Denne artikel beskriver SQL-markører, og hvordan man bruger dem til nogle specielle formål. Det fremhæver vigtigheden af SQL-markører sammen med deres ulemper.
Det er ikke altid, at du bruger SQL-markør i databaseprogrammering, men deres konceptuelle forståelse og at lære at bruge dem hjælper meget til at forstå, hvordan man udfører exceptionelle opgaver i T-SQL-programmering.
SQL-markøroversigt
Lad os gennemgå nogle grundlæggende funktioner i SQL-markører, hvis du ikke er bekendt med dem.
Simpel definition
En SQL-markør giver adgang til data én række ad gangen og giver dig derved mere (række-for-række) kontrol over resultatsættet.
Microsoft Definition
Ifølge Microsofts dokumentation producerer Microsoft SQL Server-sætninger et komplet resultatsæt, men der er tidspunkter, hvor resultaterne bedst behandles én række ad gangen. Åbning af en markør på et resultatsæt gør det muligt at behandle resultatsættet en række ad gangen.
T-SQL og resultatsæt
Da både en simpel og Microsoft-definition af SQL-markøren nævner et resultatsæt, lad os prøve at forstå, hvad der præcist er resultatsættet i forbindelse med databaseprogrammering. Lad os hurtigt oprette og udfylde tabellen Studenter i en eksempeldatabase UniversityV3 som følger:
OPRET TABEL [dbo].[Student] ( [StudentId] INT IDENTITY (1, 1) IKKE NULL, [Navn] VARCHAR (30) NULL, [Kursus] VARCHAR (30) NULL, [Mærker] INT NULL, [Eksamensdato] DATETIME2 (7) NULL, BEGRÆNSNING [PK_Student] PRIMÆR NØGLE KLUSTERET ([StudentId] ASC));-- (5) Udfyld elevtabelSET IDENTITY_INSERT [dbo].[Student] ONINSERT INTO [dbo].[Student] ( [StudentId], [Navn], [Kursus], [Karakter], [ExamDate]) VÆRDIER (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00 ')INDSÆT I [dbo].[Student] ([StudentId], [Navn], [Kursus], [Karakter], [Eksamensdato]) VÆRDIER (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')INDSÆT I [dbo].[Student] ([StudentId], [Navn], [Kursus], [Karakter], [Eksamensdato]) VÆRDIER (3, N' Sam', N'Database Management System', 85, N'2016-01-01 00:00:00')INSERT INTO [dbo].[Student] ([StudentId], [Navn], [Kursus], [Marks ], [ExamDate]) VALUES (4, N'Adil', N'Database Management System', 85, N'2016-01-01 00:00:00 ')INDSÆT I [dbo].[Student] ([StudentId], [Navn], [Kursus], [Karakter], [Eksamensdato]) VÆRDIER (5, N'Naveed', N'Database Management System', 90, N'2016-01-01 00:00:00')SET IDENTITY_INSERT [dbo].[Student] FRA
Vælg nu alle rækkerne fra Elev tabel:
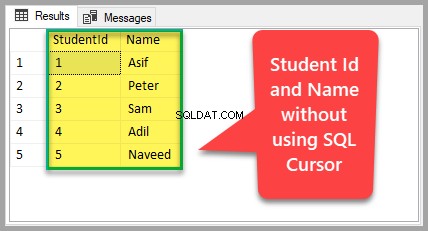
-- Se elevtabeldata VÆLG [StudentId], [Name], [Course], [Marks], [ExamDate] FROM dbo.Student
Dette er det resultatsæt, som returneres som et resultat af valg af alle posterne fra Student tabel.
T-SQL og mængdeteori
T-SQL er udelukkende baseret på følgende to matematiske begreber:
- Sammensætningsteori
- Prdikatlogik
Mængdelæren er, som navnet indikerer, en gren af matematikken om mængder, som også kan kaldes samlinger af bestemte distinkte objekter.
Kort sagt, i mængdeteorien tænker vi på ting eller objekter som en helhed på samme måde, som vi tænker på en individuel genstand.
For eksempel er eleven et sæt af alle de bestemte distinkte elever, så vi tager en elev som en helhed, hvilket er nok til at få detaljer om alle eleverne i det sæt (tabel).
Se venligst min artikel The Art of Aggregating Data in SQL from Simple to Sliding Aggregations for yderligere detaljer.
Markører og rækkebaserede operationer
T-SQL er primært designet til at udføre sæt-baserede operationer, såsom at vælge alle poster fra en tabel eller slette alle rækker fra en tabel.
Kort sagt, T-SQL er specielt designet til at arbejde med tabeller på en sæt-baseret måde, hvilket betyder, at vi tænker på en tabel som en helhed, og enhver handling som f.eks. vælge, opdatere eller slette anvendes som en helhed på tabellen eller visse rækker, der opfylder kriterierne.
Der er dog tilfælde, hvor tabeller skal tilgås række for række i stedet for som et enkelt resultatsæt, og det er her, markører træder i kraft.
Ifølge Vaidehi Pandere skal applikationslogik nogle gange arbejde med én række ad gangen i stedet for alle rækkerne på én gang, hvilket er det samme som looping (brug af loops til at iterere) gennem hele resultatsættet.
Grundlæggende om SQL-markører med eksempler
Lad os nu diskutere mere om SQL-markører.
Først og fremmest, lad os lære eller gennemgå (dem, der allerede er bekendt med at bruge markører i T-SQL), hvordan man bruger markøren i T-SQL.
Brug af SQL-markøren er en fem-trins proces, der udtrykkes som følger:
- Erklær markør
- Åbn markør
- Hent rækker
- Luk markør
- Deallokér markør
Trin 1:Erklær markør
Det første trin er at erklære SQL-markøren, så den kan bruges efterfølgende.
SQL-markøren kan erklæres som følger:
DECLARE Cursorfor
Trin 2:Åbn markøren
Det næste trin efter erklæringen er at åbne markøren, hvilket betyder at udfylde markøren med resultatsættet, som udtrykkes som følger:
Åbn
Trin 3:Hent rækker
Når markøren er erklæret og åbnet, er næste trin at begynde at hente rækker fra SQL-markøren én efter én, så hent rækker får den næste tilgængelige række fra SQL-markøren:
Hent næste fra
Trin 4:Luk markør
Når rækkerne er hentet én efter én og manipuleret efter krav, er næste trin at lukke SQL-markøren.
Lukning af SQL-markøren udfører tre opgaver:
- Frigiver det resultatsæt, der i øjeblikket holdes af markøren
- Frigør eventuelle markørlåse på rækkerne ved markøren
- Lukker den åbne markør
Den enkle syntaks til at lukke markøren er som følger:
Luk
Trin 5:Tildel markør
Det sidste trin i denne henseende er at deallokere markøren, som fjerner markørreferencen.
Syntaksen er som følger:
DEALLOCATE
SQL-markørkompatibilitet
Ifølge Microsofts dokumentation er SQL-markører kompatible med følgende versioner:
- SQL Server 2008 og nyere versioner
- Azure SQL-database
SQL markør eksempel 1:
Nu hvor vi er bekendt med de involverede trin til implementering af SQL-markør, lad os se på et simpelt eksempel på brug af SQL-markør:
-- Declare Student cursor example 1USE UniversityV3GODECLARE Student_Cursor CURSOR FOR SELECT StudentId ,[Name]FROM dbo.Student;OPEN Student_CursorFETCH NEXT FROM Student_CursorWHILE @@FETCH_STATUS =0BEGINFETCH NEXTorCurCorCorCorCorCorCor Student StudentOutputtet er som følger:
SQL markør eksempel 2:
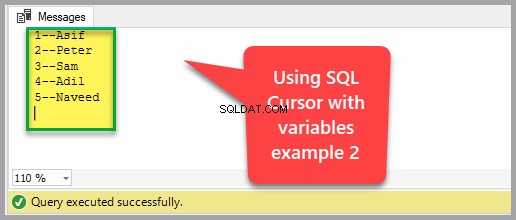
I dette eksempel skal vi bruge to variabler til at gemme de data, som markøren holder, når den bevæger sig fra række til række, så vi kan vise resultatsættet en række ad gangen ved at vise variablernes værdier.
-- Erklære Student cursor med variabler eksempel 2USE UniversityV3GODECLARE @StudentId INT ,@StudentName VARCHAR(40) -- Erklære variabler til at holde rækkedata holdt af cursorDECLARE Student_Cursor CURSOR FOR SELECT StudentId ,[Name]FROM dboOPFETCHenStuden NÆSTE FRA Student_Cursor INTO @StudentId, @StudentName -- Hent første række og gem den i variabler WHILE @@FETCH_STATUS =0BEGIN PRINT CONCAT(@StudentId,'--', @StudentName) -- Vis variable dataFETCH NEXT FROM Student_Crowursor data i markøren og gem dem i variablerINTO @StudentId, @StudentNameENDCLOSE Student_Cursor -- Luk markørlåse på rækkerneDEALLOCATE Student_Cursor -- Slip markørreferenceResultatet af ovenstående SQL-kode er som følger:
Man vil hævde, at vi kan opnå det samme output ved at bruge simpelt SQL-script som følger:
-- Viser elev-id og navn uden SQL cursorSELECT StudentId,Name FROM dbo.Studentorder by StudentId
Faktisk er der en del opgaver, som kræver SQL-markører for at blive brugt på trods af, at det frarådes at bruge SQL-markører på grund af deres direkte indvirkning på hukommelsen.
Vigtig bemærkning
Vær venligst opmærksom på, at ifølge Vaidehi Pandere er markører et hukommelsesbaseret sæt af pointere, så de optager din systemhukommelse, som ellers ville blive brugt af andre vigtige processer; derfor er det aldrig en god idé at krydse et stort resultatsæt gennem markører, medmindre der er en legitim grund til det.
Brug af SQL-markører til særlige formål
Vi vil gennemgå nogle specielle formål, som SQL-markører kan bruges til.
Databaseserverhukommelsestest
Da SQL-markører har en stor indvirkning på systemhukommelsen, er de gode kandidater til at replikere scenarier, hvor overdreven hukommelsesbrug af forskellige lagrede procedurer eller ad-hoc SQL-scripts skal undersøges.
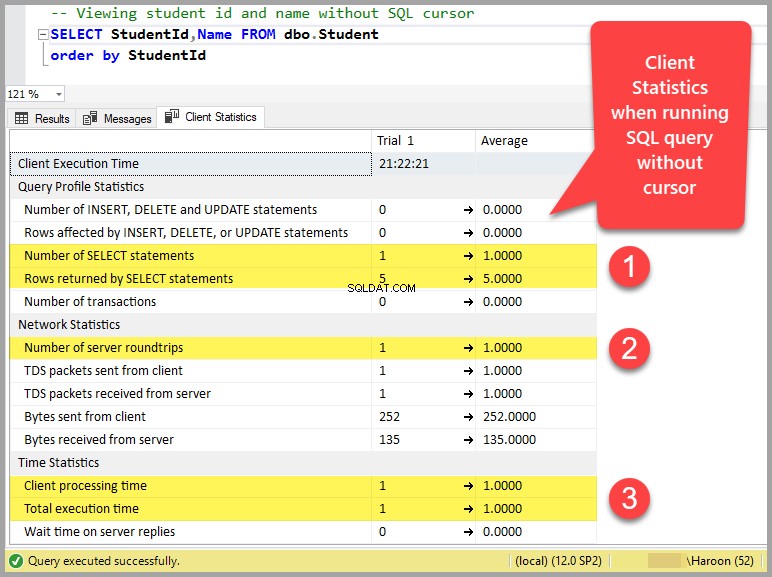
En enkel måde at forstå dette på er at klikke på klientstatistikknappen på værktøjslinjen (eller trykke på Shift+Alt+S) i SSMS (SQL Server Management Studio) og køre en simpel forespørgsel uden markør:
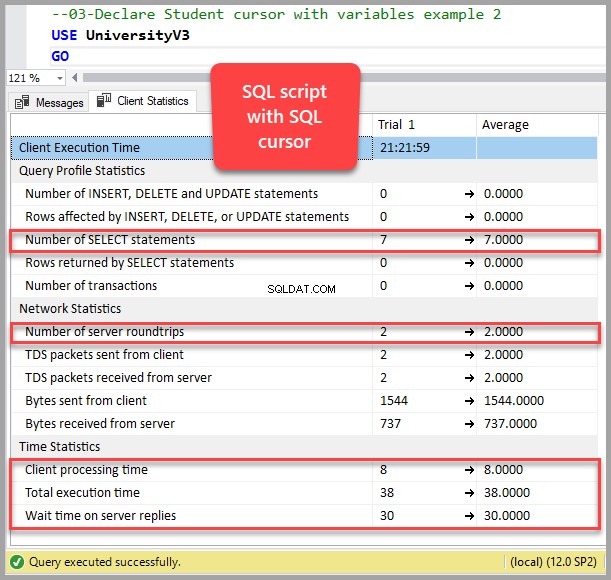
Kør nu forespørgslen med markøren ved hjælp af variabler (SQL Cursor Eksempel 2):
Bemærk nu forskellene:
Antal SELECT-sætninger uden markør:1
Antal SELECT-sætninger med markør:7
Antal server roundtrips uden markør:1
Antal server-rundture med markør:2
Klientbehandlingstid uden markør:1
Kundebehandlingstid med markør:8
Samlet udførelsestid uden markør:1
Samlet udførelsestid med markør:38
Ventetid på serversvar uden markør:0
Ventetid på serversvar med markør:30
Kort sagt, at køre forespørgslen uden markøren, som kun returnerer 5 rækker, kører den samme forespørgsel 6-7 gange med markøren.
Nu kan du forestille dig, hvor nemt det er at replikere hukommelsespåvirkning ved hjælp af markører, men dette er ikke altid den bedste ting at gøre.
Manipulationsopgaver i massedatabaseobjekter
Der er et andet område, hvor SQL-markører kan være praktiske, og det er, når vi skal udføre en masseoperation på databaser eller databaseobjekter.
For at forstå dette skal vi først oprette kursustabellen og udfylde den i UniversityV3 database som følger:
-- Opret kursustabel CREATE TABEL [dbo].[Kursus] ( [CourseId] INT IDENTITY (1, 1) NOT NULL, [Name] VARCHAR (30) NOT NULL, [Detaljer] VARCHAR (200) NULL, CONSTRAINT [PK_Course] PRIMÆR NØGLE KLUSTERET ([CourseId] ASC));-- Udfyld kursustabelSET IDENTITY_INSERT [dbo].[Course] ONINSERT INTO [dbo].[Course] ([CourseId], [Navn], [Detaljer]) VÆRDIER (1, N'DevOps for Databases', N'This is about DevOps for Databases')INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Power BI Fundamentals', N'Dette handler om Power BI Fundamentals')INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'T-SQL-programmering', N'About T-SQL-programmering')INSERT INTO [dbo].[Kursus] ([CourseId], [Navn], [Detaljer]) VÆRDIER (4, N'Tabular Data Modeling', N'Dette handler om tabelular Data Modeling')INSERT INTO [dbo].[Kursus] ([CourseId], [Navn], [Detaljer]) VALUES (5, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')SET IDENTITY_INSERT [dbo].[Kursus] FRAAntag nu, at vi vil omdøbe alle de eksisterende tabeller i UniversityV3 database som GAMLE tabeller.
Dette kræver cursor iteration over alle tabellerne én efter én, så de kan omdøbes.
Følgende kode klarer opgaven:
-- Erklær Student cursor for at omdøbe alle tabellerne som oldUSE UniversityV3GODECLARE @TableName VARCHAR(50) -- Eksisterende tabelnavn ,@NewTableName VARCHAR(50) -- Nyt tabelnavnDECLARE Student_Cursor CURSOR FOR SELECT T.TABLE_NAME FRA INFORMATIONSSCHEMA. T;OPEN Student_CursorFETCH NEXT FROM Student_Cursor INTO @TableNameWHILE @@FETCH_STATUS =0BEGINSET @example@sqldat.com+'_OLD' -- Tilføj _OLD til eksisterende navn på tableEXEC sp_rename @TableName,@NewTableName -- FXTROMETCH table as OLDCursor -- Hent næste række data i markøren og gem det i variabler INTO @TabelnavnENDCLOSE Student_Cursor -- Luk markørlåse på rækkerneDEALLOCATE Student_Cursor -- Slip markørreference
Tillykke, du har omdøbt alle de eksisterende tabeller ved hjælp af SQL-markøren.
Ting at gøre
Nu hvor du er fortrolig med brugen af SQL-markøren, prøv venligst følgende ting:
- Prøv venligst at oprette og omdøbe indekser for alle tabellerne i en prøvedatabase via markøren.
- Prøv venligst at vende de omdøbte tabeller i denne artikel tilbage til de oprindelige navne ved hjælp af markøren.
- Prøv venligst at udfylde tabeller med mange rækker og mål statistik og tid for forespørgslerne med og uden markøren.