I vores tidligere Hadoop blogs, vi har studeret hver komponent af Hadoop KortReducer processen i detaljer. I dette vil vi diskutere det meget interessante emne, dvs. Map Only job i Hadoop.
Først vil vi tage en kort introduktion af kortet og Reducer fase i Hadoop Mapreduce, og derefter diskuterer vi, hvad der er Map only job i Hadoop MapReduce.
Til sidst vil vi også diskutere fordele og ulemper ved Hadoop Map Only job i denne vejledning.
Hvad er Hadoop Map Only Job?
Kun-kort-job i Hadoop er den proces, hvor mapper udfører alle opgaver. Ingen opgave udføres af reduceren . Mappers output er det endelige output.
MapReduce er databehandlingslaget i Hadoop. Den behandler store strukturerede og ustrukturerede data gemt i HDFS . MapReduce behandler også en enorm mængde data parallelt.
Det gør den ved at opdele jobbet (indsendt job) i et sæt selvstændige opgaver (underjob). I Hadoop fungerer MapReduce ved at opdele behandlingen i faser:Kort og Reducer .
- Kort: Det er den første fase af behandlingen, hvor vi specificerer al den komplekse logiske kode. Det tager et sæt data og konverterer til et andet sæt data. Det opdeler hvert enkelt element i tupler (nøgle-værdi-par ).
- Reducer: Det er anden fase af behandlingen. Her specificerer vi letvægtsbehandling som aggregering/summation. Det tager output fra kortet som input. Derefter kombinerer den disse tupler baseret på nøglen.
Fra dette ordtællingseksempel kan vi sige, at der er to sæt parallelle processer, kortlægge og reducere. I kortprocessen opdeles det første input for at fordele arbejdet mellem alle kortknudepunkter som vist ovenfor.
Framework identificerer derefter hvert ord og tilknytter tallet 1. Det skaber således par kaldet tuples (nøgle-værdi) par.
I den første kortlægningsknude sender den tre ord løve, tiger og floden. Den producerer således 3 nøgleværdi-par som output fra noden. Tre forskellige nøgler og værdi sat til 1 og den samme proces gentages for alle noder.
Derefter sender den disse tuples til reduktionsknuderne. Partitioner udfører shuffling så alle tupler med samme nøgle går til den samme node.
I reduceringsprocessen er det, der dybest set sker, en sammenlægning af værdier eller rettere en operation på værdier, der deler den samme nøgle.
Lad os nu overveje et scenarie, hvor vi bare skal udføre operationen. Vi har ikke brug for aggregering, i sådanne tilfælde vil vi foretrække "Kun-kort job ’.
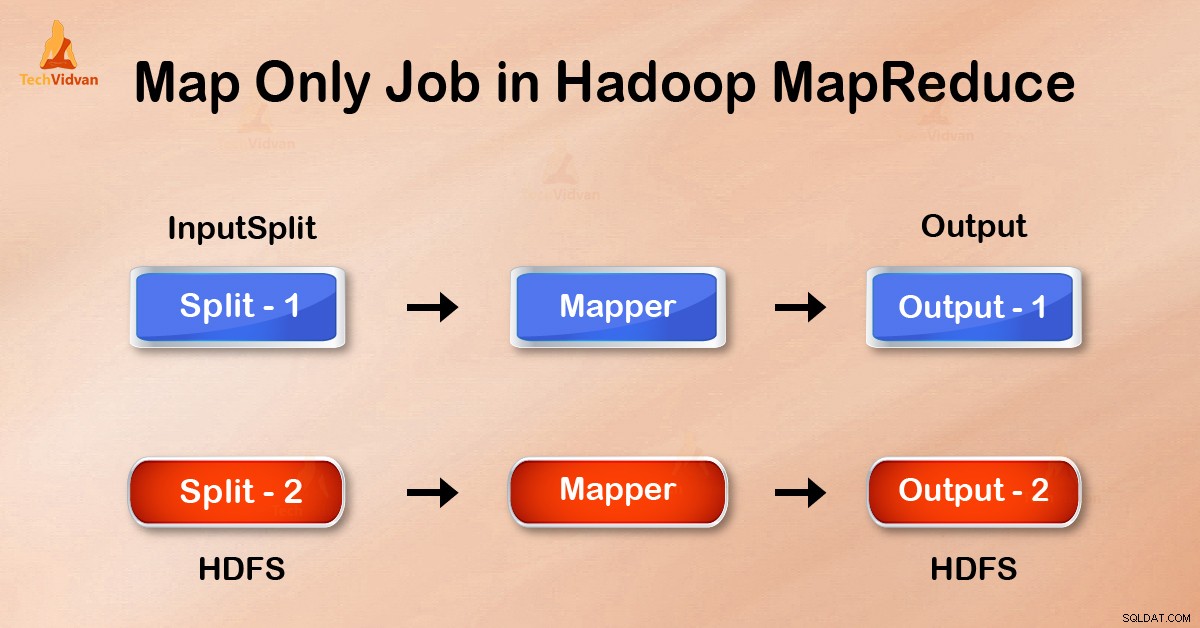
I Map-Only job udfører kortet alle opgaver med sin InputSplit . Reducer gør intet arbejde. Mappers output er det endelige output.
Hvordan undgår man Reduce Phase i MapReduce?
Ved at indstille job.setNumreduceTasks(0) i konfigurationen i en driver kan vi undgå at reducere fase. Dette vil gøre et antal reducerer som 0 . Således vil den eneste mapper udføre hele opgaven.
Fordele ved Map only job i Hadoop
I MapReduce job udførelse i mellem kort og reducerer faser er der nøgle-, sorterings- og blandfase. Blander – Sortering er ansvarlige for at sortere nøglerne i stigende rækkefølge. Derefter grupperes værdier baseret på de samme nøgler. Denne fase er meget dyr.
Hvis reduktionsfasen ikke er påkrævet, bør vi undgå det. Da man undgår at reducere fasen, vil sorterings- og blandingsfasen også elimineres. Derfor vil dette også spare netværksoverbelastning.
Årsagen er, at ved shuffling rejser et output fra mapperen for at reducere. Og når datastørrelsen er enorm, skal store data til reduktionen.
Outputtet fra mapperen skrives til lokal disk før afsendelse for at reducere. Men i job, der kun er kort, skrives dette output direkte til HDFS. Dette sparer yderligere tid og reducerer omkostningerne.
Konklusion
Derfor har vi set, at job, der kun er kort, reducerer overbelastningen af netværket ved at undgå at blande, sortere og reducere fase. Kort alene tager sig af den overordnede behandling og producerer output. VED at bruge job.setNumreduceTasks(0) dette er opnået.
Jeg håber, du har forstået Hadoop-kortets eneste job og dets betydning, fordi vi har dækket alt om Map Only job i Hadoop. Men hvis du har nogen spørgsmål, så kan du dele med os i kommentarfeltet.