I min tidligere artikel startede jeg en ny serie om låse ved at forklare, hvad de er, hvorfor de er nødvendige, og mekanikken i, hvordan de fungerer, og jeg anbefaler stærkt, at du læser artiklen før denne. I denne artikel vil jeg diskutere FGCB_ADD_REMOVE-låsen og vise, hvordan den kan være en flaskehals.
Hvad er FGCB_ADD_REMOVE-låsen?
De fleste låseklassenavne er knyttet direkte til den datastruktur, som de beskytter. FGCB_ADD_REMOVE-låsen beskytter en datastruktur kaldet en FGCB eller filgruppekontrolblok, og der vil være en af disse låse for hver online-filgruppe i hver online-database i en SQL Server-instans. Når en fil i en filgruppe tilføjes, droppes, vokser eller krympes, skal låsen anskaffes i EX-tilstand, og når man finder ud af den næste fil, der skal allokeres fra, skal låsen anskaffes i SH-tilstand for at forhindre filgruppeændringer. (Husk, at tildelinger til en filgruppe udføres på en round-robin basis gennem filerne i filgruppen, og tag også hensyn til proportional fill , som jeg forklarer her.)
Hvordan bliver låsen en flaskehals?
Det mest almindelige scenario, når denne lås bliver en flaskehals, er som følger:
- Der er en enkelt fildatabase, så alle tildelinger skal komme fra den ene datafil
- Autogrow-indstillingen for filen er indstillet til at være meget lille (husk, før SQL Server 2016 var standardindstillingen for autogrow for datafiler 1 MB!)
- Der er mange samtidige operationer, der kræver plads til at blive allokeret (f.eks. en konstant indsættelsesarbejdsbelastning fra mange klientforbindelser)
I dette tilfælde, selvom der kun er én fil, skal en tråd, der kræver en allokering, stadig erhverve FGCB_ADD_REMOVE-låsen i SH-tilstand. Den vil derefter forsøge at allokere fra den enkelte datafil, indse, at der ikke er plads, og derefter erhverve låsen i EX-tilstand, så den derefter kan vokse filen.
Lad os forestille os, at otte tråde, der kører på otte separate planlæggere, alle forsøger at allokere på samme tid, og alle indser, at der ikke er plads i filen, så de skal vokse den. De vil hver især forsøge at erhverve låsen i EX-tilstand. Kun én af dem vil være i stand til at erhverve den, og den vil fortsætte med at udvide filen, og de andre bliver nødt til at vente, med en ventetype på LATCH_EX og en ressourcebeskrivelse af FGCB_ADD_REMOVE plus hukommelsesadressen på låsen.
De syv ventende tråde er i låsens først-ind-først-ud (FIFO) ventekø. Når tråden, der udfører filvæksten, er færdig, frigiver den låsen og giver den til den første ventende tråd. Denne nye ejer af låsen går for at dyrke filen og opdager, at den allerede er blevet dyrket, og der ikke er noget at gøre. Så den udløser låsen og giver den til den næste ventende tråd. Og så videre.
De syv ventende tråde ventede alle på låsen i EX-tilstand, men endte med at gøre ingenting, når de fik låsen, så alle syv tråde spildte i det væsentlige forløbet tid, hvor mængden af tid, der blev spildt, steg en smule for hver tråd jo længere nede FIFO-ventekøen var det.
Viser flaskehalsen
Nu vil jeg vise dig det nøjagtige scenarie ovenfor ved hjælp af udvidede begivenheder. Jeg har oprettet en enkelt-fil database med en lille autogrow-indstilling, og hundredvis af samtidige forbindelser, der simpelthen indsætter data i en tabel.
Jeg kan bruge følgende udvidede begivenhedssession til at se, hvad der sker:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO Sessionen sporer, hvornår en tråd kommer ind i låsens ventekø, når den forlader køen (dvs. når den tildeles låsen), og når der sker en datafilvækst. Ved at bruge kausalitetssporing kan vi se en tidslinje over handlingerne for hver tråd.
Ved at bruge SQL Server Management Studio kan jeg vælge indstillingen Watch Live Data for den udvidede begivenhedssession og se al den udvidede begivenhedsaktivitet. Hvis du vil gøre det samme, skal du i Live Data-vinduet højreklikke på et af kolonnenavnene øverst og ændre de valgte kolonner til at være som nedenfor:
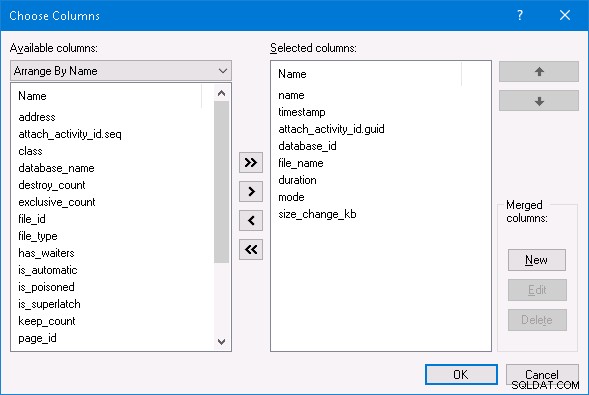
Jeg lod arbejdsbyrden køre i et par minutter for at nå en stabil tilstand og så et perfekt eksempel på det scenario, jeg beskrev ovenfor:
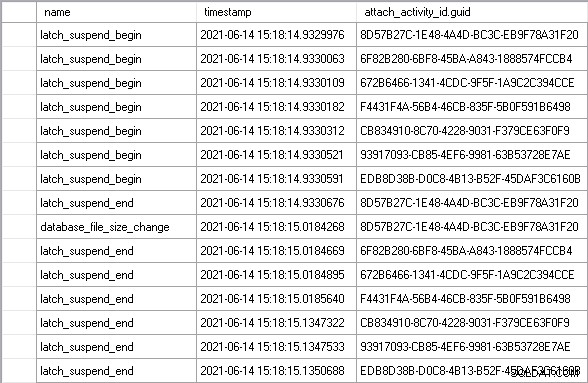
Brug af attach_activity_id.guid værdier for at identificere forskellige tråde, kan vi se, at syv tråde begynder at vente på låsen inden for 61,5 mikrosekunder. Tråden med GUID-værdien, der starter 8D57, henter låsen i EX-tilstand (latch_suspend_end hændelse) og derefter vokser filen straks (database_file_size_change begivenhed). 8D57-gevindet frigiver derefter låsen og giver den i EX-tilstand til 6F82-gevindet, som ventede i 85 millisekunder. Det har intet at gøre, så det giver låsen til 672B gevindet. Og så videre, indtil EDB8-tråden tildeles låsen, efter at have ventet i 202 millisekunder.
I alt ventede de seks tråde, der ventede uden grund, i næsten 1 sekund. Noget af den tid er signalventetid, hvor selvom tråden har fået tildelt låsen, skal den stadig bevæge sig op til toppen af skemalæggerens kørbare kø, før den kan komme ind på processoren og udføre kode. Du kan måske sige, at dette ikke er et rimeligt mål for tiden brugt på at vente på låsen, men det er det absolut, fordi signalventetiden ikke ville have været påløbet, hvis tråden ikke havde været nødt til at vente i første omgang.
Ydermere tror du måske, at en forsinkelse på 200 millisekunder ikke er så meget, men det hele afhænger af præstationsaftaler på serviceniveau for den pågældende arbejdsbyrde. Vi har flere højvolumenklienter, hvor hvis en batch tager mere end 200 millisekunder at udføre, er det ikke tilladt i produktionssystemet!
Oversigt
Hvis du overvåger ventetider på din server, og du bemærker, at LATCH_EX er en af de bedste ventetider, kan du bruge koden i dette indlæg, så se om FGCB_ADD_REMOVE er en af synderne.
Den nemmeste måde at sikre sig, at din arbejdsbyrde ikke rammer en FGCB_ADD_REMOVE flaskehals, er at sikre, at der ikke er nogen datafils autogrow-indstillinger, der er konfigureret ved hjælp af standardindstillingerne før SQL Server 2016. I sys.master_files visning, vil standarden på 1 MB blive vist som en datafil (type_desc kolonne sat til ROWS) med is_percent_growth kolonne sat til 0, og vækstkolonnen sat til 128.
At give en anbefaling for, hvad autogrow skal indstilles til at være, er en helt anden diskussion, men nu kender du til en potentiel præstationspåvirkning fra ikke at ændre standardindstillingerne i tidligere versioner.