Indtil nu har vi dækket Hadoop-introduktionen og Hadoop HDFS i detaljer. I denne vejledning vil vi give dig en detaljeret beskrivelse af Hadoop Reducer.
Her vil vi diskutere, hvad der er Reducer i MapReduce, hvordan Reducer fungerer i Hadoop MapReduce, forskellige faser af Hadoop Reducer, hvordan kan vi ændre antallet af Reducer i Hadoop MapReduce.
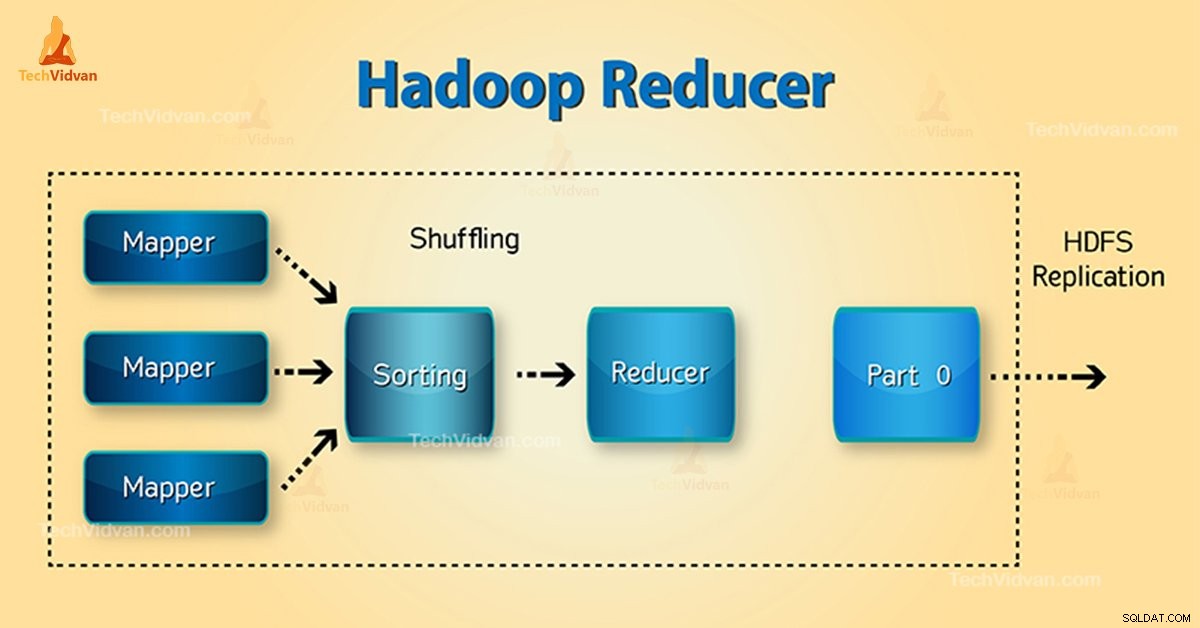
Hvad er Hadoop Reducer?
Reducer i Hadoop reducerer MapReduce et sæt mellemværdier, der deler en nøgle til et mindre sæt værdier.
I MapReduce jobudførelsesflow tager Reducer et sæt af et mellemliggende nøgleværdipar produceret af kortlæggeren som input. Derefter samler, filtrerer og kombinerer Reducer nøgleværdi-par, og dette kræver en bred vifte af behandling.
En-en-mapping finder sted mellem nøgler og reducering i MapReduce jobudførelse. De kører parallelt, da de er uafhængige af hinanden. Brugeren bestemmer antallet af reducerere i MapReduce.
Faser af Hadoop Reducer
Tre faser af Reducer er som følger:
1. Bland fase
Dette er den fase, hvor sorteret output fra mapperen er input til reducereren. Rammeværket henter ved hjælp af HTTP den relevante partition af output fra alle kortlæggere i denne fase.Sorteringsfase
2. Sorteringsfase
Dette er den fase, hvor input fra forskellige kortlæggere igen sorteres baseret på de lignende nøgler i forskellige kortlæggere.
Både Shuffle og Sort forekommer samtidigt.
3. Reducer fase
Denne fase opstår efter blanding og sortering. Reducer opgaveaggreger nøgleværdi-parrene. Med OutputCollector.collect() egenskaben, skrives output fra reduktionsopgaven til filsystemet. Reducer output er ikke sorteret.
Antal reduktioner i Hadoop MapReduce
Brugerindstil antallet af reduktioner ved hjælp af Job.setNumreduceTasks(int) ejendom. Således det rigtige antal reduktionsmidler ved formlen:
0,95 eller 1,75 ganget med (
Så med 0,95 starter alle reduktionsapparater straks. Begynd derefter at overføre kortoutput, når kortene er færdige.
Hurtigere node afslutter den første runde af reducering med 1,75. Så lancerer den den anden bølge af reducering, som gør et meget bedre job med belastningsbalancering.
Med stigningen i antallet af reduktionsanordninger:
- Rammeoverhead stiger.
- Belastningsbalanceringen øges.
- Omkostningerne ved fejl falder.
Konklusion
Derfor tager Reducer mappers output som input. Bearbejd derefter nøgleværdi-parrene og producerer outputtet. Reducer output er det endelige output. Hvis du kan lide denne blog, eller du har en forespørgsel relateret til Hadoop Reducer, så del venligst med os ved at efterlade en kommentar.
Håber vi vil hjælpe dig.