Dette er fjerde del i en serie om løsninger på nummerseriegeneratorudfordringen. Mange tak til Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea og Paul White for at dele dine ideer og kommentarer.
Jeg elsker Paul Whites arbejde. Jeg bliver ved med at blive chokeret over hans opdagelser og undrer mig over, hvordan pokker han finder ud af, hvad han gør. Jeg elsker også hans effektive og veltalende skrivestil. Mens jeg læser hans artikler eller indlæg, ryster jeg ofte på hovedet og fortæller min kone, Lilach, at når jeg bliver voksen, vil jeg gerne være ligesom Paul.
Da jeg oprindeligt postede udfordringen, håbede jeg i al hemmelighed, at Paul ville sende en løsning. Jeg vidste, at hvis han gjorde det, ville det være en meget speciel en. Nå, det gjorde han, og det er fascinerende! Den har fremragende ydeevne, og der er ret meget, du kan lære af den. Denne artikel er dedikeret til Pauls løsning.
Jeg vil lave min test i tempdb, aktivere I/O og tidsstatistik:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME, IO ON;
Begrænsninger af tidligere ideer
Ved at evaluere tidligere løsninger var en af de vigtige faktorer for at opnå god ydeevne evnen til at anvende batchbehandling. Men har vi udnyttet det i størst muligt omfang?
Lad os undersøge planerne for to af de tidligere løsninger, der brugte batchbehandling. I del 1 dækkede jeg funktionen dbo.GetNumsAlanCharlieItzikBatch, som kombinerede ideer fra Alan, Charlie og mig selv.
Her er funktionens definition:
-- Helper dummy table
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
GO
-- Function definition
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Denne løsning definerer en basistabelværdikonstruktør med 16 rækker og en serie af kaskadende CTE'er med krydsforbindelser for at oppuste antallet af rækker til potentielt 4B. Løsningen bruger ROW_NUMBER-funktionen til at skabe grundsekvensen af tal i en CTE kaldet Nums, og TOP-filteret til at filtrere den ønskede talseriekardinalitet. For at aktivere batchbehandling bruger løsningen en dummy left join med en falsk betingelse mellem Nums CTE og en tabel kaldet dbo.BatchMe, som har et columnstore-indeks.
Brug følgende kode til at teste funktionen med variabeltildelingsteknikken:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Plan Explorer-afbildningen af den faktiske planen for denne udførelse er vist i figur 1.
 Figur 1:Plan for dbo.GetNumsAlanCharlieItzikBatch-funktionen
Figur 1:Plan for dbo.GetNumsAlanCharlieItzikBatch-funktionen
Når man analyserer batch-tilstand vs rækketilstandsbehandling, er det ret rart at kunne fortælle bare ved at se på en plan på et højt niveau, hvilken behandlingstilstand hver operatør brugte. Faktisk viser Plan Explorer en lyseblå batchfigur i nederste venstre del af operatøren, når dens faktiske udførelsestilstand er Batch. Som du kan se i figur 1, er den eneste operator, der brugte batch-tilstand, Window Aggregate-operatoren, som beregner rækkenumrene. Der er stadig meget arbejde udført af andre operatører i rækketilstand.
Her er præstationstallene, som jeg fik i min test:
CPU-tid =10032 ms, forløbet tid =10025 ms.logisk lyder 0
For at identificere hvilke operatører, der tog mest tid at udføre, skal du enten bruge muligheden Faktisk udførelsesplan i SSMS eller muligheden Hent faktisk plan i Plan Explorer. Sørg for at læse Pauls nylige artikel Understanding Execution Plan Operator Timings. Artiklen beskriver, hvordan man normaliserer de rapporterede operatørudførelsestider for at få de korrekte tal.
I planen i figur 1 bliver det meste af tiden brugt af de indlejrede sløjfer og øverste operatører længst til venstre, som begge udfører i rækketilstand. Udover at rækketilstand er mindre effektiv end batchtilstand til CPU-intensive operationer, skal du også huske på, at skift fra række til batch-tilstand og tilbage kræver ekstra omkostninger.
I del 2 dækkede jeg en anden løsning, der anvendte batchbehandling, implementeret i funktionen dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2. Denne løsning kombinerede ideer fra John Number2, Dave Mason, Joe Obbish, Alan, Charlie og mig selv. Den største forskel mellem den tidligere løsning og denne er, at som basisenhed bruger førstnævnte en virtuel tabelværdi-konstruktør, og sidstnævnte bruger en faktisk tabel med et kolonnelagerindeks, hvilket giver dig batchbehandling "gratis." Her er koden, der opretter tabellen og udfylder den ved hjælp af en INSERT-sætning med 102.400 rækker for at få den til at blive komprimeret:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Her er funktionens definition:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO En enkelt krydsforbindelse mellem to forekomster af basistabellen er tilstrækkelig til at producere langt ud over det ønskede potentiale for 4B rækker. Igen her bruger løsningen ROW_NUMBER-funktionen til at producere grundsekvensen af tal og TOP-filteret for at begrænse den ønskede talseriekardinalitet.
Her er koden til at teste funktionen ved hjælp af variabeltildelingsteknikken:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Planen for denne udførelse er vist i figur 2.
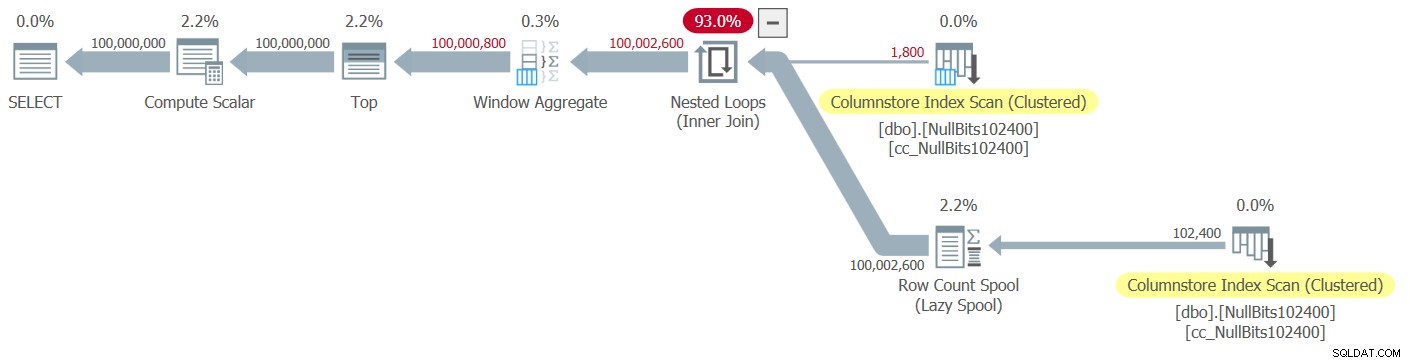 Figur 2:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2-funktionen
Figur 2:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2-funktionen
Bemærk, at kun to operatører i denne plan bruger batch-tilstand - den øverste scanning af tabellens clustered columnstore-indeks, som bruges som det ydre input af Nested Loops join, og Window Aggregate-operatoren, som bruges til at beregne basisrækkenumrene .
Jeg fik følgende præstationstal til min test:
CPU-tid =9812 ms, forløbet tid =9813 ms.Tabel 'NullBits102400'. Scanningsantal 2, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 8, lob fysisk læser 0, lob sideserver læser 0, lob læs- ahead læser 0, lob sideserver read-ahead læser 0.
Tabel 'NullBits102400'. Segment viser 2, segment sprunget over 0.
Igen bliver det meste af tiden i udførelsen af denne plan brugt af de Nested Loops og Top-operatører længst til venstre, som udfører i rækketilstand.
Pauls løsning
Inden jeg præsenterer Pauls løsning, vil jeg starte med min teori om den tankeproces, han gennemgik. Dette er faktisk en fantastisk læringsøvelse, og jeg foreslår, at du går den igennem, før du ser på løsningen. Paul genkendte de invaliderende virkninger af en plan, der blander både batch- og rækketilstande, og satte en udfordring for sig selv at komme med en løsning, der får en hel-batch-mode plan. Hvis det lykkes, er potentialet for, at en sådan løsning fungerer godt, ret højt. Det er bestemt spændende at se, om et sådant mål overhovedet er opnåeligt, da der stadig er mange operatører, der endnu ikke understøtter batch-tilstand og mange faktorer, der hæmmer batchbehandling. For eksempel, i skrivende stund er den eneste join-algoritme, der understøtter batch-behandling, hash join-algoritmen. En krydssammenføjning optimeres ved hjælp af den indlejrede sløjfer-algoritme. Desuden er Top-operatøren i øjeblikket kun implementeret i rækketilstand. Disse to elementer er kritiske grundlæggende elementer, der bruges i planerne for mange af de løsninger, som jeg har dækket indtil nu, inklusive de to ovenstående.
Hvis vi antager, at du gav udfordringen med at skabe en løsning med en hel-batch-mode-plan et anstændigt forsøg, så lad os fortsætte til den anden øvelse. Jeg vil først præsentere Pauls løsning, som han leverede den, med hans indlejrede kommentarer. Jeg vil også køre det for at sammenligne dets ydeevne med de andre løsninger. Jeg lærte en hel del ved at dekonstruere og rekonstruere hans løsning, et trin ad gangen, for at sikre, at jeg omhyggeligt forstod, hvorfor han brugte hver af de teknikker, han gjorde. Jeg vil foreslå, at du gør det samme, før du går videre til at læse mine forklaringer.
Her er Pauls løsning, som involverer en hjælpesøjlelagertabel kaldet dbo.CS og en funktion kaldet dbo.GetNums_SQLkiwi:
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scala
@low - 2 + N.rn < @high;
GO Her er koden, jeg brugte til at teste funktionen med variabeltildelingsteknikken:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000);
Jeg fik planen vist i figur 3 til min test.
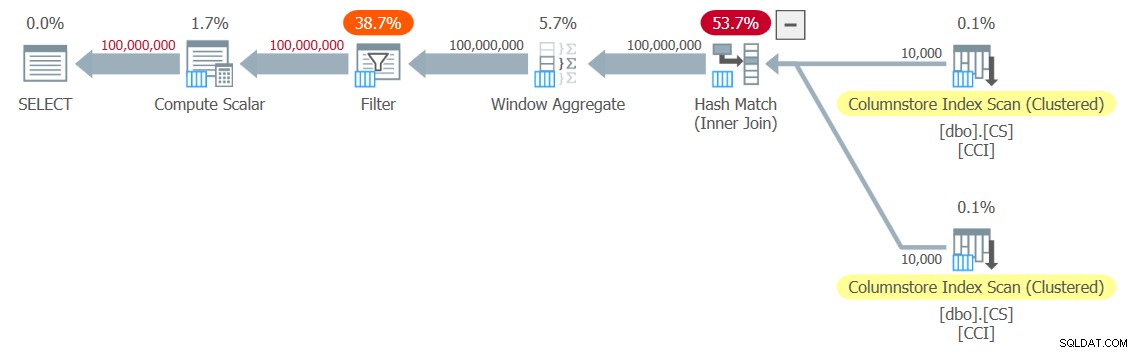 Figur 3:Plan for dbo.GetNums_SQLkiwi-funktionen
Figur 3:Plan for dbo.GetNums_SQLkiwi-funktionen
Det er en hel-batch-mode plan! Det er ret imponerende.
Her er de præstationstal, jeg fik for denne test på min maskine:
CPU-tid =7812 ms, forløbet tid =7876 ms.Tabel 'CS'. Scanningsantal 2, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 44, lob fysisk læser 0, lob sideserver læser 0, lob læs- ahead læser 0, lob sideserver read-ahead læser 0.
Tabel 'CS'. Segment viser 2, segment sprunget over 0.
Lad os også kontrollere, at hvis du skal returnere tallene sorteret efter n, er løsningen ordrebevarende med hensyn til rn - i hvert fald når du bruger konstanter som input - og undgår dermed eksplicit sortering i planen. Her er koden til at teste den med ordre:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
Du får den samme plan som i figur 3, og derfor lignende præstationstal:
CPU-tid =7765 ms, forløbet tid =7822 ms.Tabel 'CS'. Scanningsantal 2, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 44, lob fysisk læser 0, lob sideserver læser 0, lob læs- ahead læser 0, lob sideserver read-ahead læser 0.
Tabel 'CS'. Segment viser 2, segment sprunget over 0.
Det er en vigtig side af løsningen.
Ændring af vores testmetode
Pauls løsnings ydeevne er en anstændig forbedring i både forløbet tid og CPU-tid sammenlignet med de to tidligere løsninger, men det virker ikke som den mere dramatiske forbedring, man ville forvente af en all-batch-mode plan. Måske mangler vi noget?
Lad os prøve at analysere operatørens udførelsestid ved at se på den faktiske udførelsesplan i SSMS som vist i figur 4.
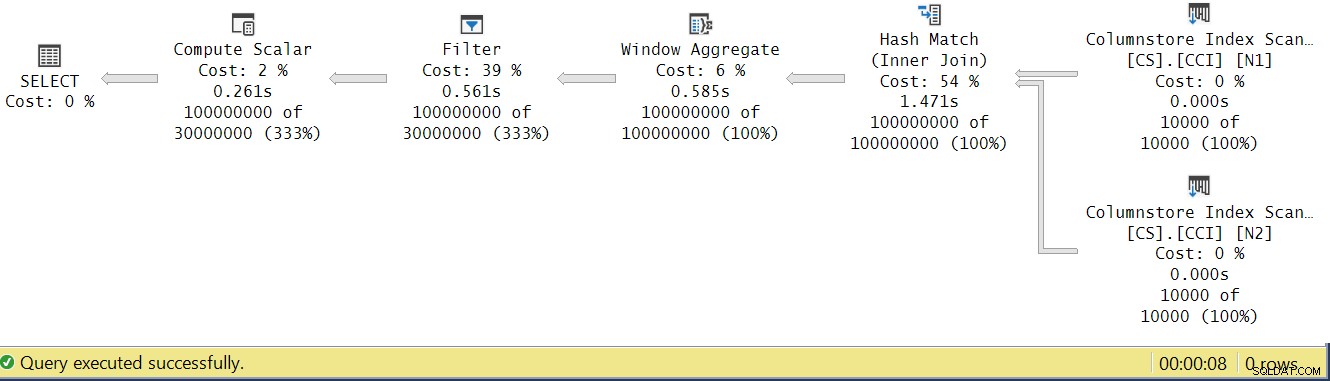 Figur 4:Operatør-udførelsestider for dbo.GetNums_SQLkiwi-funktionen
Figur 4:Operatør-udførelsestider for dbo.GetNums_SQLkiwi-funktionen
I Pauls artikel om analyse af operatørudførelsestider forklarer han, at med batch-mode operatører rapporterer hver sin egen eksekveringstid. Hvis du summerer udførelsestiderne for alle operatører i denne faktiske plan, får du 2.878 sekunder, men planen tog 7.876 at udføre. 5 sekunder af udførelsestiden ser ud til at mangle. Svaret på dette ligger i den testteknik, vi bruger, med variabeltildelingen. Husk, at vi besluttede at bruge denne teknik til at eliminere behovet for at sende alle rækker fra serveren til den, der ringer, og for at undgå de I/O'er, der ville være involveret i at skrive resultatet til en tabel. Det virkede som den perfekte mulighed. De sande omkostninger ved den variable tildeling er dog skjult i denne plan, og den udføres selvfølgelig i rækketilstand. Mysteriet løst.
I sidste ende er en god test naturligvis en test, der i tilstrækkelig grad afspejler din produktionsbrug af løsningen. Hvis du typisk skriver dataene til en tabel, skal din test afspejle det. Hvis du sender resultatet til den, der ringer, skal du bruge din test til at afspejle det. I hvert fald ser den variable tildeling ud til at repræsentere en stor del af udførelsestiden i vores test, og det er klart usandsynligt, at den repræsenterer typisk produktionsbrug af funktionen. Paul foreslog, at testen i stedet for variabel tildeling kunne anvende et simpelt aggregat som MAX på den returnerede talkolonne (n/rn/op). En aggregeret operatør kan bruge batchbehandling, så planen vil ikke involvere konvertering fra batch- til rækketilstand som følge af dens brug, og dens bidrag til den samlede kørselstid bør være ret lille og kendt.
Så lad os genteste alle tre løsninger, der er dækket i denne artikel. Her er koden til at teste funktionen dbo.GetNumsAlanCharlieItzikBatch:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Jeg fik planen vist i figur 5 for denne test.
 Figur 5:Plan for dbo.GetNumsAlanCharlieItzikBatch-funktion med aggregeret
Figur 5:Plan for dbo.GetNumsAlanCharlieItzikBatch-funktion med aggregeret
Her er de præstationstal, jeg fik for denne test:
CPU-tid =8469 ms, forløbet tid =8733 ms.logisk lyder 0
Bemærk, at køretiden faldt fra 10,025 sekunder ved brug af variabel tildelingsteknikken til 8,733 ved brug af den samlede teknik. Det er lidt over et sekund af udførelsestid, som vi kan tilskrive variabeltildelingen her.
Her er koden til at teste funktionen dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
SELECT MAX(n) AS mx FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Jeg fik planen vist i figur 6 for denne test.
 Figur 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2-funktion med aggregate
Figur 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2-funktion med aggregate
Her er de præstationstal, jeg fik for denne test:
CPU-tid =7031 ms, forløbet tid =7053 ms.Tabel 'NullBits102400'. Scanningsantal 2, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 8, lob fysisk læser 0, lob sideserver læser 0, lob læs- ahead læser 0, lob sideserver read-ahead læser 0.
Tabel 'NullBits102400'. Segment viser 2, segment sprunget over 0.
Bemærk, at køretiden faldt fra 9,813 sekunder ved brug af variabel tildelingsteknikken til 7,053 ved brug af den samlede teknik. Det er lidt over to sekunders eksekveringstid, som vi kan tilskrive variabeltildelingen her.
Og her er koden til at teste Pauls løsning:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Jeg får planen vist i figur 7 for denne test.
 Figur 7:Plan for dbo.GetNums_SQLkiwi-funktion med aggregat
Figur 7:Plan for dbo.GetNums_SQLkiwi-funktion med aggregat
Og nu til det store øjeblik. Jeg fik følgende præstationstal for denne test:
CPU-tid =3125 ms, forløbet tid =3149 ms.Tabel 'CS'. Scanningsantal 2, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 44, lob fysisk læser 0, lob sideserver læser 0, lob læs- ahead læser 0, lob sideserver read-ahead læser 0.
Tabel 'CS'. Segment viser 2, segment sprunget over 0.
Køretiden faldt fra 7,822 sekunder til 3,149 sekunder! Lad os undersøge operatørens udførelsestidspunkter i den faktiske plan i SSMS, som vist i figur 8.
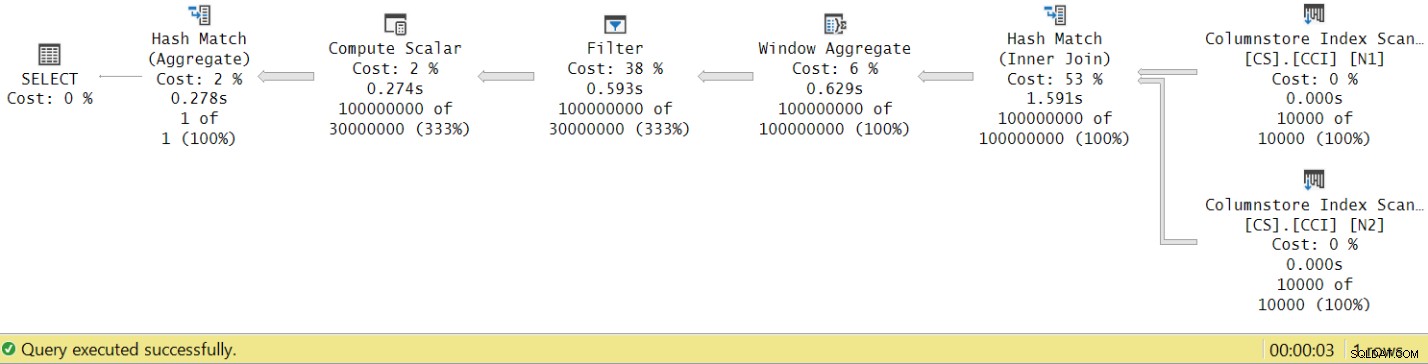 Figur 8:Operatørudførelsestider for dbo.GetNums-funktion med aggregat
Figur 8:Operatørudførelsestider for dbo.GetNums-funktion med aggregat
Hvis du nu akkumulerer de enkelte operatørers eksekveringstider, vil du få et antal svarende til den samlede planudførelsestid.
Figur 9 har en præstationssammenligning med hensyn til forløbet tid mellem de tre løsninger ved brug af både variabel tildeling og aggregerede testteknikker.
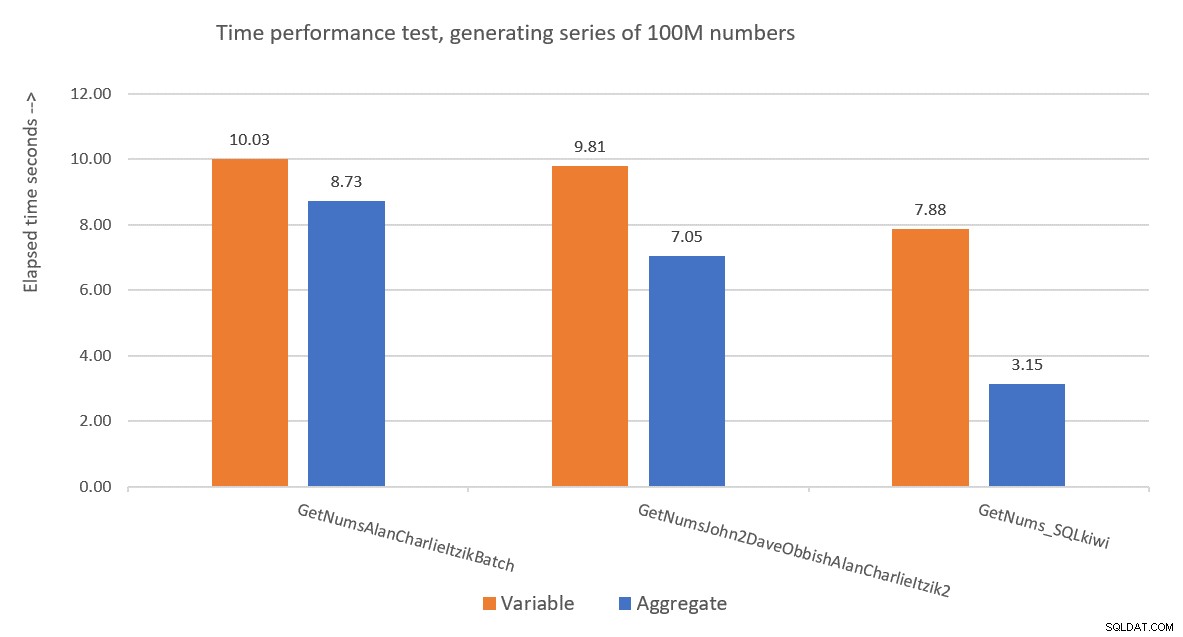 Figur 9:Præstationssammenligning
Figur 9:Præstationssammenligning
Pauls løsning er en klar vinder, og det er især tydeligt, når man bruger aggregattestteknikken. Hvilken imponerende bedrift!
Dekonstruktion og rekonstruktion af Pauls løsning
At dekonstruere og derefter rekonstruere Pauls løsning er en god øvelse, og du kommer til at lære meget, mens du gør det. Som foreslået tidligere, anbefaler jeg, at du selv gennemgår processen, før du fortsætter med at læse.
Det første valg, du skal foretage, er den teknik, du vil bruge til at generere det ønskede potentielle antal rækker af 4B. Paul valgte at bruge en kolonnelagertabel og udfylde den med lige så mange rækker som kvadratroden af det nødvendige antal, hvilket betyder 65.536 rækker, så du med en enkelt krydssammenføjning ville få det nødvendige antal. Måske tænker du, at med færre end 102.400 rækker ville du ikke få en komprimeret rækkegruppe, men dette gælder, når du udfylder tabellen med en INSERT-sætning, som vi gjorde med tabellen dbo.NullBits102400. Det gælder ikke, når du opretter et kolonnelagerindeks på en forududfyldt tabel. Så Paul brugte en SELECT INTO-sætning til at oprette og udfylde tabellen som en rækkelagerbaseret heap med 65.536 rækker og oprettede derefter et klynget kolonnelagerindeks, hvilket resulterede i en komprimeret rækkegruppe.
Den næste udfordring er at finde ud af, hvordan man får en krydssammenføjning til at blive behandlet med en batch-mode-operatør. Til dette skal join-algoritmen være hash. Husk, at en krydssammenføjning er optimeret ved hjælp af algoritmen for indlejrede sløjfer. Du skal på en eller anden måde narre optimeringsværktøjet til at tro, at du bruger en indre equijoin (hash kræver mindst ét lighedsbaseret prædikat), men få en cross join i praksis.
Et oplagt første forsøg er at bruge en indre joinforbindelse med et kunstigt joinprædikat, der altid er sandt, som sådan:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON 0 = 0; Men denne kode fejler med følgende fejl:
Msg 8622, Level 16, State 1, Line 246Forespørgselsprocessor kunne ikke producere en forespørgselsplan på grund af de tip, der er defineret i denne forespørgsel. Genindsend forespørgslen uden at angive nogen tip og uden at bruge SET FORCEPLAN.
SQL Servers optimizer genkender, at dette er et kunstigt indre join-prædikat, forenkler den indre join til en cross join og producerer en fejl, der siger, at den ikke kan imødekomme hint om at tvinge en hash join-algoritme.
For at løse dette oprettede Paul en INT NOT NULL-kolonne (mere om hvorfor denne specifikation snart) kaldet n1 i sin dbo.CS-tabel og udfyldte den med 0 i alle rækker. Han brugte derefter join-prædikatet N2.n1 =N1.n1, hvilket effektivt fik propositionen 0 =0 i alle matchevalueringer, mens han overholdt de minimale krav til en hash-join-algoritme.
Dette virker og producerer en plan for alle batchtilstande:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON N2.n1 = N1.n1; Hvad angår årsagen til, at n1 skal defineres som INT IKKE NULL; hvorfor ikke tillade NULLs, og hvorfor ikke bruge BIGINT? Årsagen til disse valg er at undgå en rest af hash-sonde (et ekstra filter, der anvendes af hash join-operatøren ud over det oprindelige join-prædikat), hvilket kan resultere i ekstra unødvendige omkostninger. Se Pauls artikel Join Performance, Implicit Conversions, and Residuals for detaljer. Her er den del af artiklen, der er relevant for os:
"Hvis joinforbindelsen er på en enkelt kolonne skrevet som tinyint, smallint eller heltal, og hvis begge kolonner er begrænset til IKKE NULL, er hash-funktionen 'perfekt' - hvilket betyder, at der ikke er nogen chance for en hash-kollision, og forespørgselsprocessoren behøver ikke at kontrollere værdierne igen for at sikre, at de virkelig stemmer overens.Bemærk, at denne optimering ikke gælder for store kolonner."
For at kontrollere dette aspekt, lad os oprette en anden tabel kaldet dbo.CS2 med en nullbar n1-kolonne:
DROP TABLE IF EXISTS dbo.CS2; SELECT * INTO dbo.CS2 FROM dbo.CS; ALTER TABLE dbo.CS2 ALTER COLUMN n1 INT NULL; CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS2 WITH (MAXDOP = 1);
Lad os først teste en forespørgsel mod dbo.CS (hvor n1 er defineret som INT IKKE NULL), generere 4B basisrækkenumre i en kolonne kaldet rn og anvende MAX-aggregatet til kolonnen:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
) AS N; Vi vil sammenligne planen for denne forespørgsel med planen for en lignende forespørgsel mod dbo.CS2 (hvor n1 er defineret som INT NULL):
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS2 AS N1
JOIN dbo.CS2 AS N2
ON N2.n1 = N1.n1
) AS N; Planerne for begge forespørgsler er vist i figur 10.
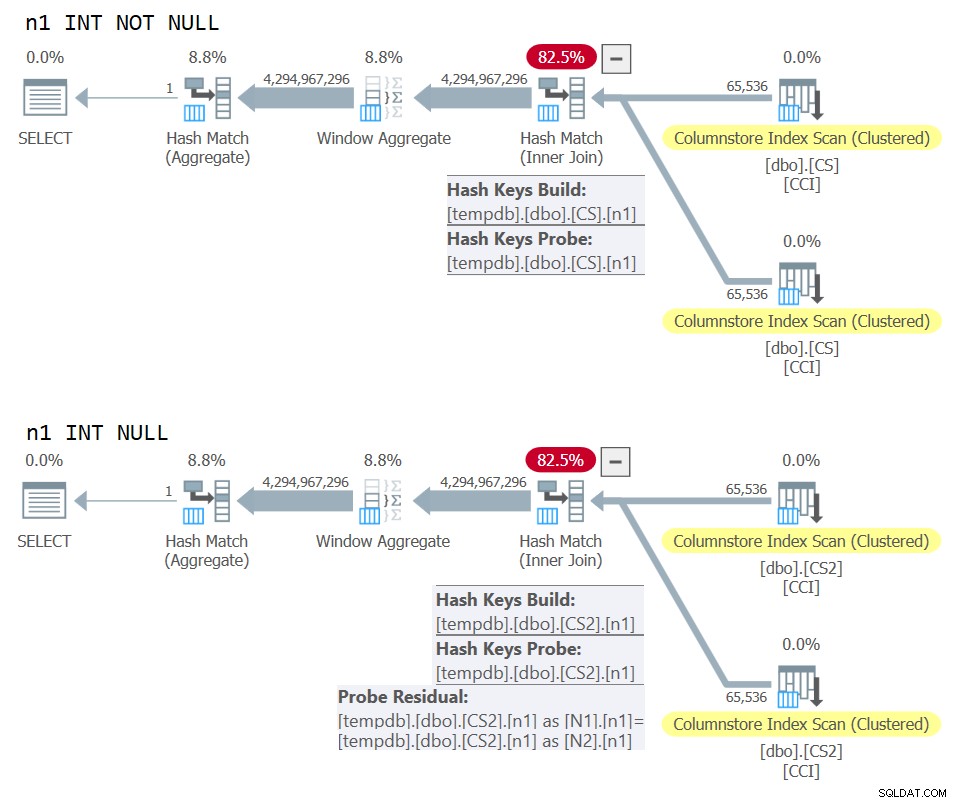 Figur 10:Plansammenligning for NOT NULL vs NULL joinnøgle
Figur 10:Plansammenligning for NOT NULL vs NULL joinnøgle
Du kan tydeligt se den ekstra sonderest, der er påført i den anden plan, men ikke den første.
På min maskine blev forespørgslen mod dbo.CS afsluttet på 91 sekunder, og forespørgslen mod dbo.CS2 gennemført på 92 sekunder. I Pauls artikel rapporterer han om en forskel på 11 % til fordel for NOT NULL-tilfældet for det eksempel, han brugte.
BTW, de af jer med et skarpt øje vil have bemærket brugen af ORDER BY @@TRANCOUNT som ROW_NUMBER-funktionens bestillingsspecifikation. Hvis du nøje læser Pauls inline-kommentarer i hans løsning, nævner han, at brugen af funktionen @@TRANCOUNT er en parallelismehæmmer, hvorimod brugen af @@SPID ikke er det. Så du kan bruge @@TRANCOUNT som køretidskonstanten i bestillingsspecifikationen, når du vil gennemtvinge en seriel plan og @@SPID, når du ikke gør det.
Som nævnt tog det forespørgslen mod dbo.CS 91 sekunder at køre på min maskine. På dette tidspunkt kunne det være interessant at teste den samme kode med en ægte krydssammenføjning og lade optimeringsværktøjet bruge en algoritme for indlejrede sløjfer i rækketilstand:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
CROSS JOIN dbo.CS AS N2
) AS N; Det tog denne kode 104 sekunder at fuldføre på min maskine. Så vi får en betydelig præstationsforbedring med batch-mode hash join.
Vores næste problem er det faktum, at når du bruger TOP til at filtrere det ønskede antal rækker, får du en plan med en række-mode Top-operatør. Her er et forsøg på at implementere dbo.GetNums_SQLkiwi-funktionen med et TOP-filter:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT TOP (100000000 - 1 + 1)
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
ORDER BY rn
) AS N;
GO Lad os teste funktionen:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Jeg fik planen vist i figur 11 for denne test.
 Figur 11:Planlæg med TOP-filter
Figur 11:Planlæg med TOP-filter
Bemærk, at Top-operatøren er den eneste i planen, der bruger rækketilstandsbehandling.
Jeg fik følgende tidsstatistik for denne udførelse:
CPU-tid =6078 ms, forløbet tid =6071 ms.Den største del af kørselstiden i denne plan bruges af række-tilstand Top-operatøren og det faktum, at planen skal gennemgå batch-til-række-tilstand konvertering og tilbage.
Vores udfordring er at finde ud af et batch-mode-filtreringsalternativ til række-mode TOP. Prædikatbaserede filtre som dem, der anvendes med WHERE-sætningen, kan potentielt håndteres med batchbehandling.
Pauls tilgang var at introducere en anden INT-type kolonne (se inline-kommentaren "alt er alligevel normaliseret til 64-bit i kolonnelager/batch-tilstand" ) kaldet n2 til tabellen dbo.CS, og udfyld den med heltalssekvensen 1 til 65.536. I løsningens kode brugte han to prædikatbaserede filtre. Den ene er et groft filter i den indre forespørgsel med prædikater, der involverer kolonnen n2 fra begge sider af joinforbindelsen. Dette grove filter kan resultere i nogle falske positiver. Her er det første forsimplede forsøg på et sådant filter:
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1)))) Med input 1 og 100.000.000 som @lav og @høj får du ingen falske positiver. Men prøv med 1 og 100.000.001, og du får nogle. Du får en sekvens på 100.020.001 numre i stedet for 100.000.001.
For at eliminere de falske positiver tilføjede Paul et andet, præcist, filter, der involverede kolonnen rn i den ydre forespørgsel. Her er det første forsimplede forsøg på et så præcist filter:
WHERE
-- Precise filter:
N.rn < @high - @low + 2 Lad os revidere definitionen af funktionen for at bruge ovenstående prædikatbaserede filtre i stedet for TOP, tag 1:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
N.rn < @high - @low + 2;
GO Lad os teste funktionen:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Jeg fik planen vist i figur 12 for denne test.
 Figur 12:Planlæg med WHERE-filter, tag 1
Figur 12:Planlæg med WHERE-filter, tag 1
Ak, noget gik tydeligvis galt. SQL Server konverterede vores prædikatbaserede filter, der involverede kolonnen rn, til et TOP-baseret filter og optimerede det med en Top-operator - hvilket er præcis, hvad vi forsøgte at undgå. For at føje spot til skade besluttede optimeringsværktøjet også at bruge den indlejrede loops-algoritme til sammenføjningen.
Det tog denne kode 18,8 sekunder at afslutte på min maskine. Det ser ikke godt ud.
Med hensyn til de indlejrede loops join, er dette noget, som vi nemt kunne tage os af ved at bruge et jointip i den indre forespørgsel. Bare for at se præstationspåvirkningen er her en test med et hint til tvungen hash joinforespørgsel, der bruges i selve testforespørgslen:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(HASH JOIN);
Køretiden reduceres til 13,2 sekunder.
Vi har stadig problemet med konverteringen af WHERE-filteret mod rn til et TOP-filter. Lad os prøve at forstå, hvordan dette skete. Vi brugte følgende filter i den ydre forespørgsel:
WHERE N.rn < @high - @low + 2
Husk, at rn repræsenterer et umanipuleret ROW_NUMBER-baseret udtryk. Et filter baseret på, at et sådant umanipuleret udtryk er i et givent område, er ofte optimeret med en Top-operator, hvilket for os er dårlige nyheder på grund af brugen af row-mode-behandling.
Pauls løsning var at bruge et tilsvarende prædikat, men et der anvender manipulation på rn, som sådan:
WHERE @low - 2 + N.rn < @high
Filtrering af et udtryk, der tilføjer manipulation til et ROW_NUMBER-baseret udtryk, hæmmer konverteringen af det prædikatbaserede filter til et TOP-baseret. Det er genialt!
Lad os revidere funktionens definition for at bruge ovenstående WHERE-prædikat, tag 2:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
@low - 2 + N.rn < @high;
GO Test the function again, without any special hints or anything:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
It naturally gets an all-batch-mode plan with a hash join algorithm and no Top operator, resulting in an execution time of 3.177 seconds. Looking good.
The next step is to check if the solution handles bad inputs well. Let’s try it with a negative delta:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
This execution fails with the following error.
Msg 3623, Level 16, State 1, Line 436An invalid floating point operation occurred.
The failure is due to the attempt to apply a square root of a negative number.
Paul’s solution involved two additions. One is to add the following predicate to the inner query’s WHERE clause:
@high >= @low
This filter does more than what it seems initially. If you’ve read Paul’s inline comments carefully, you could find this part:
“Try to avoid SQRT on negative numbers and enable simplification to single constant scan if @low> @high (with literals). No start-up filters in batch mode.”The intriguing part here is the potential to use a constant scan with constants as inputs. I’ll get to this shortly.
The other addition is to apply the IIF function to the input expression to the SQRT function. This is done to avoid negative input when using nonconstants as inputs to our numbers function, and in case the optimizer decides to handle the predicate involving SQRT before the predicate @high>=@low.
Before the IIF addition, for example, the predicate involving N1.n2 looked like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
After adding IIF, it looks like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
With these two additions, we’re now basically ready for the final definition of the dbo.GetNums_SQLkiwi function:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Now back to the comment about the constant scan. When using constants that result in a negative range as inputs to the function, e.g., 100,000,000 and 1 as @low and @high, after parameter embedding the WHERE filter of the inner query looks like this:
WHERE
1 >= 100000000
AND ... The whole plan can then be simplified to a single Constant Scan operator. Prøv det:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
The plan for this execution is shown in Figure 13.
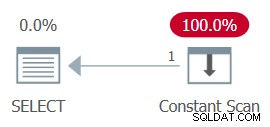 Figure 13:Plan with constant scan
Figure 13:Plan with constant scan
Unsurprisingly, I got the following performance numbers for this execution:
CPU time =0 ms, elapsed time =0 ms.logical reads 0
When passing a negative range with nonconstants as inputs, the use of the IIF function will prevent any attempt to compute a square root of a negative input.
Now let’s test the function with a valid input range:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
You get the all-batch-mode plan shown in Figure 14.
 Figure 14:Plan for dbo.GetNums_SQLkiwi function
Figure 14:Plan for dbo.GetNums_SQLkiwi function
This is the same plan you saw earlier in Figure 7.
I got the following time statistics for this execution:
CPU time =3000 ms, elapsed time =3111 ms.Ladies and gentlemen, I think we have a winner! :)
Konklusion
I’ll have what Paul’s having.
Are we done yet, or is this series going to last forever?
No and no.