Dette er den anden del af en serie i fem dele, der tager et dybt dyk ned i den måde, parallelle planer for SQL Server-rækketilstande starter op. Ved slutningen af den første del havde vi oprettet udførelseskontekst nul til forældreopgaven. Denne kontekst indeholder hele træet af eksekverbare operatører, men de er endnu ikke klar til den iterative udførelsesmodel af forespørgselsbehandlingsmotoren.
Iterativ udførelse
SQL Server udfører en forespørgsel gennem en proces kendt som en forespørgselsscanning . Initialisering af planen starter ved roden ved at forespørgselsprocessoren kalder Open på rodknuden. Open opkald krydser træet af iteratorer rekursivt kalder Open på hvert barn, indtil hele træet er åbnet.
Processen med at returnere resultatrækker er også rekursiv, udløst af forespørgselsprocessoren, der kalder GetRow ved roden. Hvert rodkald returnerer en række ad gangen. Forespørgselsprocessoren fortsætter med at kalde GetRow på rodnoden, indtil der ikke er flere rækker tilgængelige. Udførelsen lukker ned med en sidste rekursiv Close opkald. Dette arrangement gør det muligt for forespørgselsprocessoren at initialisere, udføre og lukke enhver vilkårlig plan ved at kalde de samme grænseflademetoder lige ved roden.
For at transformere træet af eksekverbare operatører til en, der er egnet til række-for-række-behandling, tilføjer SQL Server en forespørgselsscanning indpakning til hver operatør. Forespørgselsscanningen objektet giver Open , GetRow og Close metoder, der er nødvendige for iterativ udførelse.
Forespørgselsscanningsobjektet vedligeholder også tilstandsinformation og afslører andre operatørspecifikke metoder, der er nødvendige under udførelsen. For eksempel forespørgselsscanningsobjektet for en Start-Up Filter-operatør (CQScanStartupFilterNew ) afslører følgende metoder:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
De yderligere metoder til denne iterator er for det meste brugt i markørplaner.
Initialisering af forespørgselsscanningen
Indpakningsprocessen kaldes initialisering af forespørgselsscanningen . Det udføres af et opkald fra forespørgselsprocessoren til CQueryScan::InitQScanRoot . Den overordnede opgave udfører denne proces for hele planen (indeholdt i udførelseskontekst nul). Oversættelsesprocessen er i sig selv rekursiv, den starter ved roden og arbejder sig ned i træet.
Under denne proces er hver operatør ansvarlig for at initialisere sine egne data og skabe eventuelle runtime-ressourcer det har brug for. Dette kan omfatte oprettelse af yderligere objekter uden for forespørgselsprocessoren, for eksempel de strukturer, der er nødvendige for at kommunikere med lagermotoren for at hente data fra vedvarende lager.
En påmindelse om udførelsesplanen med tilføjet nodenumre (klik for at forstørre):
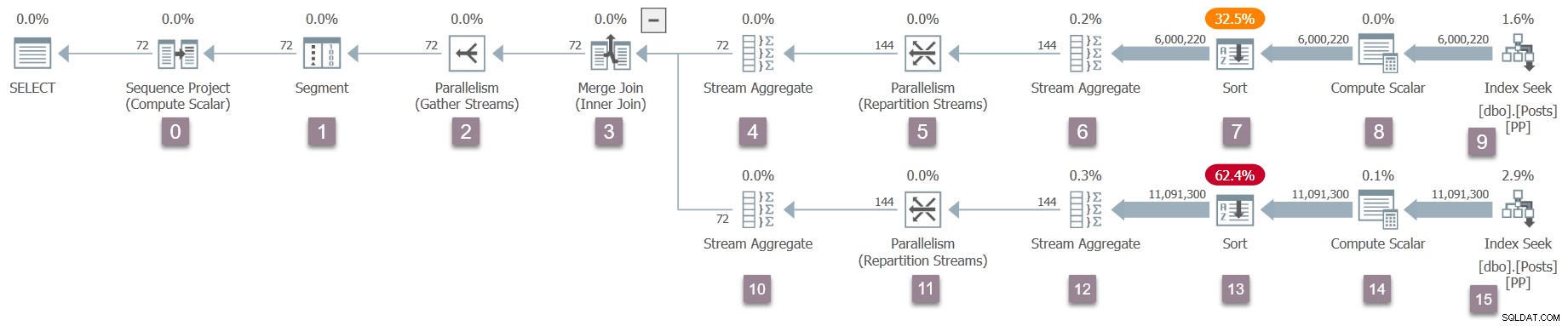
Operatøren ved roden (node 0) i det eksekverbare plantræ er et sekvensprojekt . Det er repræsenteret af en klasse ved navn CXteSeqProject . Som sædvanligt er det her den rekursive transformation starter.
Forespørgselsscanningsindpakninger
Som nævnt er CXteSeqProject objektet er ikke udstyret til at deltage i den iterative forespørgselsscanning proces — den har ikke den nødvendige Open , GetRow og Close metoder. Forespørgselsprocessoren har brug for en indpakning omkring den eksekverbare operatør for at levere denne grænseflade.
For at få denne forespørgselsscanningsindpakning kalder den overordnede opgave CXteSeqProject::QScanGet for at returnere et objekt af typen CQScanSeqProjectNew . Det linkede kort af operatører, der er oprettet tidligere, opdateres for at referere til det nye forespørgselsscanningsobjekt, og dets iteratormetoder er forbundet med roden af planen.
Sekvensprojektets underordnede er et segment operatør (node 1). Kalder CXteSegment::QScanGet returnerer et forespørgselsscanningsindpakningsobjekt af typen CQScanSegmentNew . Det sammenkædede kort opdateres igen, og iteratorfunktions pointere er forbundet til den overordnede sekvensprojektforespørgselsscanning.
En halv udveksling
Den næste operatør er en udveksling for samlestrømme (node 2). Kalder CXteExchange::QScanGet returnerer en CQScanExchangeNew som du måske forventer nu.
Dette er den første operatør i træet, der skal udføre betydelig ekstra initialisering. Det skaber forbrugersiden af udvekslingen via CXTransport::CreateConsumerPart . Dette opretter porten (CXPort ) — en datastruktur i delt hukommelse, der bruges til synkronisering og dataudveksling — og en pipe (CXPipe ) til pakketransport. Bemærk, at producenten siden af udvekslingen er ikke oprettet på dette tidspunkt. Vi har kun en halv udveksling!
Mere indpakning
Processen med at konfigurere forespørgselsprocessorscanningen fortsætter derefter med flet sammenføjningen (node 3). Jeg vil ikke altid gentage QScanGet og CQScan* opkald fra dette tidspunkt, men de følger det etablerede mønster.
Sammenlægningen har to børn. Opsætning af forespørgselsscanning fortsætter som før med det ydre (øverste) input - et streamaggregat (node 4), derefter streamer en ompartition udveksling (node 5). Omfordelingsstrømmene opretter igen kun forbrugersiden af centralen, men denne gang er der oprettet to rør, fordi DOP er to. Forbrugersiden af denne type central har DOP-forbindelser til sin overordnede operatør (én pr. tråd).
Dernæst har vi endnu et streamaggregat (node 6) og en sortering (node 7). Sorten har et underordnet, der ikke er synligt i udførelsesplaner - et rækkesæt af lagermaskine, der bruges til at implementere spild til tempdb . Den forventede CQScanSortNew er derfor ledsaget af en underordnet CQScanRowsetNew i det indre træ. Det er ikke synligt i showplan output.
I/O-profilering og udskudte operationer
sorteringen operator er også den første, vi har initialiseret indtil videre, som muligvis er ansvarlig for I/O . Forudsat at udførelsen har anmodet om I/O-profileringsdata (f.eks. ved at anmode om en "faktisk" plan), opretter sorteringen et objekt til at registrere disse runtime-profileringsdata via CProfileInfo::AllocProfileIO .
Den næste operator er en beregningsskalar (node 8), kaldet et projekt internt. Opkaldet til forespørgselsscanning til CXteProject::QScanGet gør ikke returnere et forespørgselsscanningsobjekt, fordi beregningerne udført af denne beregningsskalar er udskudt til den første overordnede operatør, der har brug for resultatet. I denne plan er den operatør den slags. Sorteringen vil udføre alt det arbejde, der er tildelt computerskalaren, så projektet i node 8 udgør ikke en del af forespørgselsscanningstræet. Beregningsskalaren udføres virkelig ikke under kørsel. For flere detaljer om udskudte beregningsskalarer, se Beregn skalarer, udtryk og eksekveringsplanydelse.
Parallel scanning
Den sidste operator efter beregningsskalaren på denne gren af planen er en indekssøgning (CXteRange ) ved node 9. Dette producerer den forventede forespørgselsscanningsoperator (CQScanRangeNew ), men det kræver også en kompleks sekvens af initialiseringer at oprette forbindelse til lagermotoren og lette en parallel scanning af indekset.
Bare dækker højdepunkterne, initialiserer indekssøgningen:
- Opretter et profileringsobjekt for I/O (
CProfileInfo::AllocProfileIO). - Opretter et parallelt rækkesæt forespørgselsscanning (
CQScanRowsetNew::ParallelGetRowset). - Opretter en synkronisering objekt for at koordinere runtime parallel rækkevidde scanning (
CQScanRangeNew::GetSyncInfo). - Opretter lagermotoren tabelmarkør og en skrivebeskyttet transaktionsbeskrivelse .
- Åbner det overordnede rækkesæt til læsning (adgang til HoBt og tager de nødvendige låse).
- Indstiller låsetimeout.
- Konfigurerer forudhentning (inklusive tilknyttede hukommelsesbuffere).
Tilføjelse af rækketilstandsprofileringsoperatorer
Vi har nu nået bladniveauet for denne gren af planen (indekssøgningen har intet barn). Efter lige at have oprettet forespørgselsscanningsobjektet til indekssøgningen, er næste trin at ombryde forespørgselsscanningen med en profileringsklasse (forudsat at vi anmodede om en egentlig plan). Dette gøres ved et opkald til sqlmin!PqsWrapQScan . Bemærk, at profiler tilføjes efter forespørgselsscanningen er blevet oprettet, når vi begynder at stige op i iteratortræet.
PqsWrapQScan opretter en ny profileringsoperatør som forælder af indekssøgningen via et opkald til CProfileInfo::GetOrCreateProfileInfo . profileringsoperatøren (CQScanProfileNew ) har de sædvanlige forespørgselsscanningsgrænseflademetoder. Ud over at indsamle de nødvendige data til faktiske planer, eksponeres profileringsdataene også via DMV sys.dm_exec_query_profiles .
Forespørgsel på, at DMV på dette præcise tidspunkt for den aktuelle session viser, at kun en enkelt planoperatør (node 9) eksisterer (hvilket betyder, at det er den eneste, der er pakket af en profiler):

Dette skærmbillede viser det komplette resultatsæt fra DMV på nuværende tidspunkt (det er ikke blevet redigeret).
Næste, CQScanProfileNew kalder query performance counter API (KERNEL32!QueryPerformanceCounterStub ) leveret af operativsystemet til at registrere den første og sidste aktive tid af den profilerede operatør:

Det sidste aktive tidspunkt vil blive opdateret ved hjælp af forespørgselsydeevnetæller-API'en, hver gang koden for den iterator kører.
Profileren indstiller derefter det estimerede antal rækker på dette tidspunkt i planen (CProfileInfo::SetCardExpectedRows ), der tager højde for ethvert rækkemål (CXte::CardGetRowGoal ). Da dette er en parallel plan, dividerer den resultatet med antallet af tråde (CXte::FGetRowGoalDefinedForOneThread ) og gemmer resultatet i udførelseskonteksten.
Det estimerede antal rækker er ikke synligt via DMV på dette tidspunkt, fordi den overordnede opgave ikke vil udføre denne operatør. I stedet vil per-thread-estimatet blive eksponeret senere i parallelle eksekveringskontekster (som ikke er oprettet endnu). Ikke desto mindre gemmes nummeret pr. tråd i den overordnede opgaves profiler - det er bare ikke synligt gennem DMV.
Det venlige navn af planoperatøren ("Index Seek") indstilles derefter via et opkald til CXteRange::GetPhysicalOp :

Før det har du måske bemærket, at forespørgsel på DMV viste navnet som "???". Dette er det permanente navn, der vises for usynlige operatører (f.eks. indlejrede løkker, forudhentning, batchsortering), som ikke har et venligt navn defineret.
Til sidst, indekser metadata og aktuelle I/O-statistikker for den indpakkede indekssøgning tilføjes via et opkald til CQScanRowsetNew::GetIoCounters :

Tællerne er nul i øjeblikket, men vil blive opdateret, efterhånden som indekssøgningen udfører I/O under afsluttet planudførelse.
Flere forespørgselsscanningsbehandling
Med profileringsoperatoren oprettet til indekssøgningen, flyttes forespørgselsscanningsbehandlingen tilbage op i træet til den overordnede sortering (node 7).
Sorteringen udfører følgende initialiseringsopgaver:
- Registrerer dets hukommelsesbrug med forespørgslen hukommelseshåndtering (
CQryMemManager::RegisterMemUsage) - Beregner den nødvendige hukommelse til sorteringsinputtet (
CQScanIndexSortNew::CbufInputMemory) og output (CQScanSortNew::CbufOutputMemory). - Sorteringstabellen oprettes sammen med dets tilknyttede rækkesæt for lagermotor (
sqlmin!RowsetSorted). - En selvstændig systemtransaktion (ikke afgrænset af brugertransaktionen) oprettes til sortering af spilddisktildelinger sammen med en falsk arbejdstabel (
sqlmin!CreateFakeWorkTable). - Expressionstjenesten er initialiseret (
sqlTsEs!CEsRuntime::Startup) for sorteringsoperatoren til at udføre beregningerne udskudt fra beregningsskalaren. - Forudhent for enhver slags kørsler spildt til tempdb oprettes derefter via (
CPrefetchMgr::SetupPrefetch).
Til sidst pakkes sorteringsforespørgselsscanningen af en profileringsoperatør (inklusive I/O), ligesom vi så for indekssøgningen:

Bemærk, at beregningsskalaren (node 8) mangler fra DMV. Det skyldes, at dets arbejde er udskudt til sorteringen, ikke er en del af forespørgselsscanningstræet og derfor ikke har noget indpakningsprofilobjekt.
Flytter op til den overordnede type, stream-aggregatet forespørgselsscanningsoperator (node 6) initialiserer sine udtryk og runtime-tællere (f.eks. aktuel grupperækketælling). Strømaggregatet er pakket ind med en profileringsoperatør, der registrerer dets indledende tider:

Den overordnede ompartition streamer udveksling (node 5) er pakket af en profiler (husk, at kun forbrugersiden af denne udveksling eksisterer på dette tidspunkt):

Det samme gøres for dets overordnede streamaggregat (node 4), som også initialiseres som tidligere beskrevet:

Forespørgselsscanningsbehandlingen vender tilbage til den overordnede fletningssammenføjning (node 3), men initialiserer den ikke endnu. I stedet bevæger vi os ned langs den indvendige (nederste) side af sammenføjningen og udfører de samme detaljerede opgaver for disse operatører (knudepunkter 10 til 15) som for den øvre (ydre) gren:
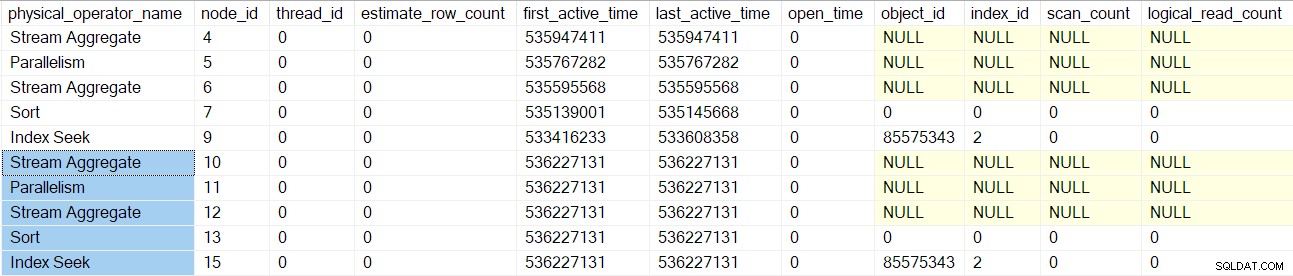
Når disse operatører er behandlet, sammenflettes forespørgselsscanning oprettes, initialiseres og omvikles med et profileringsobjekt. Dette inkluderer I/O-tællere, fordi en mange-mange-sammenføjning bruger en arbejdstabel (selvom den aktuelle flette-sammenføjning er en-mange):
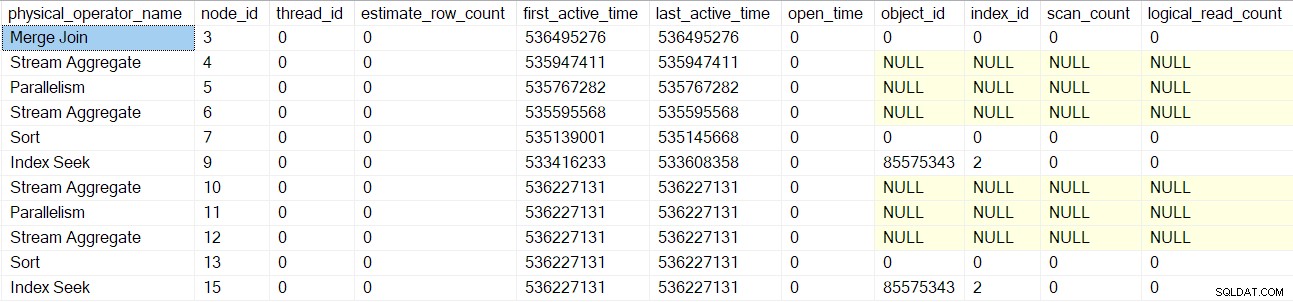
Den samme proces følges for udvekslingen af forældreindsamlingsstrømme (node 2) kun på forbrugersiden, segment (node 1) og sekvensprojekt (node 0) operatører. Jeg vil ikke beskrive dem i detaljer.
Forespørgselsprofilerne DMV rapporterer nu et komplet sæt profiler-indpakkede forespørgselsscannoder:
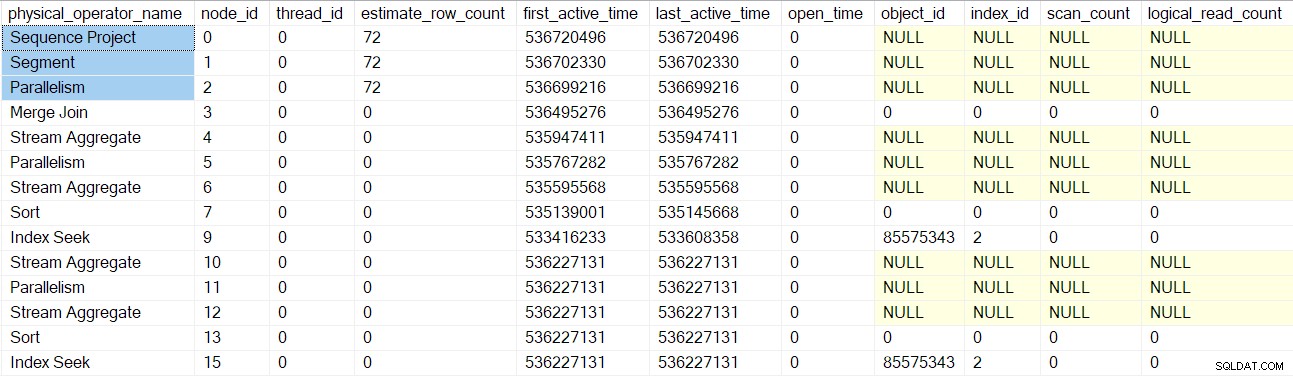
Bemærk, at sekvensprojekt-, segment- og samlestrømforbrugeren har et estimeret rækkeantal, fordi disse operatører vil blive kørt af overordnet opgave , ikke ved yderligere parallelle opgaver (se CXte::FGetRowGoalDefinedForOneThread tidligere). Den overordnede opgave har intet arbejde at udføre i parallelle grene, så konceptet med estimeret rækkeantal giver kun mening for yderligere opgaver.
De aktive tidsværdier vist ovenfor er noget forvrænget, fordi jeg var nødt til at stoppe eksekveringen og tage DMV-skærmbilleder ved hvert trin. En separat udførelse (uden de kunstige forsinkelser introduceret ved at bruge en debugger) producerede følgende timings:
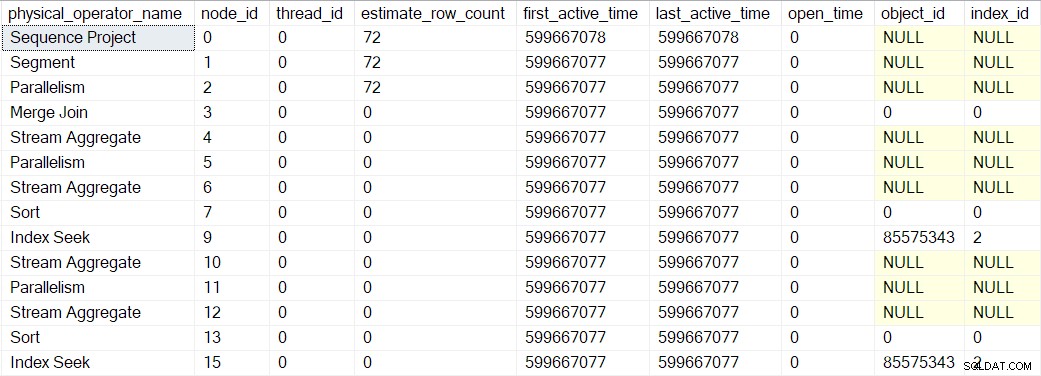
Træet er konstrueret i samme rækkefølge som beskrevet før, men processen er så hurtig, at der kun er 1 mikrosekund forskel mellem den første omviklede operatørs aktive tid (indekssøgningen ved node 9) og den sidste (sekvensprojekt ved node 0).
Slut på del 2
Det lyder måske som om, vi har gjort meget arbejde, men husk, at vi kun har oprettet et forespørgselsscanningstræ til overordnet opgave , og børserne har kun en forbrugerside (ingen producent endnu). Vores parallelle plan har også kun én tråd (som vist på sidste skærmbillede). Del 3 vil se oprettelsen af vores første yderligere parallelle opgaver.