Denne artikel er den tredje del i en serie om NULL-kompleksiteter. I del 1 dækkede jeg betydningen af NULL-markøren og hvordan den opfører sig i sammenligninger. I del 2 beskrev jeg NULL-behandlingens uoverensstemmelser i forskellige sprogelementer. I denne måned beskriver jeg kraftfulde standard NULL-håndteringsfunktioner, der endnu ikke er nået til T-SQL, og de løsninger, som folk i øjeblikket bruger.
Jeg fortsætter med at bruge prøvedatabasen TSQLV5 som sidste måned i nogle af mine eksempler. Du kan finde scriptet, der opretter og udfylder denne database her, og dets ER-diagram her.
DISTINCT prædikat
I del 1 i serien forklarede jeg, hvordan NULL'er opfører sig i sammenligninger og kompleksiteten omkring den tre-værdiprædikatlogik, som SQL og T-SQL anvender. Overvej følgende prædikat:
X =YHvis et prædikant er NULL - inklusive når begge er NULL - er resultatet af dette prædikat den logiske værdi UKENDT. Med undtagelse af operatorerne IS NULL og IS NOT NULL, gælder det samme for alle andre operatorer, inklusive anderledes end (<>):
X <> YOfte i praksis ønsker man, at NULL'er skal opføre sig ligesom ikke-NULL-værdier til sammenligningsformål. Det er især tilfældet, når du bruger dem til at repræsentere manglende, men uanvendelige værdier. Standarden har en løsning til dette behov i form af en funktion kaldet DISTINCT prædikatet, som bruger følgende form:
I stedet for at bruge ligheds- eller ulighedssemantik, bruger dette prædikat distinktitetsbaseret semantik, når man sammenligner prædikander. Som et alternativ til en lighedsoperator (=), vil du bruge følgende formular til at få en SAND, når de to prædikander er ens, inklusive når begge er NULL, og en FALSK, når de ikke er det, inklusive når den ene er NULL og andet er ikke:
X ER IKKE FORSKELLENDE FRA YSom et alternativ til en anden end operator (<>), vil du bruge følgende form til at få en TRUE, når de to prædikander er forskellige, inklusive når den ene er NULL, og den anden ikke er, og en FALSE, når de er ens, inklusive når begge er NULL:
X ER FORSKELLIG FRA YLad os anvende DISTINCT-prædikatet på de eksempler, vi brugte i del 1 i serien. Husk, at du skulle skrive en forespørgsel, der givet en inputparameter @dt returnerer ordrer, der blev afsendt på inputdatoen, hvis den ikke er NULL, eller som slet ikke blev afsendt, hvis inputtet er NULL. I henhold til standarden vil du bruge følgende kode med DISTINCT-prædikatet til at håndtere dette behov:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
Indtil videre husker du fra del 1, at du kan bruge en kombination af EXISTS-prædikatet og INTERSECT-operatoren som en SARG-bar løsning i T-SQL, sådan:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
For at returnere ordrer, der blev afsendt på en anden dato end (adskilt fra) inputdatoen @dt, skal du bruge følgende forespørgsel:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
Løsningen, der virker i T-SQL, bruger en kombination af EXISTS-prædikatet og EXCEPT-operatoren, som sådan:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
I del 1 diskuterede jeg også scenarier, hvor du skal forbinde tabeller og anvende distinktitetsbaseret semantik i joinprædikatet. I mine eksempler brugte jeg tabeller kaldet T1 og T2, med NULLable join-kolonner kaldet k1, k2 og k3 på begge sider. I henhold til standarden vil du bruge følgende kode til at håndtere en sådan joinforbindelse:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
Lige nu kan du, i lighed med de tidligere filtreringsopgaver, bruge en kombination af EXISTS-prædikatet og INTERSECT-operatoren i joinets ON-klausul til at efterligne det distinkte prædikat i T-SQL, som sådan:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Når den bruges i et filter, kan denne formular SARG, og når den bruges i joins, kan denne formular muligvis stole på indeksrækkefølge.
Hvis du gerne vil se DISTINCT-prædikatet tilføjet til T-SQL, kan du stemme på det her.
Hvis du efter at have læst dette afsnit stadig føler dig en smule utryg ved DISTINCT-prædikatet, er du ikke alene. Måske er dette prædikat meget bedre end nogen eksisterende løsning, vi i øjeblikket har i T-SQL, men det er en smule udførligt og lidt forvirrende. Den bruger en negativ form til at anvende, hvad der i vores sind er en positiv sammenligning, og omvendt. Nå, ingen sagde, at alle standardforslagene er perfekte. Som Charlie bemærkede i en af sine kommentarer til del 1, ville følgende forenklede formular fungere bedre:
Det er kortfattet og meget mere intuitivt. I stedet for X ER IKKE FORSKELLIG FRA Y, ville du bruge:
X ER YOg i stedet for X ER FORSKELLIG FRA Y, ville du bruge:
X ER IKKE YDenne foreslåede operator er faktisk tilpasset de allerede eksisterende IS NULL og IS NOT NULL operatorer.
Anvendt på vores forespørgselsopgave, for at returnere ordrer, der blev afsendt på inputdatoen (eller som ikke blev afsendt, hvis input er NULL), ville du bruge følgende kode:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
For at returnere ordrer, der blev afsendt på en anden dato end inputdatoen, skal du bruge følgende kode:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Hvis Microsoft nogensinde beslutter sig for at tilføje det distinkte prædikat, ville det være godt, hvis de understøttede både standard verbose form og denne ikke-standard, endnu mere kortfattede og mere intuitive form. Mærkeligt nok understøtter SQL Servers forespørgselsprocessor allerede en intern sammenligningsoperator IS, som bruger samme semantik som den ønskede IS-operator, jeg beskrev her. Du kan finde detaljer om denne operatør i Paul Whites artikel Undocumented Query Plans:Equality Comparisons (opslag "IS i stedet for EQ"). Det, der mangler, er at eksponere det eksternt som en del af T-SQL.
NULL-behandlingsklausul (IGNOR NULLS | RESPECT NULLS)
Når du bruger offset-vinduets funktioner LAG, LEAD, FIRST_VALUE og LAST_VALUE, skal du nogle gange kontrollere NULL-behandlingsadfærden. Som standard returnerer disse funktioner resultatet af det anmodede udtryk i den anmodede position, uanset om resultatet af udtrykket er en faktisk værdi eller en NULL. Nogle gange vil du dog fortsætte med at bevæge dig i den relevante retning (tilbage for LAG og LAST_VALUE, fremad for LEAD og FIRST_VALUE), og returnere den første ikke-NULL-værdi, hvis den er til stede, og NULL ellers. Standarden giver dig kontrol over denne adfærd ved hjælp af en NULL-behandlingsklausul med følgende syntaks:
offset_function(Standarden i tilfælde af, at NULL-behandlingsklausulen ikke er angivet, er RESPECT NULLS-indstillingen, hvilket betyder at returnere alt, hvad der er til stede i den anmodede position, selvom NULL. Desværre er denne klausul endnu ikke tilgængelig i T-SQL. Jeg vil give eksempler på standardsyntaksen ved hjælp af LAG- og FIRST_VALUE-funktionerne, samt løsninger, der virker i T-SQL. Du kan bruge lignende teknikker, hvis du har brug for en sådan funktionalitet med LEAD og LAST_VALUE.
Som eksempeldata vil jeg bruge en tabel kaldet T4, som du opretter og udfylder ved hjælp af følgende kode:
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Der er en almindelig opgave, der involverer returnering af det sidste relevante værdi. En NULL i col1 indikerer ingen ændring i værdien, hvorimod en ikke-NULL værdi indikerer en ny relevant værdi. Du skal returnere den sidste ikke-NULL col1-værdi baseret på id-bestilling. Ved at bruge standard NULL-behandlingsklausulen ville du håndtere opgaven sådan:
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Her er det forventede output fra denne forespørgsel:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
Der er en løsning i T-SQL, men det involverer to lag af vinduesfunktioner og et tabeludtryk.
I det første trin bruger du MAX-vinduefunktionen til at beregne en kolonne kaldet grp, der har den maksimale id-værdi indtil videre, når col1 ikke er NULL, som sådan:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Denne kode genererer følgende output:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Som du kan se, oprettes der en unik grp-værdi, når der sker en ændring i col1-værdien.
I det andet trin definerer du en CTE baseret på forespørgslen fra det første trin. Derefter returnerer du i den ydre forespørgsel den maksimale col1-værdi indtil videre inden for hver partition defineret af grp. Det er den sidste ikke-NULL col1-værdi. Her er den komplette løsningskode:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; Det er klart, at det er meget mere kode og arbejde sammenlignet med bare at sige IGNORE_NULLS.
Et andet almindeligt behov er at returnere den første relevante værdi. I vores tilfælde, antag, at du skal returnere den første ikke-NULL col1-værdi indtil videre baseret på id-bestilling. Ved at bruge standard NULL-behandlingsklausulen ville du håndtere opgaven med FIRST_VALUE-funktionen og IGNORE NULLS-indstillingen, som sådan:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Her er det forventede output fra denne forespørgsel:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
Løsningen i T-SQL bruger en teknik, der ligner den, der blev brugt til den sidste ikke-NULL-værdi, kun i stedet for en dobbelt-MAX-tilgang, bruger du FIRST_VALUE-funktionen oven på en MIN-funktion.
I det første trin bruger du MIN-vinduefunktionen til at beregne en kolonne kaldet grp, der har den mindste id-værdi indtil videre, når col1 ikke er NULL, som sådan:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Denne kode genererer følgende output:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
Hvis der er NULL'er til stede før den første relevante værdi, ender du med to grupper - den første med NULL som grp-værdi og den anden med det første ikke-NULL-id som grp-værdi.
I det andet trin placerer du det første trins kode i et tabeludtryk. Så i den ydre forespørgsel bruger du FIRST_VALUE-funktionen, partitioneret af grp, til at indsamle den første relevante (ikke-NULL) værdi, hvis den er til stede, og NULL ellers, som sådan:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Igen, det er meget kode og arbejde sammenlignet med blot at bruge IGNORE_NULLS-indstillingen.
Hvis du føler, at denne funktion kan være nyttig for dig, kan du stemme for dens optagelse i T-SQL her.
ORDER AF NULLER FØRST | NULLER VARER
Når du bestiller data, hvad enten det er til præsentationsformål, vinduesvisning, TOP/OFFSET-FETCH-filtrering eller ethvert andet formål, er der spørgsmålet om, hvordan NULL'er skal opføre sig i denne sammenhæng? SQL-standarden siger, at NULL'er skal sortere sammen enten før eller efter ikke-NULL'er, og de overlader det til implementeringen at bestemme den ene eller den anden måde. Uanset hvad leverandøren vælger, skal det dog være konsekvent. I T-SQL ordnes NULL'er først (før ikke-NULL'er), når du bruger stigende rækkefølge. Overvej følgende forespørgsel som et eksempel:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Denne forespørgsel genererer følgende output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
Outputtet viser, at ikke-afsendte ordrer, som har en NULL afsendelsesdato, bestiller før afsendte ordrer, som har en eksisterende gældende afsendelsesdato.
Men hvad nu hvis du har brug for NULLs for at bestille sidst, når du bruger stigende rækkefølge? ISO/IEC SQL-standarden understøtter en klausul, som du anvender på et bestillingsudtryk, der kontrollerer, om NULLs rækkefølge først eller sidst. Syntaksen for denne klausul er:
For at håndtere vores behov, returnering af ordrer sorteret efter deres afsendelsesdatoer, stigende, men med ikke-afsendte ordrer returneret sidst, og derefter efter deres ordre-id'er som en tiebreaker, ville du bruge følgende kode:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Desværre er denne NULLS-bestillingsklausul ikke tilgængelig i T-SQL.
En almindelig løsning, folk bruger i T-SQL, er at gå foran rækkefølgeudtrykket med et CASE-udtryk, der returnerer en konstant med en lavere rækkefølgeværdi for ikke-NULL-værdier end for NULL-værdier, som sådan (vi kalder denne løsning forespørgsel 1):
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Denne forespørgsel genererer det ønskede output med NULL'er, der vises sidst:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
Der er et dækkende indeks defineret i Sales.Orders-tabellen med kolonnen shippeddate som nøglen. På samme måde som en manipuleret filtreringskolonne forhindrer filterets SARG-evne og muligheden for at anvende et søge et indeks, forhindrer en manipuleret bestillingskolonne muligheden for at stole på indeksbestilling til at understøtte forespørgslens ORDER BY-klausul. Derfor genererer SQL Server en plan for forespørgsel 1 med en eksplicit sorteringsoperator, som vist i figur 1.
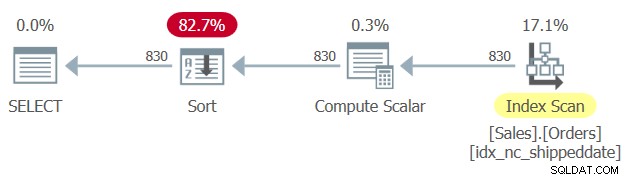 Figur 1:Plan for forespørgsel 1
Figur 1:Plan for forespørgsel 1
Nogle gange er størrelsen af dataene ikke så stor, at den eksplicitte sortering er et problem. Men nogle gange er det. Med eksplicit sortering bliver forespørgslens skalerbarhed ekstra-lineær (du betaler mere pr. række, jo flere rækker du har), og responstiden (tiden det tager den første række at blive returneret) er forsinket.
Der er et trick, som du kan bruge til at undgå eksplicit sortering i et sådant tilfælde med en løsning, der bliver optimeret ved hjælp af en ordrebevarende Merge Join Concatenation-operator. Du kan finde en detaljeret dækning af denne teknik, der anvendes i forskellige scenarier i SQL Server:Undgå en sortering med Merge Join-sammenkædning. Det første trin i løsningen forener resultaterne af to forespørgsler:en forespørgsel, der returnerer rækkerne, hvor rækkefølgekolonnen ikke er NULL med en resultatkolonne (vi kalder det sortcol) baseret på en konstant med en eller anden rækkefølgeværdi, f.eks. 0, og en anden forespørgsel, der returnerer rækkerne med NULL'erne, med sortcol sat til en konstant med en højere ordensværdi end i den første forespørgsel, f.eks. 1. I det andet trin definerer du så et tabeludtryk baseret på koden fra første trin, og derefter i den ydre forespørgsel bestiller du rækkerne fra tabeludtrykket først efter sortcol, og derefter efter de resterende bestillingselementer. Her er den komplette løsnings kode, der implementerer denne teknik (vi kalder denne løsning forespørgsel 2):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
Planen for denne forespørgsel er vist i figur 2.
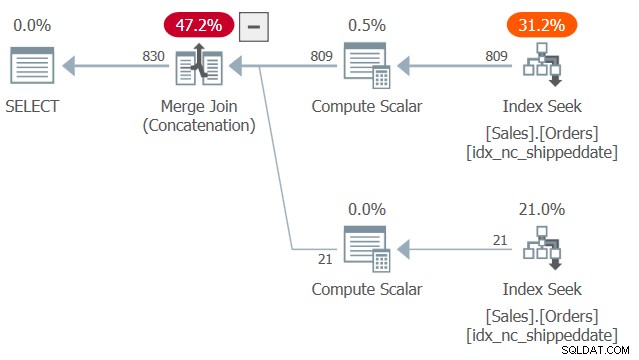 Figur 2:Plan for forespørgsel 2
Figur 2:Plan for forespørgsel 2
Læg mærke til to søgninger og bestilte rækkeviddescanninger i det dækkende indeks idx_nc_shippeddate – en trækker rækkerne, hvor shippeddateis ikke er NULL, og en anden trækker rækker, hvor shippeddate er NULL. Derefter, på samme måde som Merge Join-algoritmen fungerer i en joinforbindelse, forener Merge Join (Concatenation)-algoritmen rækkerne fra de to ordnede sider på en lynlås-lignende måde og bevarer den indlæste rækkefølge for at understøtte forespørgslens behov for præsentationsbestilling. Jeg siger ikke, at denne teknik altid er hurtigere end den mere typiske løsning med CASE-udtrykket, som anvender eksplicit sortering. Førstnævnte har dog lineær skalering, og sidstnævnte har n log n skalering. Så førstnævnte vil have en tendens til at klare sig bedre med et stort antal rækker og sidstnævnte med små tal.
Det er klart, at det er godt at have en løsning til dette almindelige behov, men det vil være meget bedre, hvis T-SQL tilføjede understøttelse af standard NULL-bestillingsklausulen i fremtiden.
Konklusion
ISO/IEC SQL-standarden har en hel del NULL-håndteringsfunktioner, som endnu ikke er nået til T-SQL. I denne artikel dækkede jeg nogle af dem:DISTINCT-prædikatet, NULL-behandlingsklausulen og kontrol af, om NULLs rækker først eller sidst. Jeg gav også løsninger til disse funktioner, der understøttes i T-SQL, men de er naturligvis besværlige. Næste måned fortsætter jeg diskussionen ved at dække den unikke standardbegrænsning, hvordan den adskiller sig fra T-SQL-implementeringen og de løsninger, der kan implementeres i T-SQL.