I vores tidligere blog har vi studeretHadoop Introduktion og Funktioner i Hadoop , Nu i denne blog vil vi dække HDFS NameNode High Availability-funktionen i detaljer.
Først og fremmest vil vi diskutere HDFS NemNode High Availability Architecture, derefter med implementeringen af Hadoop High Availability Architecture ved hjælp af Quorum Journal Nodes og Shared Storage.
HDFS NameNode høj tilgængelighed
I HDFS , data er højt tilgængelige og tilgængelige på trods af hardwarefejl. HDFS er det mest pålidelige lagringssystem designet til lagring af meget store filer.
HDFS følger master/slave topologi. I hvilken master er NameNode og slaver er DataNode . NameNode gemmer metadata. Metadata inkluderer antallet af blokke, deres placering, replikaer og andre detaljer. For hurtigere hentning af data er metadata tilgængelige i masteren. NameNode vedligeholder og tildeler opgaver til slaveknuden.
NameNode var Single Point of Failure (SPOF) før Hadoop 2.0. HDFS-klyngen havde en enkelt NameNode. Hvis NameNode fejler, går hele klyngen ned.
Single point of failure begrænser høj tilgængelighed på følgende måder:
- Hvis en uplanlagt hændelse udløser, som f.eks. knudenedbrud, vil klyngen være utilgængelig, medmindre en operatør genstartede den nye navneknude.
- Også planlagte vedligeholdelsesaktiviteter som hardwareopgraderinger på NameNode vil resultere i nedetid for Hadoop-klyngen.
HDFS NameNode High Availability Architecture
Introduktion af Hadoop 2.0 overvinde denneSPOF ved at yde support til flere NameNode. HDFS NameNode High Availability-arkitektur giver mulighed for at køre to redundante NameNodes i den samme klynge i en aktiv/passiv konfiguration med en varm standby.
- Aktiv NameNode – Den håndterer alle HDFS-klientoperationer i HDFS-klyngen.
- Passiv NameNode – Det er en standby-navnenod. Den har lignende data som aktiv NameNode.
Så hver gang Active NameNode fejler, vil passiv NameNode tage hele ansvaret for den aktive node. HDFS-klyngen fortsætter således med at fungere.
Problemer med at opretholde konsistens i HDFS High Availability-klyngen er som følger:
- Active og Standby NameNode skal altid være synkroniseret med hinanden, dvs. de skal have de samme metadata. Denne tilladelse til at genindsætte Hadoop-klyngen til den samme navnerumstilstand, hvor den gik ned. Og dette vil give os hurtig failover.
- Der bør kun være én NameNode aktiv ad gangen. Ellers vil to NameNode føre til korruption af dataene. Vi kalder dette scenarie som et "Split-Brain Scenario ”, hvor en klynge bliver opdelt i den mindre klynge. Hver enkelt mener, at det er den eneste aktive klynge. "Fægtning" undgår et sådant hegn er en proces til at sikre, at kun én NameNode forbliver aktiv på et bestemt tidspunkt.
Implementering af Hadoop High Availability Architecture
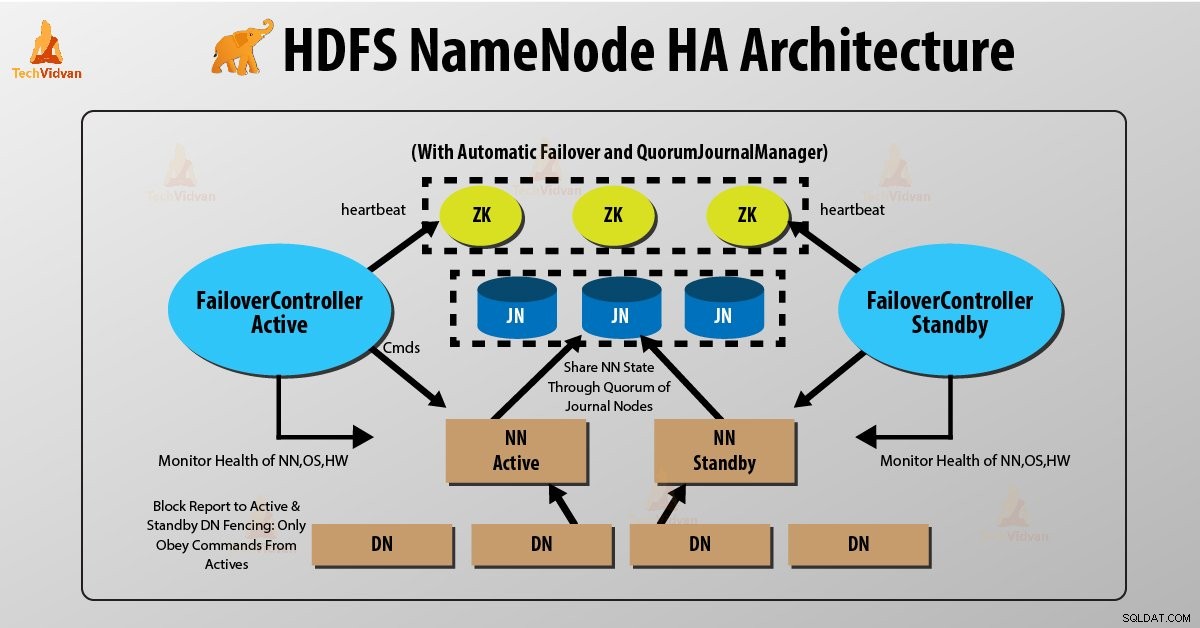
To NameNodes kører på samme tid i HDFS NameNode High Availability Architecture. HDFS-klienten kan implementere Active og Standby NameNode-konfigurationen på følgende to måder:
- Brug af Quorum Journal Noder
- Brug af delt lager
1. Brug af kvorumjournalnoder
Quorum Journal Noder er en HDFS-implementering. QJN leverer redigeringslogfiler. Det tillader at dele disse redigeringslogfiler mellem den aktive og standby NameNode.
Standby NameNode kommunikerer og synkroniserer med den aktive NameNode for høj tilgængelighed. Det vil ske af en gruppe dæmoner kaldet "Journal nodes". Kvorumsjournalknuderne kører som en gruppe af journalnoder. Der skal være mindst tre journalnoder.
For N journal noder kan systemet højst tolerere (N-1)/2 fejl. Systemet fortsætter således med at fungere. Så for tre journalnoder kan systemet tolerere fejl på én {(3-1)/2} af dem.
Når en aktiv node udfører en modifikation, logger den modifikation til alle journal noder.
Standby-knuden læser redigeringerne fra journalknuderne og anvender på sit eget navneområde på en konstant måde. I tilfælde af failover vil standbyen sikre sig, at den har læst alle redigeringerne fra journalknuderne, før den promoverer sig selv til den aktive tilstand. Dette sikrer, at navneområdets tilstand er fuldstændig synkroniseret, før der opstår en fejl.
For at give en hurtig failover skal standby-noden have opdaterede oplysninger om placeringen af datablokke i klyngen. For at dette kan ske, er IP-adressen på både NameNode tilgængelig for alle datanoderne, og de sender blokeringsoplysninger og hjerteslag til begge NameNode.
Fægtning af NameNode
For at en HA-klynge skal fungere korrekt, bør kun én af NameNodes være aktiv ad gangen. Ellers ville navneområdets tilstand afvige mellem de to NameNodes. Så hegn er en proces til at sikre denne ejendom i en klynge.
- Journalknuderne udfører denne indhegning ved kun at tillade én NameNode at være forfatter ad gangen.
- Standby NameNode påtager sig ansvaret for at skrive til journalnoderne og forbyder enhver anden NameNode at forblive aktiv.
- Endelig kan den nye aktive NameNode udføre sine aktiviteter.
2. Brug af delt lager
Standby og aktiv NameNode synkroniseres med hinanden ved at bruge "delt lagerenhed". Til denne implementering skal både aktiv NameNode og standby Namenode have adgang til den bestemte mappe på den delte lagerenhed (dvs. netværksfilsystemet).
Når aktiv NameNode udfører en navneområdeændring, logger den en registrering af ændringen til en redigeringslogfil, der er gemt i den delte mappe. Standby NameNode overvåger denne mappe for redigeringer, og når der sker ændringer, anvender standby NameNode dem på sit eget navneområde. I tilfælde af fejl vil standby NameNode sikre, at den har læst alle redigeringerne fra den delte lagring, før den promoverer sig selv til den aktive tilstand. Dette sikrer, at navnerumstilstanden er fuldstændig synkroniseret, før der sker failover.
For at forhindre "split-brain-scenariet", hvor navneområdets tilstand afviger mellem de to NameNode, skal en administrator konfigurere mindst én hegnsmetode for det delte lager.
Konklusion
Derfor sørger Hadoop 2.0 HDFS HA for enkelt aktiv NameNode og enkelt standby NameNode. Men nogle implementeringer kræver en høj grad af fejltolerance . Hadoop ny version 3.0, giver brugeren mulighed for at køre mange standby NameNodes.
For eksempel konfiguration af fem journalnoder og tre NameNode. Som et resultat er hadoop-klyngen i stand til at tolerere svigt af to noder i stedet for én.
Del venligst dine erfaringer og forslag i forbindelse med HDFS NameNode High Availability i kommentarfeltet nedenfor.