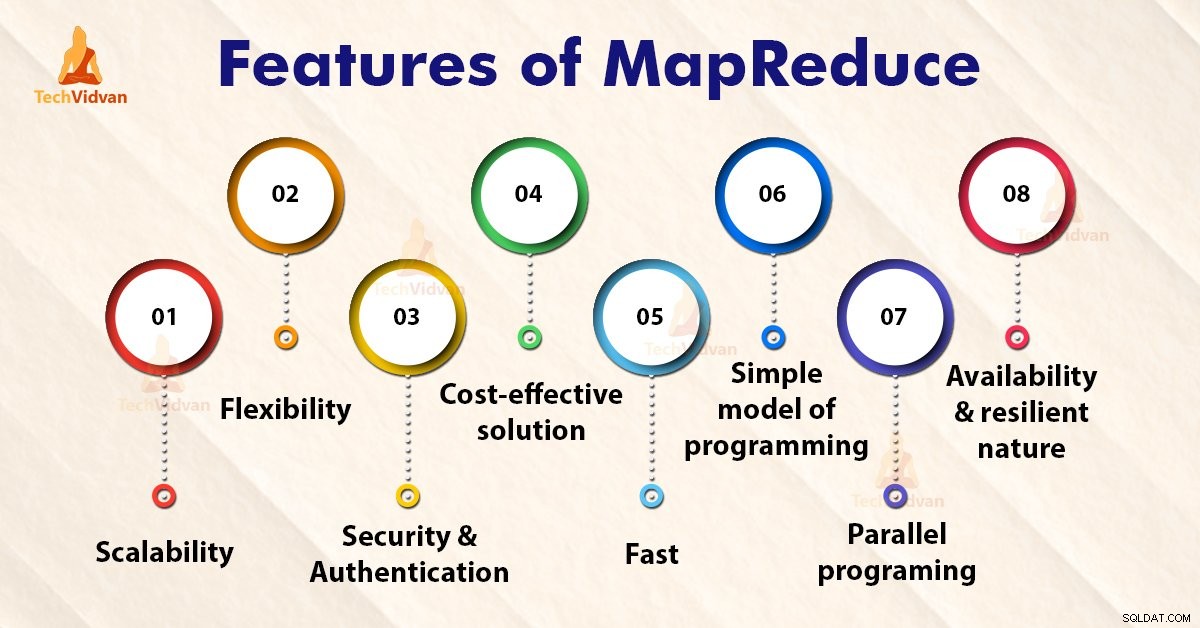
Funktioner i MapReduce
1. Skalerbarhed
Apache Hadoop er en yderst skalerbar ramme. Dette er på grund af dets evne til at gemme og distribuere enorme data på tværs af masser af servere. Alle disse servere var billige og kan fungere parallelt. Vi kan nemt skalere lager- og beregningskraften ved at tilføje servere til klyngen.
Hadoop MapReduce-programmering gør det muligt for organisationer at køre applikationer fra store sæt af noder, som kan involvere brugen af tusindvis af terabyte data.
Hadoop MapReduce-programmering gør det muligt for erhvervsorganisationer at køre applikationer fra store sæt noder. Dette kan bruge tusindvis af terabyte data.
2. Fleksibilitet
MapReduce-programmering gør det muligt for virksomheder at få adgang til nye datakilder. Det gør det muligt for virksomheder at operere på forskellige typer data. Det giver virksomheder adgang til såvel strukturerede som ustrukturerede data og opnår betydelig værdi ved at få indsigt fra de mange datakilder.
Derudover giver MapReduce-rammen også understøttelse af flere sprog og data fra kilder lige fra e-mail, sociale medier til clickstream.
MapReduce behandler data i simple nøgleværdi-par og understøtter således datatyper inklusive metadata, billeder og store filer. Derfor er MapReduce fleksibel til at håndtere data i stedet for traditionel DBMS.
3. Sikkerhed og godkendelse
MapReduce-programmeringsmodellen bruger HBase- og HDFS-sikkerhedsplatformen, der kun giver adgang til de godkendte brugere til at betjene dataene. Således beskytter det uautoriseret adgang til systemdata og forbedrer systemsikkerheden.
4. Omkostningseffektiv løsning
Hadoops skalerbare arkitektur med MapReduce-programmeringsrammerne tillader lagring og behandling af store datasæt på en meget overkommelig måde.
5. Hurtigt
Hadoop bruger en distribueret lagringsmetode kaldet et Hadoop Distributed File System, der grundlæggende implementerer et kortlægningssystem til at lokalisere data i en klynge.
De værktøjer, der bruges til databehandling, såsom MapReduce-programmering, er generelt placeret på de samme servere, som giver mulighed for hurtigere behandling af data.
Så selvom vi har at gøre med store mængder ustrukturerede data, tager Hadoop MapReduce kun minutter at behandle terabyte af data. Den kan behandle petabytes af data på kun en time.
6. Simpel model for programmering
Blandt de forskellige funktioner i Hadoop MapReduce er en af de vigtigste funktioner, at den er baseret på en simpel programmeringsmodel. Grundlæggende giver dette programmører mulighed for at udvikle MapReduce-programmerne, som kan håndtere opgaver nemt og effektivt.
MapReduce-programmerne kan skrives i Java, hvilket ikke er særlig svært at hente og også bruges meget. Så alle kan nemt lære og skrive MapReduce-programmer og opfylde deres behov for databehandling.
7. Parallel programmering
Et af de vigtigste aspekter af arbejdet med MapReduce-programmering er dens parallelle behandling. Den opdeler opgaverne på en måde, der tillader deres udførelse parallelt.
Den parallelle behandling giver flere processorer mulighed for at udføre disse opdelte opgaver. Så hele programmet køres på kortere tid.
8. Tilgængelighed og modstandsdygtig natur
Når dataene sendes til en individuel node, videresendes det samme sæt data til nogle andre noder i en klynge. Så hvis en bestemt node lider af en fejl, er der altid andre kopier til stede på andre noder, som stadig kan tilgås, når det er nødvendigt. Dette sikrer høj tilgængelighed af data.
En af de vigtigste funktioner, som Apache Hadoop tilbyder, er dens fejltolerance. Hadoop MapReduce-rammen har evnen til hurtigt at genkende fejl, der opstår.
Den anvender derefter en hurtig og automatisk gendannelsesløsning. Denne funktion gør den til en game-changer i verden af big data-behandling.
Oversigt
Jeg håber efter at have læst denne artikel, at du tydeligt har forstået de forskellige funktioner i Hadoop MapReduce. Artiklen inddrog forskellige funktioner i MapReduce. MapReduce-rammen er skalerbar, fleksibel, omkostningseffektiv og hurtig behandlingssystem.
Det tilbyder sikkerhed, fejltolerance og godkendelse. MapReduce er en simpel model for programmering og tilbyder parallel programmering.