Denne artikel udforsker nogle mindre kendte funktioner og begrænsninger for forespørgselsoptimering og forklarer årsagerne til ekstremt dårlig hash-join-ydeevne i et specifikt tilfælde.
Eksempel på data
Eksempeldataoprettelsesscriptet, der følger, er afhængigt af en eksisterende tabel med tal. Hvis du ikke allerede har en af disse, kan scriptet nedenfor bruges til at oprette et effektivt. Den resulterende tabel vil indeholde en enkelt heltalskolonne med tal fra én til én million:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
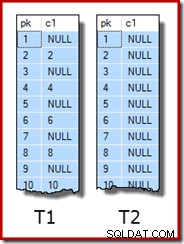
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Selve prøvedataene består af to tabeller, T1 og T2. Begge har en sekventiel heltals primær nøglekolonne ved navn pk og en anden nullbar kolonne ved navn c1. Tabel T1 har 600.000 rækker, hvor lige rækker har samme værdi for c1 som pk-kolonnen, og ulige rækker er nul. Tabel c2 har 32.000 rækker, hvor kolonne c1 er NULL i hver række. Følgende script opretter og udfylder disse tabeller:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; De første ti rækker af eksempeldata i hver tabel ser således ud:
Sammenslutning af de to borde
Denne første test involverer at forbinde de to tabeller i kolonne c1 (ikke pk-kolonnen) og returnere pk-værdien fra tabel T1 for rækker, der forbinder:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Forespørgslen returnerer faktisk ingen rækker, fordi kolonne c1 er NULL i alle rækker i tabel T2, så ingen rækker kan matche prædikatet equality join. Dette lyder måske som en mærkelig ting at gøre, men jeg er sikker på, at det er baseret på en ægte produktionsforespørgsel (meget forenklet for at lette diskussionen).
Bemærk, at dette tomme resultat ikke afhænger af indstillingen af ANSI_NULLS, fordi det kun styrer, hvordan sammenligninger med en null-literal eller variabel håndteres. Til kolonnesammenligninger afviser et lighedsprædikat altid nuller.
Udførelsesplanen for denne simple joinforespørgsel har nogle interessante funktioner. Vi vil først se på pre-execution ('estimeret') plan i SQL Sentry Plan Explorer:
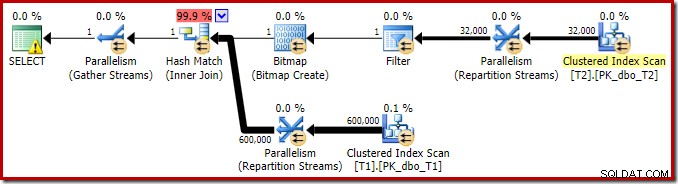
Advarslen på SELECT-ikonet klager bare over et manglende indeks i tabel T1 for kolonne c1 (med pk som en inkluderet kolonne). Indeksforslaget er irrelevant her.
Det første reelle emne af interesse i denne plan er filteret:
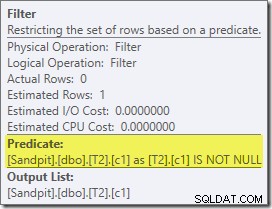
Dette ER IKKE NULL-prædikat vises ikke i kildeforespørgslen, selvom det er underforstået i join-prædikatet som tidligere nævnt. Det er interessant, at den er blevet brudt ud som en eksplicit ekstra operatør og placeret før sammenføjningen. Bemærk, at selv uden filteret ville forespørgslen stadig give korrekte resultater – selve joinforbindelsen ville stadig afvise nullerne.
Filteret er også nysgerrig af andre grunde. Den har en estimeret pris på præcis nul (selvom den forventes at fungere på 32.000 rækker), og den er ikke blevet skubbet ned i Clustered Index Scan som et resterende prædikat. Optimeringsværktøjet er normalt ret opsat på at gøre dette.
Begge disse ting forklares ved, at dette filter er introduceret i en omskrivning efter optimering. Når forespørgselsoptimeringsværktøjet har fuldført sin omkostningsbaserede behandling, er der et relativt lille antal faste planomskrivninger, der tages i betragtning. En af disse er ansvarlig for at introducere filteret.
Vi kan se output fra omkostningsbaseret planvalg (før omskrivningen) ved hjælp af udokumenterede sporingsflag 8607 og den velkendte 3604 til at dirigere tekstoutput til konsollen (meddelelsesfane i SSMS):
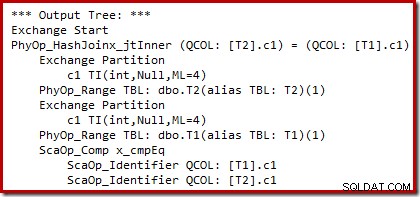
Outputtræet viser en hash-join, to scanninger og nogle parallelisme (udvekslings-) operatorer. Der er ikke noget nul-afvisende filter på c1-kolonnen i tabel T2.
Den særlige omskrivning efter optimering ser udelukkende på build-input af en hash-join. Afhængigt af dens vurdering af situationen kan den tilføje et eksplicit filter for at afvise rækker, der er nul i joinnøglen. Effekten af filteret på estimerede rækkeantal er også skrevet ind i udførelsesplanen, men fordi omkostningsbaseret optimering allerede er gennemført, beregnes der ikke en omkostning for filteret. Hvis det ikke er indlysende, er beregningsomkostninger spild af kræfter, hvis alle omkostningsbaserede beslutninger allerede er truffet.
Filteret forbliver direkte på build-inputtet i stedet for at blive skubbet ned i Clustered Index Scan, fordi hovedoptimeringsaktiviteten er afsluttet. Omskrivningerne efter optimering er faktisk justeringer i sidste øjeblik til en gennemført eksekveringsplan.
En anden og ganske adskilt omskrivning efter optimering er ansvarlig for Bitmap-operatøren i den endelige plan (du har måske bemærket, at den også manglede fra 8607-outputtet):
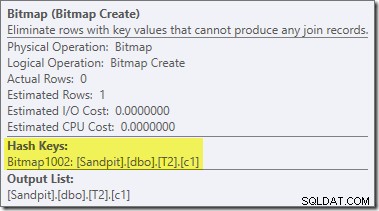
Denne operatør har også en estimeret pris på nul for både I/O og CPU. Den anden ting, der identificerer den som en operatør introduceret af en sen tweak (i stedet for under omkostningsbaseret optimering), er, at dens navn er Bitmap efterfulgt af et tal. Der er andre typer bitmaps introduceret under omkostningsbaseret optimering, som vi vil se lidt senere.
Indtil videre er det vigtige ved dette bitmap, at det registrerer c1-værdier set under opbygningsfasen af hash-join. Det færdige bitmap skubbes til probesiden af joinforbindelsen, når hashen går fra byggefase til probefase. Bitmap'et bruges til at udføre tidlig semi-join-reduktion, hvilket eliminerer rækker fra probesiden, som umuligt kan forbindes. hvis du har brug for flere detaljer om dette, se venligst min tidligere artikel om emnet.
Den anden effekt af bitmap kan ses på probe-side Clustered Index Scan:
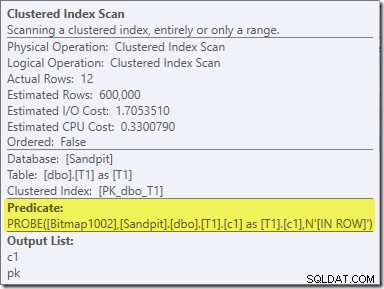
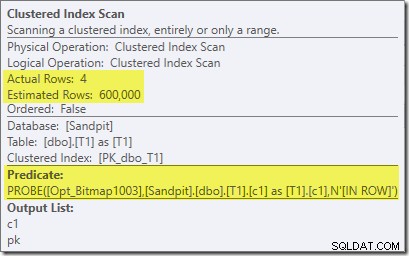
Skærmbilledet ovenfor viser det færdige bitmap, der kontrolleres som en del af Clustered Index Scan på tabel T1. Da kildekolonnen er et heltal (en bigint ville også fungere), skubbes bitmapkontrollen helt ind i lagermotoren (som angivet af 'INROW'-kvalifikationen) i stedet for at blive kontrolleret af forespørgselsprocessoren. Mere generelt kan bitmappet anvendes på en hvilken som helst operatør på sondesiden, fra centralen og ned. Hvor langt forespørgselsprocessoren kan skubbe bitmappet afhænger af kolonnetypen og versionen af SQL Server.
For at fuldføre analysen af de vigtigste funktioner i denne eksekveringsplan, er vi nødt til at se på planen efter udførelse ('faktisk'):
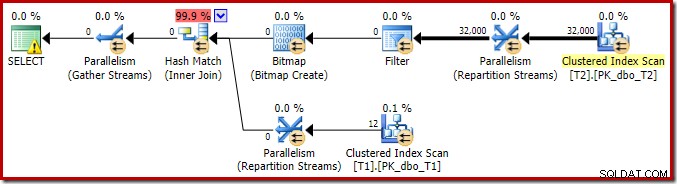
Den første ting at bemærke er fordelingen af rækker på tværs af tråde mellem T2-scanningen og Repartition Streams-udvekslingen umiddelbart over den. Ved en testkørsel så jeg følgende distribution på et system med fire logiske processorer:
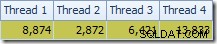
Fordelingen er ikke særlig jævn, som det ofte er tilfældet ved en parallel scanning på et relativt lille antal rækker, men i det mindste fik alle tråde noget arbejde. Trådfordelingen mellem den samme Repartition Streams-udveksling og filteret er meget forskellig:
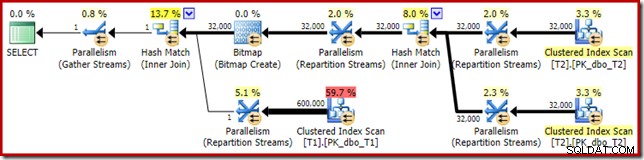
Dette viser, at alle 32.000 rækker fra tabel T2 blev behandlet af en enkelt tråd. For at se hvorfor, er vi nødt til at se på bytteejendommene:

Denne udveksling, ligesom den på sondesiden af hash-joinet, skal sikre, at rækker med de samme join-nøgleværdier ender i den samme forekomst af hash-joinet. På DOP 4 er der fire hash-joins, hver med sin egen hash-tabel. For korrekte resultater skal byggesiderækker og probesiderækker med de samme joinnøgler nå frem til den samme hash join; ellers kan vi kontrollere en række på sondesiden mod den forkerte hash-tabel.
I en parallelplan i rækketilstand opnår SQL Server dette ved at ompartitionere begge input ved hjælp af den samme hash-funktion på join-kolonnerne. I det foreliggende tilfælde er joinforbindelsen på kolonne c1, så inputs fordeles på tværs af tråde ved at anvende en hash-funktion (partitioneringstype:hash) til joinnøglekolonnen (c1). Problemet her er, at kolonne c1 kun indeholder en enkelt værdi – null – i tabel T2, så alle 32.000 rækker får samme hash-værdi, da alle ender på den samme tråd.
Den gode nyhed er, at intet af dette virkelig betyder noget for denne forespørgsel. Efter-optimerings-omskrivningsfilteret eliminerer alle rækker, før der er gjort meget arbejde. På min bærbare computer udføres forespørgslen ovenfor (som forventet uden resultater) på omkring 70 ms .
Samling af tre borde
Til den anden test tilføjer vi en ekstra join fra tabel T2 til sig selv på dens primære nøgle:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Dette ændrer ikke de logiske resultater af forespørgslen, men det ændrer eksekveringsplanen:
Som forventet har selvforbindelsen af tabel T2 på dens primære nøgle ingen indflydelse på antallet af rækker, der kvalificerer sig fra den tabel:
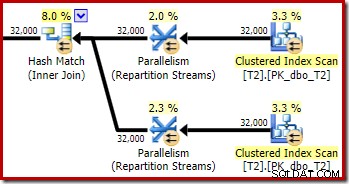
Fordelingen af rækker på tværs af tråde er også god i dette planafsnit. For scanningerne ligner det før, fordi den parallelle scanning fordeler rækker til tråde efter behov. Udvekslingerne ompartitionerer baseret på en hash af join-nøglen, som er pk-kolonnen denne gang. I betragtning af intervallet af forskellige pk-værdier er den resulterende trådfordeling også meget jævn:
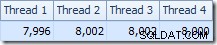
Når vi vender os til det mere interessante afsnit af den estimerede plan, er der nogle forskelle fra testen med to tabeller:

Endnu en gang ender udvekslingen på byggesiden med at dirigere alle rækker til den samme tråd, fordi c1 er sammenføjningsnøglen, og dermed partitioneringskolonnen for omfordelingsstrømme-udvekslingerne (husk, c1 er null for alle rækker i tabel T2).
Der er to andre vigtige forskelle i denne del af planen sammenlignet med den tidligere test. For det første er der ikke noget filter til at fjerne null-c1 rækker fra build-siden af hash join. Forklaringen på det er knyttet til den anden forskel - Bitmap'et er ændret, selvom det ikke er tydeligt fra billedet ovenfor:
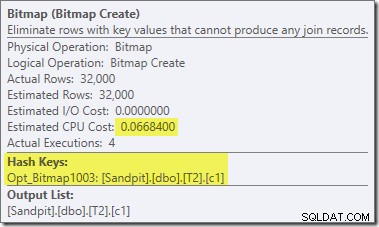
Dette er en Opt_Bitmap, ikke en bitmap. Forskellen er, at denne bitmap blev introduceret under omkostningsbaseret optimering, ikke ved en omskrivning i sidste øjeblik. Mekanismen, der tager hensyn til optimerede bitmaps, er forbundet med behandling af star-join-forespørgsler. Star-join-logikken kræver mindst tre sammenføjede tabeller, så dette forklarer, hvorfor en optimeret bitmap blev ikke taget i betragtning i eksemplet med to-tabeller.
Denne optimerede bitmap har en ikke-nul estimeret CPU-omkostning og påvirker direkte den overordnede plan valgt af optimeringsværktøjet. Dens effekt på probe-side-kardinalitetsestimatet kan ses hos Repartition Streams-operatøren:
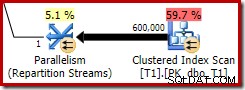
Bemærk kardinalitetseffekten ses ved udvekslingen, selvom bitmap'en til sidst skubbes helt ned i lagermotoren ('INROW'), ligesom vi så i den første test (men bemærk Opt_Bitmap-referencen nu):
Planen efter udførelse ('faktisk') er som følger:
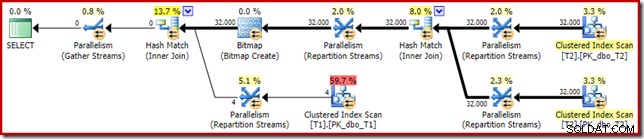
Den forudsagte effektivitet af den optimerede bitmap betyder, at den separate efter-optimerings-omskrivning for null-filteret ikke anvendes. Personligt synes jeg, at dette er uheldigt, fordi at eliminere nullerne tidligt med et filter ville ophæve behovet for at bygge bitmap, udfylde hash-tabellerne og udføre den bitmap-forbedrede scanning af tabel T1. Ikke desto mindre beslutter optimeringsværktøjet noget andet, og der er bare ingen diskussion med det i dette tilfælde.
På trods af den ekstra selvforbindelse af tabel T2 og det ekstra arbejde, der er forbundet med det manglende filter, producerer denne udførelsesplan stadig det forventede resultat (ingen rækker) på hurtig tid. En typisk udførelse på min bærbare computer tager omkring 200 ms .
Ændring af datatype
Til denne tredje test vil vi ændre datatypen for kolonne c1 i begge tabeller fra heltal til decimal. Der er ikke noget særligt ved dette valg; den samme effekt kan ses med enhver numerisk type, der ikke er heltal eller bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Genbrug af tre-join join-forespørgslen:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Den estimerede udførelsesplan ser meget bekendt ud:
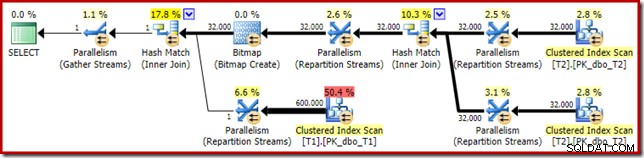
Bortset fra det faktum, at den optimerede bitmap ikke længere kan anvendes 'INROW' af lagermotoren på grund af ændringen af datatype, er eksekveringsplanen i det væsentlige identisk. Optagelsen nedenfor viser ændringen i scanningsegenskaber:
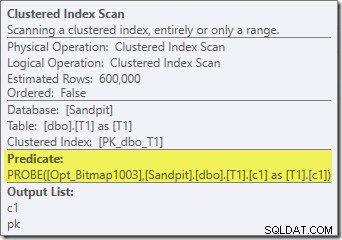
Desværre er præstationen ret dramatisk påvirket. Denne forespørgsel udføres ikke på 70 ms eller 200 ms, men på omkring 20 minutter . I testen, der producerede følgende plan efter udførelse, var køretiden faktisk 22 minutter og 29 sekunder:

Den mest åbenlyse forskel er, at Clustered Index Scan på tabel T1 returnerer 300.000 rækker, selv efter at det optimerede bitmapfilter er anvendt. Dette giver en vis mening, da bitmap'et er bygget på rækker, der kun indeholder nuller i c1-kolonnen. Bitmap'en fjerner rækker, der ikke er nul, fra T1-scanningen, og efterlader kun de 300.000 rækker med nulværdier for c1. Husk, at halvdelen af rækkerne i T1 er nul.
Alligevel virker det mærkeligt, at det tager over 20 minutter at forbinde 32.000 rækker med 300.000 rækker. Hvis du undrede dig, var én CPU-kerne fastgjort til 100 % for hele udførelsen. Forklaringen på denne dårlige ydeevne og ekstreme ressourceforbrug bygger på nogle ideer, vi udforskede tidligere:
Vi ved for eksempel allerede, at på trods af de parallelle udførelsesikoner ender alle rækker fra T2 på samme tråd. Som en påmindelse kræver rækketilstands parallelle hash-join genpartitionering på join-kolonnerne (c1). Alle rækker fra T2 har samme værdi – null – i kolonne c1, så alle rækker ender på samme tråd. På samme måde har alle rækker fra T1, der passerer bitmapfilteret, også null i kolonne c1, så de ompartitionerer også til den samme tråd. Dette forklarer, hvorfor en enkelt kerne gør alt arbejdet.
Det kan stadig virke urimeligt, at hash-sammenføjning af 32.000 rækker med 300.000 rækker skal tage 20 minutter, især da join-kolonnerne på begge sider er nul, og alligevel ikke vil deltage. For at forstå dette skal vi tænke over, hvordan denne hash-join fungerer.
Byg-inputtet (de 32.000 rækker) opretter en hash-tabel ved hjælp af join-kolonnen, c1. Da hver build-side række indeholder den samme værdi (null) for join kolonne c1, betyder det, at alle 32.000 rækker ender i den samme hash-bucket. Når hash-sammenføjningen skifter til sondering for kampe, hashes hver række på sondesiden med en null c1-kolonne også til den samme bucket. Hash-joinet skal derefter tjekke alle 32.000 poster i den bucket for en match.
Kontrol af de 300.000 sonderækker resulterer i 32.000 sammenligninger 300.000 gange. Dette er det værste tilfælde for en hash join:Alle byggede siderækker hash til den samme spand, hvilket resulterer i, hvad der i det væsentlige er et kartesisk produkt. Dette forklarer den lange eksekveringstid og konstante 100 % processorudnyttelse, da hashen følger den lange hash-bucket-kæde.
Denne dårlige ydeevne hjælper med at forklare, hvorfor omskrivningen efter optimering for at eliminere nuller på build-inputtet til en hash-join eksisterer. Det er uheldigt, at filteret ikke blev anvendt i dette tilfælde.
Løsninger
Optimizeren vælger denne planform, fordi den fejlagtigt estimerer, at den optimerede bitmap vil bortfiltrere alle rækkerne fra tabel T1. Selvom dette estimat vises ved Opdelingsstrømmene i stedet for det Clustered Index Scan, er dette stadig grundlaget for beslutningen. Som en påmindelse er her det relevante afsnit af præ-udførelsesplanen igen:
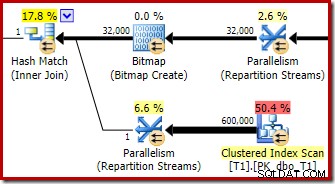
Hvis dette var et korrekt estimat, ville det ikke tage nogen tid overhovedet at behandle hash-sammenføjningen. Det er uheldigt, at selektivitetsestimatet for den optimerede bitmap er så meget forkert, når datatypen ikke er et simpelt heltal eller bigint. Det ser ud til, at en bitmap bygget på en heltals- eller bigint-nøgle også er i stand til at bortfiltrere null-rækker, der ikke kan tilsluttes. Hvis dette faktisk er tilfældet, er dette en væsentlig grund til at foretrække heltals- eller bigint-sammenføjningskolonner.
De følgende løsninger er i vid udstrækning baseret på ideen om at eliminere de problematiske optimerede bitmaps.
Seriel udførelse
En måde at forhindre, at optimerede bitmaps overvejes, er at kræve en ikke-parallel plan. Row-mode Bitmap-operatorer (optimerede eller på anden måde) ses kun i parallelle planer:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Denne forespørgsel er udtrykt ved hjælp af en lidt anden syntaks med et FORCE ORDER-tip for at generere en planform, der er lettere at sammenligne med de tidligere parallelle planer. Den væsentlige funktion er MAXDOP 1-tip.
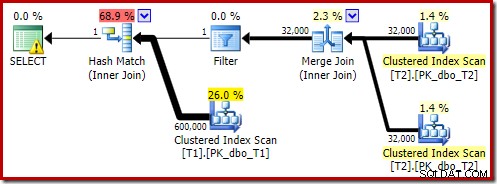
Den estimerede plan viser, at efter-optimerings-omskrivningsfilteret genindsættes:
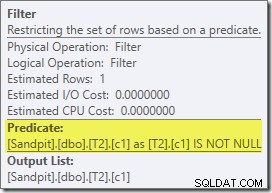
Efterudførelsesversionen af planen viser, at den filtrerer alle rækker fra build-inputtet, hvilket betyder, at sondesidescanningen kan springes over helt:
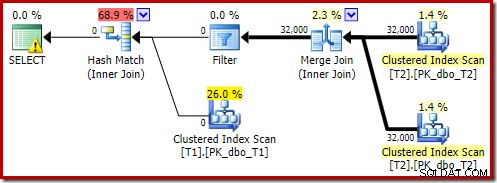
Som du ville forvente, udføres denne version af forespørgslen meget hurtigt - omkring 20 ms i gennemsnit for mig. Vi kan opnå en lignende effekt uden FORCE ORDER-tip og forespørgselsomskrivning:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
Optimizeren vælger en anden planform i dette tilfælde med filteret placeret direkte over scanningen af T2:
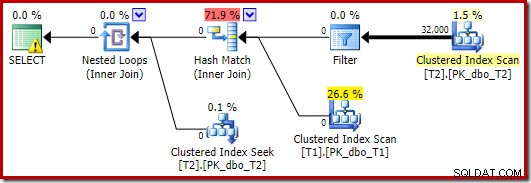
Dette udføres endnu hurtigere - på omkring 10 ms - som man kunne forvente. Dette ville naturligvis ikke være et godt valg, hvis antallet af tilstedeværende (og sammenføjelige) rækker var meget større.
Deaktivering af optimerede bitmaps
Der er ingen forespørgselstip til at slå optimerede bitmaps fra, men vi kan opnå den samme effekt ved at bruge et par udokumenterede sporingsflag. Som altid er dette kun for renteværdi; du ønsker aldrig at bruge disse i et rigtigt system eller program:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);>
Den resulterende eksekveringsplan er:
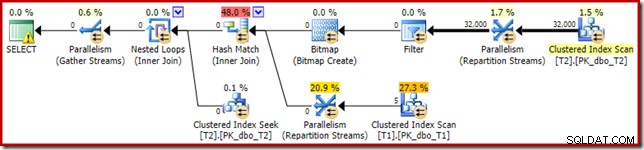
Bitmap'et der er en post-optimization rewrite bitmap, ikke en optimeret bitmap:
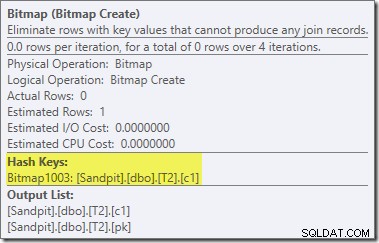
Bemærk nul-omkostningsestimaterne og Bitmap-navnet (i stedet for Opt_Bitmap). uden en optimeret bitmap til at skævvride omkostningsestimaterne, aktiveres omskrivningen efter optimering til at inkludere et nul-afvisende filter. Denne udførelsesplan kører på ca. 70 ms .
Den samme eksekveringsplan (med filter og ikke-optimeret bitmap) kan også produceres ved at deaktivere optimeringsreglen, der er ansvarlig for at generere star join bitmap-planer (igen, strengt udokumenteret og ikke til brug i den virkelige verden):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Inklusive et eksplicit filter
Dette er den enkleste mulighed, men man ville kun tænke på at gøre det, hvis man er opmærksom på de problemer, der er diskuteret indtil videre. Nu hvor vi ved, at vi skal eliminere null fra T2.c1, kan vi tilføje dette direkte til forespørgslen:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
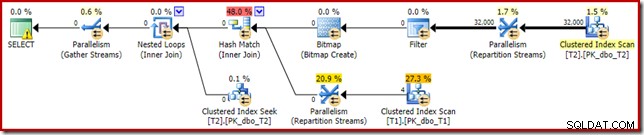
T2.c1 IS NOT NULL; -- New! Den resulterende estimerede udførelsesplan er måske ikke helt, hvad du kunne forvente:
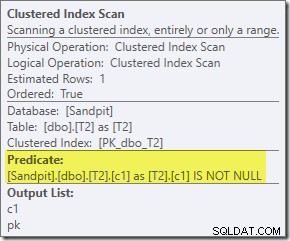
Det ekstra prædikat, vi tilføjede, er blevet skubbet ind i den midterste Clustered Index Scan af T2:
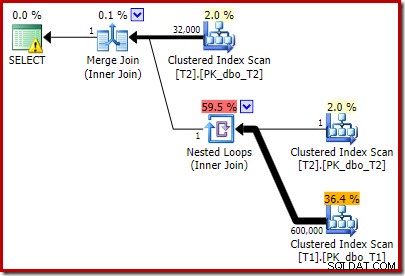
Efterudførelsesplanen er:
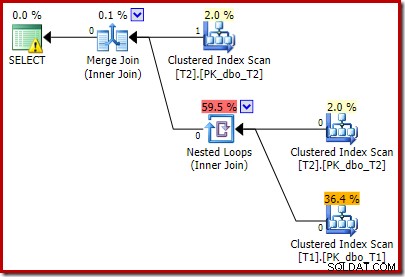
Bemærk, at Merge Join lukker ned efter at have læst en række fra dens øverste input, og derefter ikke kan finde en række på dens nederste input, på grund af effekten af det prædikat, vi tilføjede. Clustered Index Scan af tabel T1 udføres overhovedet ikke, fordi Nested Loops-sammenføjningen aldrig får en række på sit køreinput. Denne sidste forespørgselsform udføres på et eller to millisekunder.
Sidste tanker
Denne artikel har dækket en hel del jord til at udforske nogle mindre kendte forespørgselsoptimeringsadfærd og forklare årsagerne til ekstremt dårlig hash-join-ydeevne i et specifikt tilfælde.
Det kunne være fristende at spørge, hvorfor optimeringsværktøjet ikke rutinemæssigt tilføjer nul-afvisende filtre før ligestillings-tilslutninger. Man kan kun antage, at dette ikke ville være gavnligt i nok almindelige tilfælde. De fleste joinforbindelser forventes ikke at støde på mange null =null-afvisninger, og rutinemæssig tilføjelse af prædikater kan hurtigt blive kontraproduktivt, især hvis der er mange join-kolonner til stede. For de fleste joinforbindelser er det sandsynligvis en bedre mulighed (ud fra et omkostningsmodelperspektiv) at afvise nulværdier i joinoperatøren end at indføre et eksplicit filter.
Det ser ud til, at der er en indsats for at forhindre de allerværste tilfælde i at manifestere sig gennem omskrivningen efter optimering, der er designet til at afvise rækker med null join, før de når build-input af en hash join. Det ser ud til, at der eksisterer en uheldig interaktion mellem effekten af optimerede bitmapfiltre og anvendelsen af denne omskrivning. Det er også uheldigt, at når dette præstationsproblem opstår, er det meget svært at diagnosticere ud fra eksekveringsplanen alene.
Indtil videre ser den bedste mulighed ud til at være opmærksom på dette potentielle præstationsproblem med hash-join på nullbare kolonner, og tilføje eksplicitte nul-afvisende prædikater (med en kommentar!) for at sikre, at der produceres en effektiv eksekveringsplan, hvis det er nødvendigt. Brug af et MAXDOP 1-tip kan også afsløre en alternativ plan med kontrollampefilteret til stede.
Som en generel regel har forespørgsler, der slutter sig til kolonner af heltaltype og leder efter data, der findes, en tendens til at passe bedre til optimeringsmodellen og udførelsesmotorens muligheder end alternativerne.
Anerkendelser
Jeg vil gerne takke SQL_Sasquatch (@sqL_handLe) for hans tilladelse til at svare på hans originale artikel med en teknisk analyse. Eksempeldataene, der bruges her, er stærkt baseret på den artikel.
Jeg vil også gerne takke Rob Farley (blog | twitter) for vores tekniske diskussioner gennem årene, og især en i januar 2015, hvor vi diskuterede implikationerne af ekstra nul-afvisende prædikater for equi-joins. Rob har skrevet om relaterede emner adskillige gange, herunder i omvendte prædikater – se begge veje, før du krydser.