I vores tidligere Hadoop tutorial , har vi studeret Hadoop Partitioner i detaljer. Nu skal vi diskutere InputSplit i Hadoop MapReduce.
Her vil vi dække, hvad der er Hadoop InputSplit, behovet for InputSplit i MapReduce. Vi vil også diskutere, hvordan disse InputSplits oprettes i Hadoop MapReduce i detaljer.
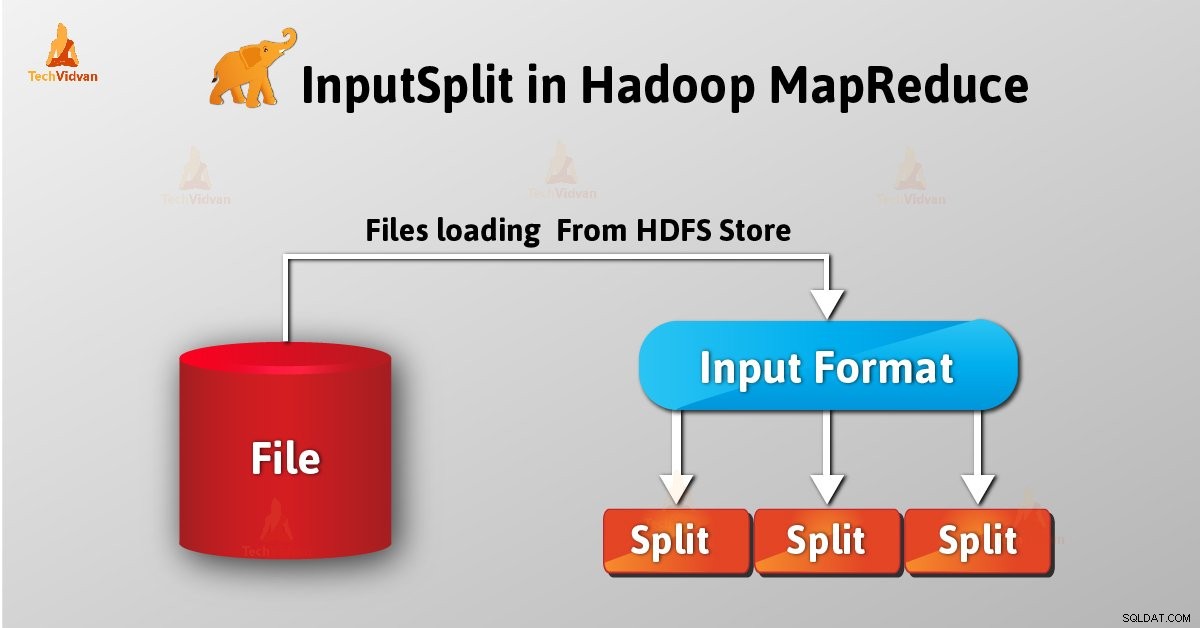
Introduktion til InputSplit i Hadoop
InputSplit er den logiske repræsentation af data i Hadoop MapReduce. Det repræsenterer de data, som den enkelte kortlægger processer. Således er antallet af kortopgaver lig med antallet af InputSplits. Framework opdeler opdelt i poster, som kortlægger processer.
MapReduce InputSplit længde er målt i bytes. Hver InputSplit har lagerplaceringer (værtsnavnestrenge). MapReduce-systemet placerer kortopgaver så tæt på opdelingens data som muligt ved at bruge lagerplaceringer.
Rammeprocesser Kortlæg opgaver i rækkefølgen efter størrelsen af opdelingerne, så den største bliver behandlet først (greedy approksimationsalgoritme). Dette minimerer jobkørselstiden.
Det vigtigste at fokusere på er, at Inputsplit ikke indeholder inputdata; det er blot en reference til dataene.
Hvordan oprettes InputSplits i Hadoop MapReduce?
Som bruger beskæftiger vi os ikke direkte med InputSplit i Hadoop, da InputFormat (da InputFormat er ansvarlig for at oprette inputsplit og opdele i posterne) opretter det. FileInputFormat opdeler en fil i 128 MB bidder.
Også ved at indstille kortlagt .min .opdel .størrelse parameter i mapred-site .xml brugeren kan ændre værdien efter behov. Herved kan vi også tilsidesætte parameteren i jobobjektet, der bruges til at sende et bestemt MapReduce-job.
Ved at skrive et brugerdefineret InputFormat kan vi også kontrollere, hvordan filen er opdelt i opdelinger.
InputSplit er brugerdefineret. Brugeren kan også styre opdelt størrelse baseret på størrelsen af data i MapReduce-programmet. Derfor er antallet af kortopgaver i en MapReduce-udførelse lig med antallet af InputSplits.
Ved at kalde 'getSplit()' , beregner kunden fordelingen for jobbet. Derefter blev det sendt til applikationsmasteren, som bruger deres lagerplaceringer til at planlægge kortopgaver, der behandler dem på klyngen.
Efter denne kortopgave overføres opdelingen til createRecordReader() metode. Derfra får den RecordReader for opdelingen. Derefter genererer RecordReader post (nøgle-værdi-par) , som den overfører til kortfunktionen.
Konklusion
Afslutningsvis kan vi sige, at InputSplit repræsenterer de data, som den enkelte kortlægger behandler. For hver opdeling oprettes en kortopgave. Derfor opretter InputFormat InputSplit.
Hvis du har spørgsmål om InputSplit i MapReduce, så skriv venligst en kommentar i et afsnit nedenfor.