Dette er del 2 i denne blogserie. Du kan læse del 1 her: Digital transformation er en datarejse fra kant til indsigt
Denne blogserie følger fremstillings-, drifts- og salgsdata for en tilsluttet køretøjsproducent, mens dataene gennemgår stadier og transformationer, der typisk opleves i en stor produktionsvirksomhed på forkant med den nuværende teknologi. Den første blog introducerede et falskt forbundne køretøjsfremstillingsfirma, The Electric Car Company (ECC), for at illustrere fremstillingsdatastien gennem datalivscyklussen. For at opnå dette udnytter ECC Cloudera Data Platform (CDP) til at forudsige begivenheder og have et top-down-billede af bilens fremstillingsproces på dens fabrikker, der er placeret over hele kloden.
Efter at have gennemført dataindsamlingstrinnet i den forrige blog, er ECC's næste trin i datalivscyklussen Data Enrichment. ECC vil berige de indsamlede data og vil gøre dem tilgængelige til brug i analyse og modeloprettelse senere i datalivscyklussen. Nedenfor er hele sættet af trin i datalivscyklussen, og hvert trin i livscyklussen vil blive understøttet af et dedikeret blogindlæg (se fig. 1):
- Dataindsamling – dataindtagelse og overvågning på kanten (uanset om kanten er industrielle sensorer eller personer i et køretøjs showroom)
- Databerigelse – datapipelinebehandling, -aggregering og -styring for at klargøre dataene til yderligere analyse
- Rapportering – levering af forretningsindsigt (salgsanalyse og forecasting, budgettering som eksempler)
- Visning – kontrol og drift af væsentlige forretningsaktiviteter (forhandlerdrift, produktionsovervågning)
- Forudsigende analyse – prædiktiv analyse baseret på AI og maskinlæring (forudsigende vedligeholdelse, efterspørgselsbaseret lageroptimering som eksempler)
- Sikkerhed og styring – et integreret sæt af sikkerheds-, styrings- og styringsteknologier på tværs af hele datalivscyklussen

Fig. 1 Virksomhedens datalivscyklus
Databerigelsesudfordring
ECC har brug for et omfattende overblik og en robust forståelse af alle data relateret til fremstilling, forhandlerdrift og forsendelse af deres køretøjer. De bliver også nødt til hurtigt at identificere problemer med dataene, såsom operationelle sensorer, der udløser data, der kan omfatte falske temperaturstigninger forårsaget af uplanlagte maskinstop eller pludselige opstarter. Data, der ikke har nogen relation til processen, når vedligeholdelsesarbejdere fjerner en sensor fra en syretank, mens de for eksempel udfører rutineinspektioner, bør ikke tages i betragtning i analysen.
Derudover står ECC over for følgende dataudfordringer, der skal løses for at få succes med at flytte motorproduktionen gennem sin forsyningskæde. Disse dataudfordringer omfatter følgende:
- Hentning af data i forskellige formater fra forskellige kilder: Data engineering pipelines kræver, at data bringes ind fra forskellige kilder og i mange forskellige formater. Uanset om data stammer fra sensorer, der sidder på produktionslinjen, understøtter produktionsoperationer eller ERP-data, der styrer forsyningskæden, skal det hele samles til yderligere analyse.
- Filtrering af redundante eller irrelevante data: Fjernelse af duplikerede eller ugyldige data og sikring af nøjagtigheden af resterende data er et nøgletrin i at forberede dataene til videre brug i avanceret forudsigende analyse.
- Evne til at identificere ineffektive processer: ECC kræver evnen til at se, hvilke dataprocesser der optager mest tid og ressourcer, hvilket gør det nemt at målrette mod underpræsterende dele af pipelinen for at fremskynde den overordnede proces.
- Mulighed til at overvåge alle processer fra en enkelt rude: ECC kræver et centraliseret system, der giver dem mulighed for at overvåge alle igangværende dataprocesser samt en mulighed for at udvide deres nuværende infrastruktur og samtidig bevare gennemsigtigheden.
Kurerede kvalitetsdatasæt er rygraden i ethvert avanceret analyseinitiativ. For at opnå dette skal der bruges en datateknisk ramme for at tillade bygningen af alle de rør og VVS, der er nødvendige for at flytte, manipulere og administrere data fra de forskellige køretøjsdele i datalivscyklussen.
Opbygning af en pipeline ved hjælp af Cloudera Data Engineering
Inden dataene beriges og diskuteres i den første blog, vil IT- og OT-datastrømme indsamlet fra fabrikken blive renset, manipuleret og ændret. Fabriks-id, maskin-id, tidsstempel, varenummer og serienummer kunne hentes fra en QR-kode, der er trykt på den elektriske motor. Efterhånden som motoren samles i det tilsluttede køretøj, registreres data såsom modeltype, VIN og basiskøretøjsomkostninger.
Efter at køretøjet er solgt, registreres salgsoplysninger såsom kundenavn, kontaktoplysninger, endelig salgspris og kundeplacering separat. Disse data vil være afgørende for at kontakte kunden for eventuelle tilbagekaldelser eller målrettet forebyggende vedligeholdelse. Geolokaliseringsdata gemmes også, hvilket vil hjælpe med at kortlægge kundernes placeringer til breddegrader og længdegrader for bedre at forstå, hvor disse motorer er placeret efter at være blevet solgt i et køretøj.
ECC vil bruge Cloudera Data Engineering (CDE) til at løse ovenstående dataudfordringer (se fig. 2). CDE vil derefter gøre dataene tilgængelige for Cloudera Data Warehouse (CDW), hvor de vil blive gjort tilgængelige for avancerede analyser og business intelligence-rapporter. CDE-trinene er beskrevet nedenfor.
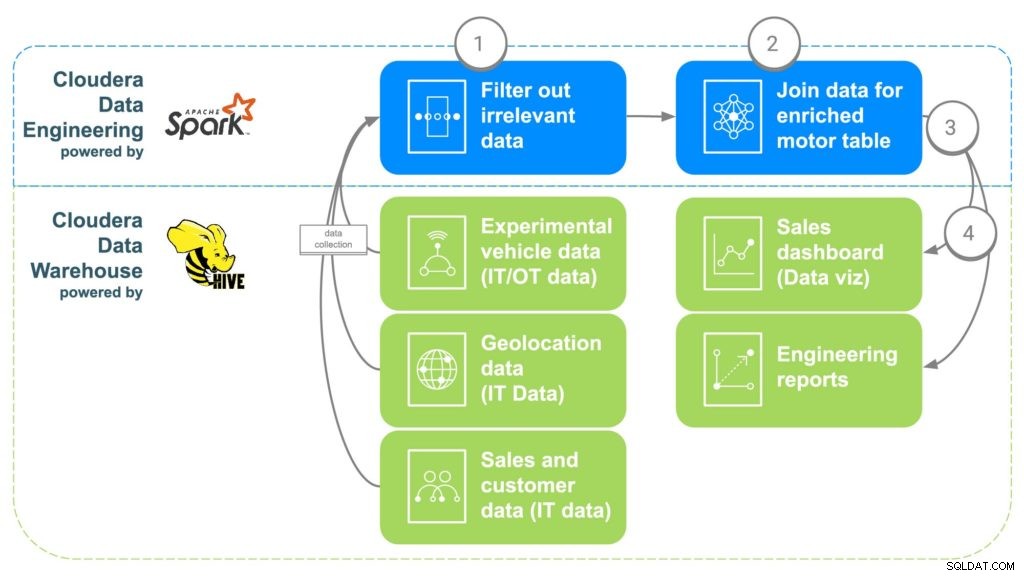
Fig. 2 ECC-databerigelsespipeline
TRIN 1:Filtrer og adskil dataene
Det første trin i at bruge CDE er at oprette et PySpark-job, der henter data fra disse forskellige "rå" kilder fra trin 1. Dette er en mulighed for at filtrere alle irrelevante data, såsom kunder under 16 år, for eksempel, da det er typisk den mindste kørealder. Duplikerede data og andre irrelevante data kan også filtreres eller adskilles.
TRIN 2:Kombiner dataene
For at kombinere alle data, vil CDE korrelere fælles links sammen. Først vil bilsalgsdata bindes til den kunde, der har købt bilen for at få kundens metadata, såsom kontaktoplysninger, alder, løn osv. Geolokaliseringsdata vil derefter blive brugt til at få mere præcise placeringsoplysninger for kunden , som vil hjælpe med at kortlægge motorerne senere. Delinstallationsdata vil blive brugt til at identificere serienumrene for hver motor, der blev installeret i kundens bil. Endelig vil fabriksdata blive justeret for at matche motorens serienummer, der vil identificere hvilken fabrik, maskine, og hvornår hver specifik motor blev oprettet.
TRIN 3:Send data til Cloudera Data Warehouse
Når alle data er samlet i en beriget tabel, vil en simpel Apache Spark-kommando skrive dataene ind i en ny tabel i Cloudera Data Warehouse. Dette vil gøre dataene tilgængelige for alle dataforskere, der måtte ønske at få adgang til dem for at foretage nogle yderligere analyser.
TRIN 4:Generer dashboards og rapporter til datavisualisering
Med alle data på ét sted kan der nu oprettes rapporter, som giver medarbejderne mulighed for at træffe bedre informerede beslutninger og åbne muligheder, der ikke eksisterede. Heatmaps kan laves for at spore motorens placering og korrelere eventuelle problemer med potentielle geografiske placeringer, såsom fejl på grund af ekstrem kulde eller varme. Disse data kan også bruges til at spore nøjagtigt, hvilke kunder der kan blive berørt, hvis der var et problem på en bestemt fabrik over et tidsrum, hvilket gør det nemt at spore kunder, som muligvis har brug for en tilbagekaldelse eller noget forebyggende vedligeholdelse.
Konklusion
Cloudera Data Engineering gør det muligt for ECC at bygge en pipeline, der kan korrelere produktions- og reservedelsdata, kundebrugstype, miljøforhold, salgsoplysninger og mere for at forbedre kundetilfredsheden og køretøjets pålidelighed. ECC nåede sine mål og adresserede deres udfordringer ved at spore data relateret til fremstillingen af dets motorer og gavne på følgende måder:
- ECC øgede tid til værdi ved at orkestrere og automatisere datapipelines for at levere kurerede kvalitetsdatasæt sikkert og gennemsigtigt fra forskellige datakilder.
- ECC var i stand til at identificere relevante data og filtrere eventuelle overflødige og duplikerede data fra.
- ECC var i stand til at opnå datapipeline-overvågning fra en enkelt rude, samtidig med at den var i stand til at blive advaret om at fange problemer tidligt gennem visuel fejlfinding for hurtigt at løse problemer, før virksomheden blev påvirket.
Se efter den næste blog, der vil dykke ned i rapportering, der vil vise, hvordan ECC-ingeniører kører ad-hoc-forespørgsler i CDW mod disse kurerede data samt forbinder dataene med andre relevante kilder i et virksomhedsdatavarehus. CDW letter at bringe alle data sammen og giver et indbygget datavisualiseringsværktøj til at gå fra forespurgte resultater til dashboards. Hold øje med den næste!
Flere ressourcer til dataindsamling
For at se alt dette i aktion, klik venligst på de relaterede links nedenfor for at lære mere databerigelse:
- Video – Hvis du gerne vil se og høre, hvordan dette blev bygget, kan du se videoen på linket.
- Tutorials – Hvis du gerne vil gøre dette i dit eget tempo, kan du se en detaljeret gennemgang med skærmbilleder og linje for linje instruktioner om, hvordan du opsætter og udfører dette.
- Meetup – Hvis du vil tale direkte med eksperter fra Cloudera, skal du deltage i et virtuelt møde for at se en livestreampræsentation. Der vil være tid til direkte spørgsmål og svar til sidst.
- Brugere – Klik på linket for at se mere teknisk indhold specifikt for brugere.