I denne blog vil vi give dig den komplette introduktion af Hadoop Mapper . I
I denne blog vil vi svare på, hvad der er Mapper i Hadoop MapReduce, hvordan Hadoop Mapper virker, hvad er processen med Mapper i Mapreduce, hvordan Hadoop genererer nøgleværdi-par i MapReduce.
Introduktion til Hadoop Mapper
Hadoop Mapper behandler inputpost, der er produceret af RecordReader og genererer mellemliggende nøgleværdi-par. Mellemudgangen er helt anderledes end inputparret.
Outputtet fra mapperen er den fulde samling af nøgleværdi-par. Inden outputtet skrives for hver mapper-opgave, sker partitionering af output på basis af nøglen. Partitionering specificerer således, at alle værdierne for hver nøgle er grupperet sammen.
Hadoop MapReduce genererer én kortopgave for hver InputSplit.
Hadoop MapReduce forstår kun nøgleværdi-par af data. Så før du sender data til kortlæggeren, bør Hadoop-rammeværket skjule data i nøgleværdi-parret.
Hvordan genereres nøgleværdi-par i Hadoop?
Som vi har forstået, hvad der er mapper i hadoop, vil vi nu diskutere, hvordan Hadoop genererer nøgleværdi-par?
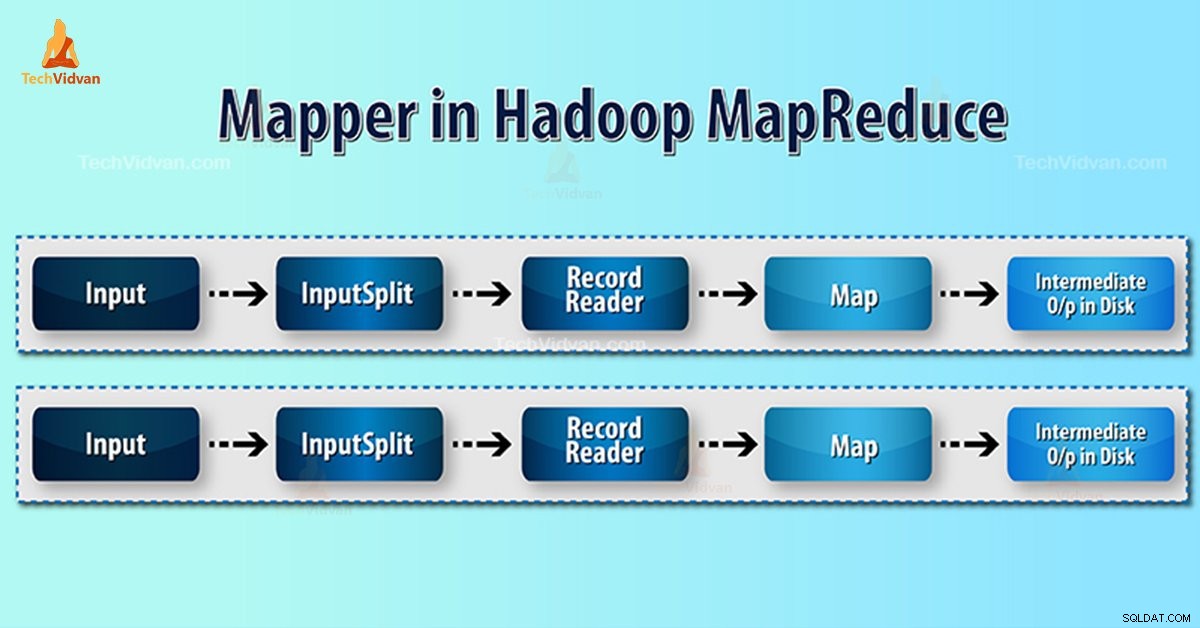
- InputSplit – Det er den logiske repræsentation af data genereret af InputFormat. I MapReduce-programmet beskriver det en arbejdsenhed, der indeholder en enkelt kortopgave.
- RecordReader- Den kommunikerer med inputSplit. Og konverterer derefter dataene til nøgleværdipar, der er egnede til læsning af Mapper. RecordReader bruger som standard TextInputFormat til at konvertere data til nøgleværdi-parret.
Mapper Process i Hadoop MapReduce
InputSplit konverterer den fysiske repræsentation af blokkene til logisk for Mapper. For at læse 100MB-filen kræver det f.eks. 2 InputSplit. For hver blok opretter rammen én InputSplit. Hver InputSplit opretter én mapper.
MapReduce InputSplit afhænger ikke altid af antallet af datablokke . Vi kan ændre antallet af en opdeling ved at indstille mapred.max.split.size-egenskaben under arbejdets udførelse.
MapReduce RecordReader er ansvarlig for at læse/konvertere data til nøgleværdi-par indtil slutningen af filen. RecordReader tildeler Byte offset til hver linje, der findes i filen.
Så modtager Mapper dette nøglepar. Mapper producerer det mellemliggende output (nøgle-værdi-par, som det er forståeligt at reducere).
Hvor mange kortopgaver i Hadoop?
Antallet af kortopgaver afhænger af det samlede antal blokke af inputfilerne. I MapReduce map ser det rigtige niveau af parallelitet ud til at være omkring 10-100 maps/node. Men der er 300 kort til CPU-light-kortopgaver.
For eksempel har vi en blokstørrelse på 128 MB. Og vi forventer 10 TB inputdata. Således producerer den 82.000 kort. Derfor afhænger antallet af kort af InputFormat.
Mapper =(samlet datastørrelse)/ (input opdelt størrelse)
Eksempel – datastørrelsen er 1 TB. Input opdelt størrelse er 100 MB.
Mapper =(1000*1000)/100 =10.000
Konklusion
Derfor tager Mapper i Hadoop et sæt data og konverterer det til et andet sæt data. Således opdeler den individuelle elementer i tupler (nøgle/værdi-par).
Håber du kan lide denne blok, hvis du har nogen forespørgsler om Hadoop mapper, så efterlad venligst en kommentar i et afsnit nedenfor. Vi vil med glæde løse dem.