I vores tidligere Hadoop tut o rial , har vi givet dig en detaljeret beskrivelse af InputFormat. Nu i denne blog vil vi dække Hadoop OutputFormat.
Vi vil diskutere Hvad er OutputFormat i Hadoop, Hvad er RecordWritter i MapReduce OutputFormat. Vi vil også dække typerne af OutputFormat i MapReduce.
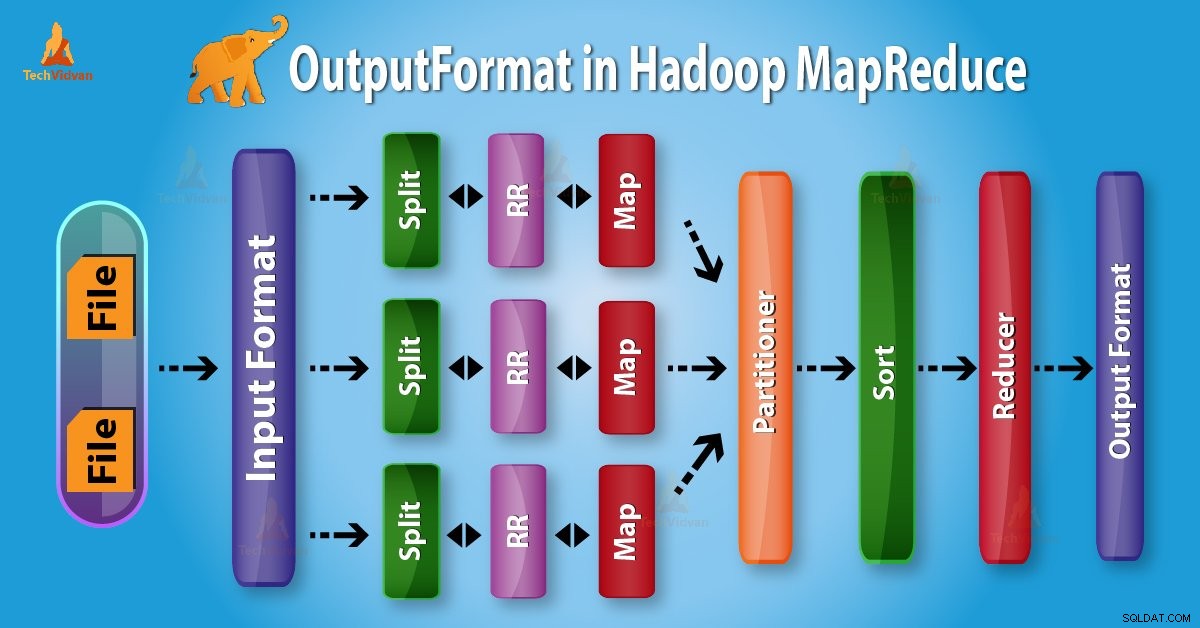
Introduktion til Hadoop OutputFormat
Outputformat kontrollere output-specifikationen for udførelse af Map-Reduce-jobbet. Den beskriver, hvordan RecordWriter-implementering bruges til at skrive output til outputfiler.
Inden vi starter med OutputFormat, lad os først lære, hvad der er RecordWriter, og hvad er RecordWriters arbejde i MapReduce?
1. RecordWriter i Hadoop MapReduce
Som vi ved, Reducer tager Mappers mellemudgang som input. Derefter kører den en reduceringsfunktion på dem for at generere output, der igen er nul eller flere nøgleværdi-par.
Så RecordWriter i MapReduce job execution skriver disse output nøgleværdi-par fra Reducer-fasen til outputfiler.
2. Hadoop OutputFormat
Fra oven er det tydeligt, at RecordWriter tager outputdata fra Reducer. Derefter skriver den disse data til outputfiler. OutputFormat bestemmer, hvordan disse outputnøgleværdipar skrives i outputfiler af RecordWriter.
Funktionerne OutputFormat og InputFormat ligner hinanden. OutputFormat-instanser bruges til at skrive til filer på den lokale disk eller i HDFS. I MapReduce jobudførelse på basis af outputspecifikation;
- Hadoop MapReduce-job kontrollerer, at output-mappen ikke allerede findes.
- OutputFormat i MapReduce-jobbet giver RecordWriter-implementeringen, der skal bruges til at skrive outputfilerne for jobbet. Derefter gemmes outputfilerne i et filsystem.
Rammen bruger FileOutputFormat.setOutputPath() metode til at indstille outputbiblioteket.
Typer af outputformat i MapReduce
Der er forskellige typer OutputFormat, som er som følger:
1. TextOutputFormat
Standard OutputFormat er TextOutputFormat. Den skriver (nøgle, værdi) par på individuelle linjer af tekstfiler. Dens nøgler og værdier kan være af enhver type. Årsagen bag er, at TextOutputFormat omdanner dem til streng ved at kalde toString() på dem.
Det adskiller nøgleværdi-par med et tabulatortegn. Ved at bruge MapReduce.output.textoutputformat.separator egenskab, vi kan også ændre det.
KeyValueTextOutputFormat bruges også til at læse disse output tekstfiler.
2. SequenceFileOutputFormat
Dette OutputFormat skriver sekvensfiler til dets output. SequenceFileInputFormat er også mellemformatbrug mellem MapReduce-job. Den serialiserer vilkårlige datatyper til filen.
Og det tilsvarende SequenceFileInputFormat vil deserialisere filen til de samme typer. Den præsenterer dataene for den næstemapper på samme måde, som den blev udsendt af den tidligere reduktion. Statiske metoder styrer også komprimeringen.
3. SequenceFileAsBinaryOutputFormat
Det er en anden variant af SequenceFileInputFormat. Den skriver også nøgler og værdier til sekvensfil i binært format.
4. MapFileOutputFormat
Det er en anden form for FileOutputFormat. Den skriver også output som kortfiler. Rammen tilføjer en nøgle i en MapFile i rækkefølge. Så vi er nødt til at sikre, at reducer udsender nøgler i sorteret rækkefølge.
5. Flere udgange
Dette format gør det muligt at skrive data til filer, hvis navne er afledt af outputnøgler og værdier.
6. LazyOutputFormat
I MapReduce-jobkørsel opretter FileOutputFormat nogle gange outputfiler, selvom de er tomme. LazyOutputFormat er også et indpakningsoutputformat.
7. DBOoutputFormat
Det er OutputFormat til at skrive til relationelle databaser og HBase. Dette format sender også reducere output til en SQL-tabel. Den accepterer også nøgleværdi-par. I denne har nøglen en type, der udvider DBwritable.
Konklusion
Derfor bruges forskellige outputformater efter behov. Håber du finder denne blog nyttig. Hvis du har spørgsmål om Hadoop OutputFormat, så læg venligst en kommentar i et kommentarfelt. Vi vil med glæde løse dem.