Dette er den tredje i en serie i fem dele, der tager et dybt dyk ned i den måde, hvorpå parallelle planer for SQL Server-rækketilstande begynder at blive eksekveret. Del 1 initialiserede udførelseskontekst nul for den overordnede opgave, og del 2 oprettede forespørgselsscanningstræet. Vi er nu klar til at starte forespørgselsscanningen, udføre en tidlig fase behandling, og start de første ekstra parallelle opgaver.
Opstart af forespørgselsscanning
Husk, at kun overordnet opgave eksisterer lige nu, og børserne (parallelismeoperatører) har kun en forbrugerside. Alligevel er dette nok til, at udførelse af forespørgsler kan begynde på den overordnede opgaves arbejdstråd. Forespørgselsprocessoren begynder at udføre ved at starte forespørgselsscanningsprocessen via et kald til CQueryScan::StartupQuery . En påmindelse om planen (klik for at forstørre):
Dette er det første punkt i processen indtil videre, at en udførelsesplan under flyvningen er tilgængelig (SQL Server 2016 SP1 og frem) i sys.dm_exec_query_statistics_xml . Der er ikke noget særligt interessant at se i en sådan plan på nuværende tidspunkt, fordi alle transienttællere er nul, men planen er i det mindste tilgængelig . Der er ingen antydninger om, at der endnu ikke er skabt parallelle opgaver, eller at børserne mangler en producentside. Planen ser 'normal' ud i alle henseender.
Parallelle plangrene
Da dette er en parallel plan, vil det være nyttigt at vise den opdelt i grene. Disse er skraverede nedenfor og mærket som grene A til D:
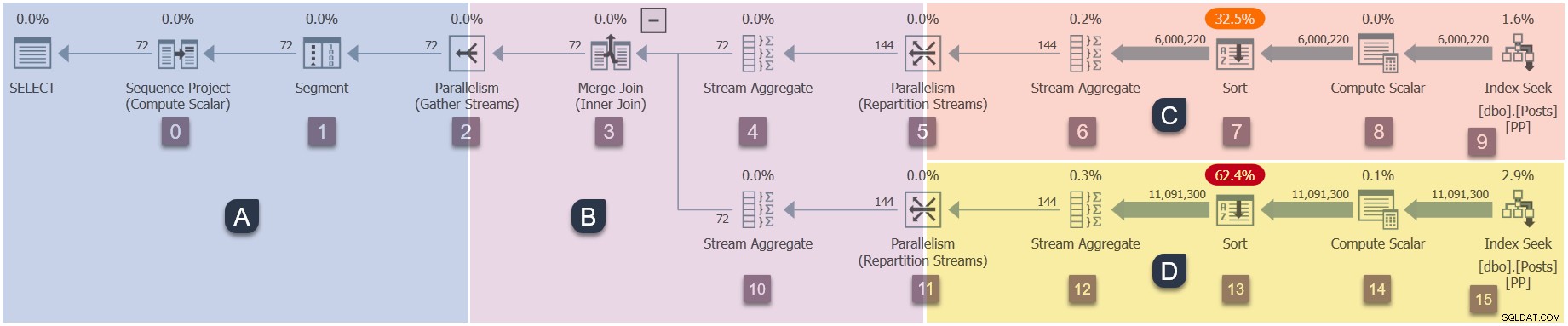
Gren A er knyttet til den overordnede opgave, der kører på arbejdstråden fra sessionen. Yderligere parallelle arbejdere vil blive startet til at køre de yderligere parallelle opgaver indeholdt i grene B, C og D. Disse grene er parallelle, så der vil være yderligere DOP-opgaver og arbejdere i hver enkelt.
Vores eksempelforespørgsel kører på DOP 2, så gren B får to ekstra opgaver. Det samme gælder for gren C og gren D, hvilket giver i alt seks yderligere opgaver. Hver opgave kører på sin egen arbejdstråd i sin egen udførelseskontekst.
To planlæggere (S1 og S2 ) er tildelt denne forespørgsel for at køre yderligere parallelle arbejdere. Hver ekstra arbejder vil køre på en af disse to planlæggere. Den overordnede arbejder kan køre på en anden planlægger, så vores DOP 2-forespørgsel må maksimalt bruge tre processorkerner på et hvilket som helst tidspunkt.
For at opsummere vil vores plan med tiden have:
- Afdeling A (forælder)
- Overordnet opgave.
- Forældremedarbejdertråd.
- Eksekveringskontekst nul.
- Enhver enkelt planlægningsprogram tilgængelig for forespørgslen.
- Afdeling B (yderligere)
- To ekstra opgaver.
- En ekstra arbejdstråd bundet til hver ny opgave.
- To nye udførelseskontekster, én for hver ny opgave.
- Én arbejdstråd kører på skemalægger S1 . Den anden kører på skemalægger S2 .
- Afdeling C (yderligere)
- To ekstra opgaver.
- En ekstra arbejdstråd bundet til hver ny opgave.
- To nye udførelseskontekster, én for hver ny opgave.
- Én arbejdstråd kører på skemalægger S1 . Den anden kører på skemalægger S2 .
- Afdeling D (yderligere)
- To ekstra opgaver.
- En ekstra arbejdstråd bundet til hver ny opgave.
- To nye udførelseskontekster, én for hver ny opgave.
- Én arbejdstråd kører på skemalægger S1 . Den anden kører på skemalægger S2 .
Spørgsmålet er, hvordan alle disse ekstra opgaver, arbejdere og udførelseskontekster skabes, og hvornår de begynder at køre.
Startsekvens
Rækkefølgen, hvori yderligere opgaver begynde at udføre for denne særlige plan er:
- Afdeling A (overordnet opgave).
- Afdeling C (yderligere parallelle opgaver).
- Afdeling D (yderligere parallelle opgaver).
- Afdeling B (yderligere parallelle opgaver).
Det er muligvis ikke den opstartsordre, du havde forventet.
Der kan være en betydelig forsinkelse mellem hvert af disse trin, af årsager, som vi vil undersøge om kort tid. Nøglepunktet på dette trin er, at de yderligere opgaver, arbejdere og udførelseskontekster ikke er alle oprettet på én gang, og det gør de ikke alle begynder at udføre på samme tid.
SQL Server kunne have været designet til at starte alle de ekstra parallelle bits på én gang. Det kan være let at forstå, men det ville generelt ikke være særlig effektivt. Det ville maksimere antallet af yderligere tråde og andre ressourcer, der bruges af forespørgslen, og resultere i en masse unødvendige parallelle ventetider.
Med designet anvendt af SQL Server vil parallelle planer ofte bruge færre samlede arbejdstråde end (DOP ganget med det samlede antal filialer). Dette opnås ved at erkende, at nogle filialer kan køre til færdiggørelse, før en anden filial skal starte. Dette kan tillade genbrug af tråde i den samme forespørgsel og reducerer generelt ressourceforbruget generelt.
Lad os nu gå til detaljerne om, hvordan vores parallelle plan starter op.
Åbningsgren A
Forespørgselsscanningen begynder at udføre med den overordnede opgave, der kalder Open() på iteratoren ved roden af træet. Dette er starten på udførelsessekvensen:
- Gren A (overordnet opgave).
- Afdeling C (yderligere parallelle opgaver).
- Afdeling D (yderligere parallelle opgaver).
- Afdeling B (yderligere parallelle opgaver).
Vi udfører denne forespørgsel med en "faktisk" plan anmodet, så root iteratoren er ikke sekvensprojektoperatøren ved node 0. Det er snarere den usynlige profilerings-iterator der registrerer runtime-metrics i rækketilstandsplaner.
Illustrationen nedenfor viser forespørgselsscannings-iteratorerne i gren A af planen, med positionen af usynlige profilerings-iteratorer repræsenteret af 'brille'-ikonerne.
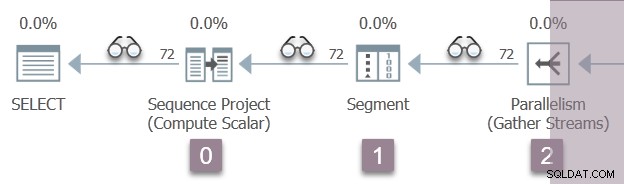
Udførelsen starter med et kald for at åbne den første profiler, CQScanProfileNew::Open . Dette indstiller åbningstiden for underordnet sekvensprojektoperatør via operativsystemets Query Performance Counter API.
Vi kan se dette nummer i sys.dm_exec_query_profiles :
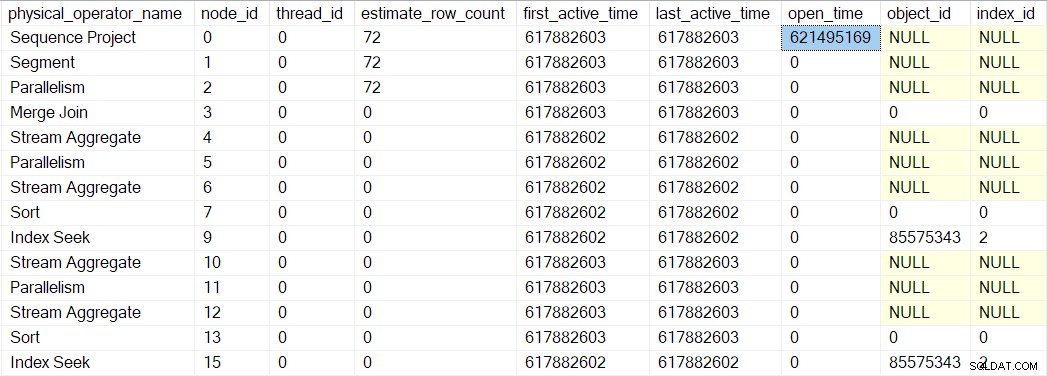
Indtastningerne der kan have operatørnavnene på listen, men dataene kommer fra profiler over operatøren, ikke operatøren selv.
Som det sker, et sekvensprojekt (CQScanSeqProjectNew ) behøver ikke at udføre noget arbejde, når den åbnes , så den har faktisk ikke en Open() metode. Profileren over sekvensprojektet er kaldet, så en åben tid for sekvensprojektet registreres i DMV.
Profilerens Open metode kalder ikke Open på sekvensprojektet (da det ikke har en). I stedet kalder den Open på profileren for den næste iterator i rækkefølge. Dette er segmentet iterator ved node 1. Det sætter åbningstiden for segmentet, ligesom den tidligere profiler gjorde for sekvensprojektet:
En segmentiterator gør har ting at lave, når den åbnes, så næste opkald er at CQScanSegmentNew::Open . Når segmentet har gjort, hvad det skal, kalder det profileren for den næste iterator i rækkefølge - forbrugeren side af saml strømudveksling ved node 2:
Det næste kald ned i forespørgselsscanningstræet i åbningsprocessen er CQScanExchangeNew::Open , hvor tingene begynder at blive mere interessante.
Åbning af samlestrømsbørsen
Beder forbrugersiden af børsen om at åbne:
- Åbner en lokal (parallel indlejret) transaktion (
CXTransLocal::Open). Hver proces har brug for en indeholdende transaktion, og yderligere parallelle opgaver er ingen undtagelse. De kan ikke dele den overordnede (basis) transaktion direkte, så indlejrede transaktioner bruges. Når en parallel opgave skal have adgang til basistransaktionen, synkroniseres den på en lås og kan støde påNESTING_TRANSACTION_READONLYellerNESTING_TRANSACTION_FULLventer. - Registrerer den aktuelle arbejdstråd med udvekslingsporten (
CXPort::Register). - Synkroniserer med andre tråde på forbrugersiden af udvekslingen (
sqlmin!CXTransLocal::Synchronize). Der er ingen andre tråde på forbrugersiden af samlestrømme, så dette er i bund og grund en no-op ved denne lejlighed.
"Tidlige faser"-behandling
Forældreopgaven er nu nået til kanten af gren A. Næste trin er særligt til parallelle planer i rækketilstand:Den overordnede opgave fortsætter udførelse ved at kalde CQScanExchangeNew::EarlyPhases på samlestrømme udveksle iterator ved node 2. Dette er en ekstra iteratormetode ud over den sædvanlige Open , GetRow og Close metoder, som mange af jer vil være bekendt med. EarlyPhases kaldes kun i rækketilstand parallelle planer.
Jeg vil gerne være klar over noget på dette tidspunkt:Producersiden af samlestrømsudvekslingen ved node 2 har ikke er oprettet endnu, og nej yderligere parallelle opgaver er blevet oprettet. Vi udfører stadig kode for den overordnede opgave, og bruger den eneste tråd, der kører lige nu.
Ikke alle iteratorer implementerer EarlyPhases , fordi ikke alle af dem har noget særligt at gøre på dette tidspunkt i rækketilstands parallelle planer. Dette er analogt med sekvensprojektet, der ikke implementerer Open metode, fordi den ikke har noget at gøre på det tidspunkt. De vigtigste iteratorer med EarlyPhases metoder er:
CQScanConcatNew(sammenkædning).CQScanMergeJoinNew(flet deltagelse).CQScanSwitchNew(skift).CQScanExchangeNew(parallelisme).CQScanNew(radsætadgang, f.eks. scanninger og søgninger).CQScanProfileNew(usynlige profiler).CQScanLightProfileNew(usynlige letvægtsprofiler).
Brench B tidlige faser
forældreopgaven fortsætter ved at kalde EarlyPhases på underordnede operatører ud over samlestrømsudvekslingen ved node 2. En opgave, der bevæger sig over en grengrænse, kan virke usædvanlig, men husk, at eksekveringskontekst nul indeholder hele den serielle plan, med udvekslinger inkluderet. Tidlig fasebehandling handler om at initialisere parallelisme, så det tæller ikke som udførelse i sig selv .
For at hjælpe dig med at holde styr på, viser billedet nedenfor iteratorerne i gren B af planen:
Husk, vi er stadig i udførelseskontekst nul, så jeg refererer kun til dette som gren B for nemheds skyld. Vi er ikke startet nogen parallel eksekvering endnu.
Sekvensen af tidlig fase kode påkald i gren B er:
CQScanProfileNew::EarlyPhasesfor profileren over node 3.CQScanMergeJoinNew::EarlyPhasesved node 3 flet join .CQScanProfileNew::EarlyPhasesfor profileren over node 4. Node 4 strømaggregat i sig selv har ikke en tidlig fasemetode.CQScanProfileNew::EarlyPhasespå profileren over node 5.CQScanExchangeNew::EarlyPhasesfor omopdelingsstrømmene udveksling ved node 5.
Bemærk, at vi kun behandler det ydre (øvre) input til flettesammenføjningen på dette trin. Dette er blot den normale iterative sekvens for udførelse af rækketilstand. Det er ikke specielt for parallelle planer.
Brench C tidlige faser
Behandling i den tidlige fase fortsætter med iteratorerne i gren C:

Rækkefølgen af opkald her er:
CQScanProfileNew::EarlyPhasesfor profileren over node 6.CQScanProfileNew::EarlyPhasesfor profileren over node 7.CQScanProfileNew::EarlyPhasespå profileren over node 9.CQScanNew::EarlyPhasesfor indekssøgningen ved node 9.
Der er ingen EarlyPhases metode på strømaggregatet eller sorteringen. Arbejdet udført af compute scalar ved node 8 er udskudt (til sorteringen), så den vises ikke i forespørgselsscanningstræet og har ikke en tilknyttet profiler.
Om profileringstidspunkter
Forældreopgave bearbejdning i tidlig fase begyndte ved samlestrømudvekslingen ved node 2. Den gik ned i forespørgselsscanningstræet, efter det ydre (øverste) input til flettesammenføjningen, helt ned til indekssøgningen ved node 9. Undervejs har den overordnede opgave kaldt EarlyPhases metode på hver iterator, der understøtter det.
Ingen af aktiviteten i de tidlige faser er indtil videre opdateret enhver tid i profilerings-DMV. Specifikt har ingen af de iteratorer, der er berørt af behandling i de tidlige faser, fået deres 'åben tid' indstillet. Dette giver mening, fordi behandling i tidlig fase blot opsætter parallel eksekvering - disse operatører vil blive åbnet til udførelse senere.
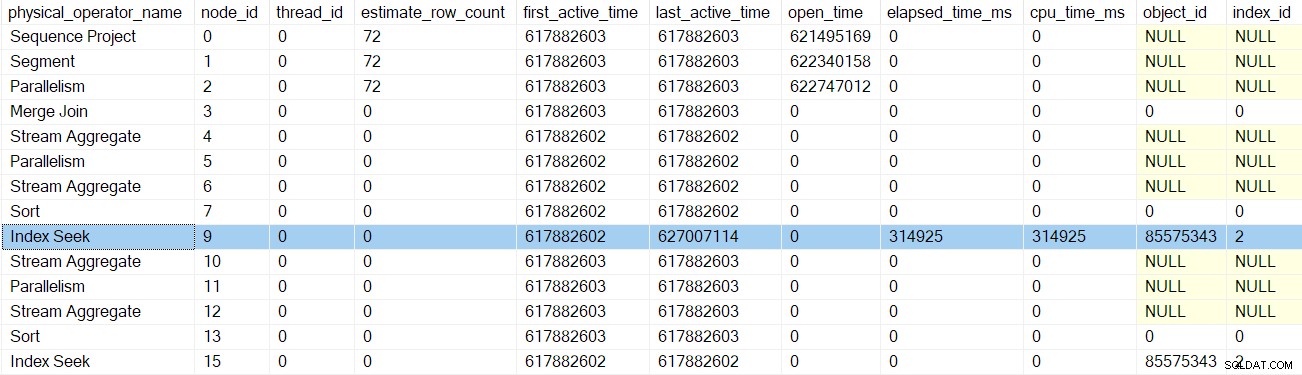
Indekssøgningen ved node 9 er en bladknude – den har ingen børn. Den overordnede opgave begynder nu at vende tilbage fra de indlejrede EarlyPhases opkald, stigende forespørgselsscanningstræet tilbage mod samlestrømudvekslingen.
Hver af profilerne kalder Forespørgselsydelsestælleren API ved adgang til deres EarlyPhases metode, og de kalder den igen på vej ud. Forskellen mellem de to tal repræsenterer forløbet tid for iteratoren og alle dens børn (da metodekaldene er indlejret).
Når profileringsmaskinen for indekssøgningen vender tilbage, viser profileringsmaskinens DMV forløbet og CPU-tid for indekssøgningen kun, samt en opdateret sidst aktive tid. Bemærk også, at disse oplysninger er registreret i forhold til overordnet opgave (den eneste mulighed lige nu):
Ingen af de tidligere iteratorer, der berøres af de tidlige faser, har forløbne tider eller opdaterede sidste aktive tider. Disse tal opdateres kun, når vi stiger op i træet.
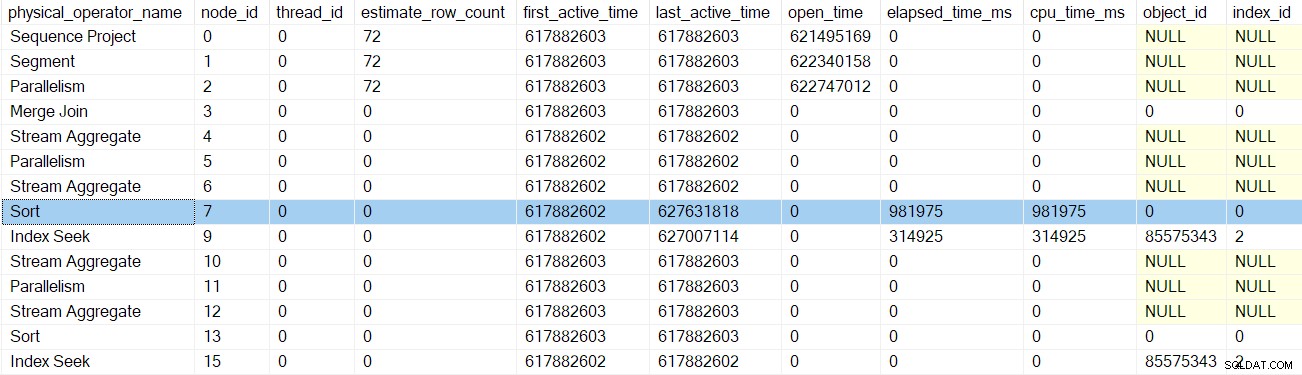
Efter den næste profiler tidlige faser kalder tilbage, sorteringen tiderne er opdateret:
Den næste returnering fører os op forbi profileringsværktøjet for streamaggregatet ved node 6:
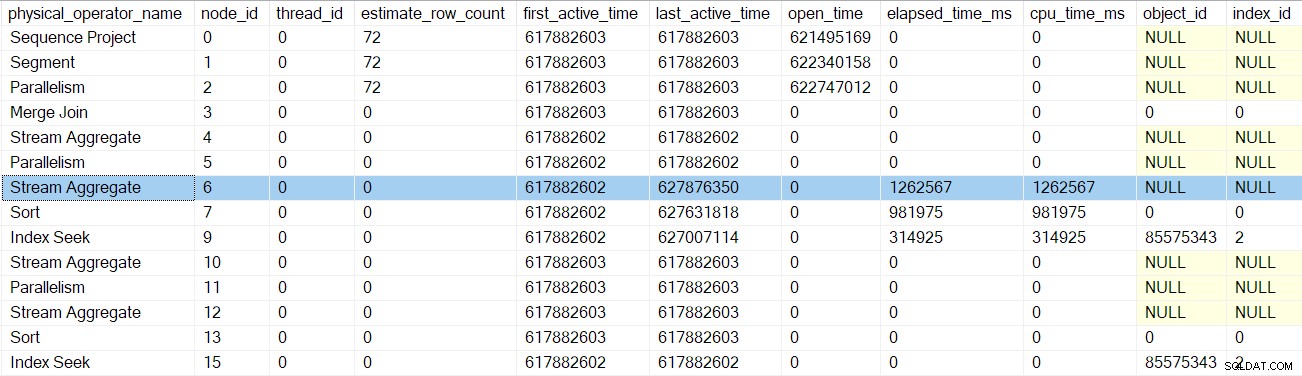
At vende tilbage fra denne profiler fører os tilbage til EarlyPhases ring til omfordelingsstrømmene udveksling ved node 5 . Husk, at det ikke var her, sekvensen af opkald i de tidlige faser startede – det var samlestrømsudvekslingen ved node 2.
Branch C parallelle opgaver i kø
Bortset fra opdatering af profileringsdata syntes de tidligere tidlige faser ikke at gøre ret meget. Det hele ændrer sig med omopdelingsstrømmene udveksling ved node 5.
Jeg vil beskrive gren C ret detaljeret for at introducere en række vigtige begreber, som også vil gælde for de andre parallelle grene. At dække denne grund én gang nu betyder, at senere grendiskussion kan være mere kortfattet.
Efter at have afsluttet indlejret tidlig fasebehandling for sit undertræ (ned til indekssøgningen ved node 9), kan udvekslingen begynde sit eget tidlige fasearbejde. Dette starter på samme måde som åbning samlestrømmene udveksler ved node 2:
CXTransLocal::Open(åbning af den lokale parallelle deltransaktion).CXPort::Register(registrering med udvekslingsporten).
De næste trin er anderledes, fordi gren C indeholder en fuldstændig blokering iterator (sorteringen ved node 7). Den tidlige fasebehandling ved node 5 ompartitionsstrømmene gør følgende:
- Opkald
CQScanExchangeNew::StartAllProducers. Det er første gang, vi støder på noget, der refererer til producentsiden af udvekslingen. Node 5 er den første børs i denne plan til at skabe sin producentside. - Hver en mutex så ingen anden tråd kan stille opgaver i kø på samme tid.
- Starter parallelle indlejrede transaktioner for producentopgaverne (
CXPort::StartNestedTransactionsogReadOnlyXactImp::BeginParallelNestedXact). - Registrerer undertransaktionerne med det overordnede forespørgselsscanningsobjekt (
CQueryScan::AddSubXact). - Opretter producentbeskrivelser (
CQScanExchangeNew::PxproddescCreate). - Opretter nye producentudførelseskontekster (
CExecContext) afledt af udførelseskontekst nul. - Opdaterer det linkede kort over plan-iteratorer.
- Indstiller DOP for den nye kontekst (
CQueryExecContext::SetDop), så alle opgaver ved, hvad den overordnede DOP-indstilling er. - Initialiserer parametercachen (
CQueryExecContext::InitParamCache). - Linker de parallelt indlejrede transaktioner til basistransaktionen (
CExecContext::SetBaseXact). - Sæter de nye underprocesser i kø til udførelse (
SubprocessMgr::EnqueueMultipleSubprocesses). - Opretter nye parallelle opgaver opgaver via
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
Forælderopgavens kaldstak (for dem af jer, der nyder disse ting) omkring dette tidspunkt er:
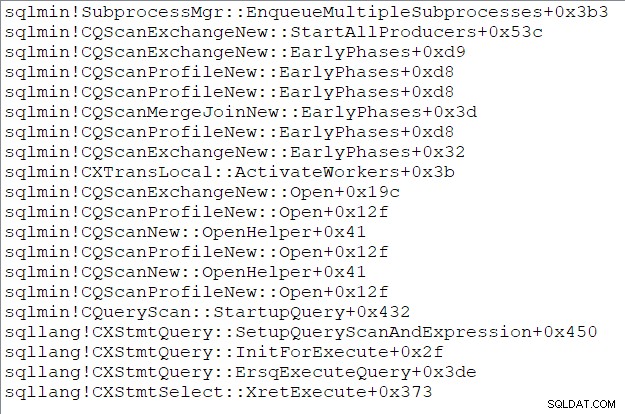
Slutningen af del tre
Vi har nu oprettet producentsiden af ompartitionsstrømmene udveksles ved node 5, skabte yderligere parallelle opgaver at køre Branch C, og linkede alt tilbage til forælder strukturer efter behov. Gren C er den første gren for at starte eventuelle parallelle opgaver. Den sidste del af denne serie vil se på gren C åbning i detaljer og starte de resterende parallelle opgaver.