Dette er den sidste del af en serie i fem dele, der tager et dybt dyk ned i den måde, hvorpå parallelle planer for SQL Server-rækketilstande begynder at blive eksekveret. Del 1 initialiserede udførelseskontekst nul for den overordnede opgave, og del 2 oprettede forespørgselsscanningstræet. Del 3 startede forespørgselsscanningen, udførte en tidlig fase behandling, og startede de første yderligere parallelle opgaver i gren C. Del 4 beskrev udvekslingssynkronisering og opstart af parallelle plangrene C &D.
Branch B Parallel Tasks Start
En påmindelse om grenene i denne parallelle plan (klik for at forstørre):
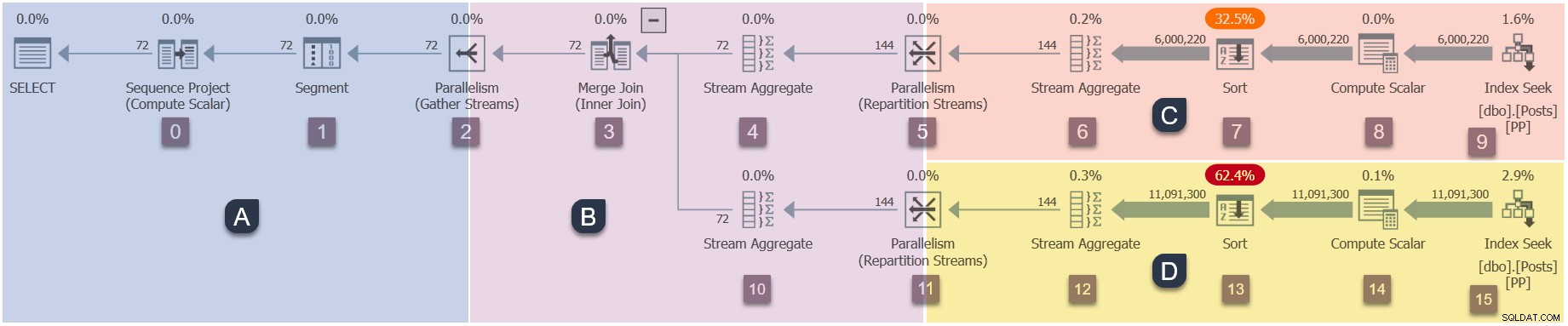
Dette er det fjerde trin i udførelsessekvensen:
- Afdeling A (overordnet opgave).
- Afdeling C (yderligere parallelle opgaver).
- Afdeling D (yderligere parallelle opgaver).
- Afdeling B (yderligere parallelle opgaver).
Den eneste tråd, der er aktiv lige nu (ikke suspenderet på CXPACKET ) er overordnet opgave , som er på forbrugersiden af omfordelingsstrømudvekslingen ved node 11 i afdeling B:
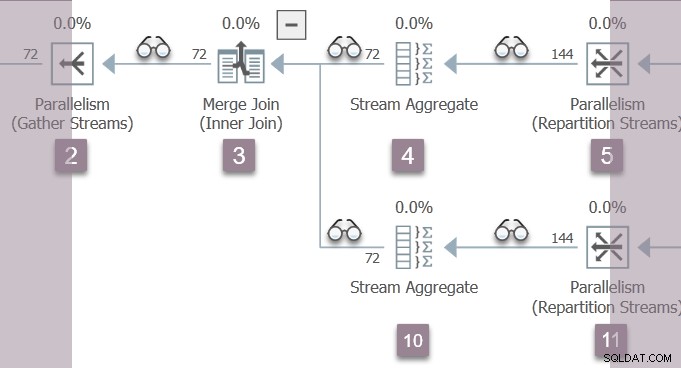
Den overordnede opgave vender nu tilbage fra indlejrede tidlige faser opkald, indstilling af forløbne og CPU-tider i profiler undervejs. Første og sidste aktive tidspunkt er ikke opdateret under den tidlige behandlingsfase. Husk, at disse tal bliver registreret mod udførelseskontekst nul – de parallelle opgaver i gren B eksisterer ikke endnu.
forældreopgaven stiger op træet fra node 11, gennem strømaggregatet ved node 10 og flettesammenføjningen ved node 3, tilbage til samlestrømsudvekslingen ved node 2.
Tidlig fasebehandling er nu færdig .
Med den originale EarlyPhases ring til node 2 saml strømme bytte endelig afsluttet, vender den overordnede opgave tilbage til at åbne den pågældende central (du kan næsten huske det opkald lige fra starten af denne serie). Den åbne metode ved node 2 kalder nu CQScanExchangeNew::StartAllProducers for at oprette de parallelle opgaver for afdeling B.
forældreopgaven nu venter på CXPACKET hos forbrugeren side af noden 2 saml strømme udveksling. Denne ventetid vil fortsætte, indtil de nyoprettede Branch B-opgaver har fuldført deres indlejrede Open opkald og vendte tilbage for at fuldføre åbningen af producentsiden af samlestrømbørsen.
Branch B parallelle opgaver åbne
De to nye parallelle opgaver i afdeling B starter hos producenten side af noden 2 saml strømme udveksling. Efter den sædvanlige rækketilstand iterative udførelsesmodel kalder de:
CQScanXProducerNew::Open(node 2 producent side åben).CQScanProfileNew::Open(profiler for node 3).CQScanMergeJoinNew::Open(node 3 flet sammenføjning).CQScanProfileNew::Open(profiler for node 4).CQScanStreamAggregateNew::Open(node 4-strømaggregat).CQScanProfileNew::Open(profiler for node 5).CQScanExchangeNew::Open(omfordelingsstrømme udveksles).
De parallelle opgaver følger begge det ydre (øvre) input til flettesammenføjningen, ligesom den tidlige fasebehandling gjorde.
Fuldførelse af udvekslingen
Når Branch B-opgaverne ankommer til forbrugeren side af omopdelingsstrømmene udveksles ved node 5, hver opgave:
- Registrerer med udvekslingsporten (
CXPort). - Opretter rørene (
CXPipe), der forbinder denne opgave med en eller flere producentsideopgaver (afhængig af udvekslingstype). Den nuværende central er en omfordelingsstrøm, så hver forbrugeropgave har to rør (ved DOP 2). Hver forbruger kan modtage rækker fra en af de to producenter. - Tilføjer en
CXPipeMergefor at flette rækker fra flere rør (da dette er en ordrebevarende udveksling). - Opretter rækkepakker (forvirrende navngivet
CXPacket) bruges til flowstyring og til at buffere rækker på tværs af udvekslingsrørene. Disse tildeles fra tidligere tildelt forespørgselshukommelse.
Når begge parallelle opgaver på forbrugersiden har fuldført dette arbejde, er node 5-udvekslingen klar til at gå. De to forbrugere (i Branch B) og de to producenter (i Branch C) har alle åbnet udvekslingsporten, så node 5 CXPACKET venter ende .
Checkpoint
Som tingene ser ud:
- Overordnet opgave i Afdeling A venter på
CXPACKETpå forbrugersiden af noden 2 samler strømme udveksling. Denne ventetid fortsætter, indtil begge node 2-producenter vender tilbage og åbner børsen. - De to parallelle opgaver i Brench B er kørbare . De har netop åbnet forbrugersiden af omfordelingsstrømudvekslingen ved node 5.
- De to parallelle opgaver i Afdeling C er netop blevet frigivet fra deres
CXPACKETvent, og er nu kørbare . De to strømaggregater ved node 6 (én pr. parallel opgave) kan begynde at aggregere rækker fra de to sorteringer ved node 7. Husk at indekssøgningerne ved node 9 lukkede for nogen tid siden, da sorteringerne afsluttede deres inputfase. - De to parallelle opgaver i Afdeling D er venter på
CXPACKETpå producentsiden af opdelingen udveksles strømme ved node 11. De venter på, at forbrugersiden af node 11 åbnes af de to parallelle opgaver i Branch B. Indekssøgningerne er lukket ned, og sorteringerne er klar til overgang til deres udgangsfase.
Flere aktive grene
Det er første gang, vi har haft flere grene (B og C) aktive på samme tid, hvilket kunne være udfordrende at diskutere. Heldigvis er designet af demo-forespørgslen sådan, at stream-aggregaterne i gren C kun vil producere nogle få rækker. Det lille antal smalle outputrækker passer nemt ind i rækkepakkens buffere ved node 5 udveksles opdelingsstrømme. Branch C-opgaverne kan derfor komme videre med deres arbejde (og i sidste ende lukke ned) uden at vente på, at node 5-omfordelingsstreams-forbrugersiden henter rækker.
Det betyder bekvemt, at vi kan lade de to parallelle opgaver i Branch C køre i baggrunden uden at bekymre os om dem. Vi behøver kun at bekymre os om, hvad de to parallelle opgaver i Branch B gør.
Afdeling B-åbning fuldført
En påmindelse om afdeling B:
De to parallelle arbejdere i gren B vender tilbage fra deres Open opkald på node 5 omfordelingsstreams udveksling. Dette fører dem tilbage gennem stream-aggregatet ved node 4, til flettesammenføjningen ved node 3.
Fordi vi stiger op træet i Open metoden, optager profilerne over node 5 og node 4 sidst aktive tid, samt akkumulering af forløbne og CPU-tider (pr. opgave). Vi udfører ikke tidlige faser på den overordnede opgave nu, så tallene, der er registreret for udførelseskontekst nul, påvirkes ikke.
Ved sammenfletningen begynder de to parallelle opgaver i gren B faldende det indre (nedre) input, der fører dem gennem strømaggregatet ved node 10 (og et par profiler) til forbrugersiden af opdelingsstrømmens udveksling ved node 11.
Afdeling D genoptager udførelse
En gentagelse af gren C-begivenhederne ved node 5 forekommer nu ved node 11-omfordelingsstrømmene. Forbrugersiden af node 11-udvekslingen er afsluttet og åbnet. De to producenter i Branch D afslutter deres CXPACKET venter og bliver kørbar en gang til. Vi vil lade Branch D-opgaverne køre i baggrunden og placere deres resultater i udvekslingsbuffere.
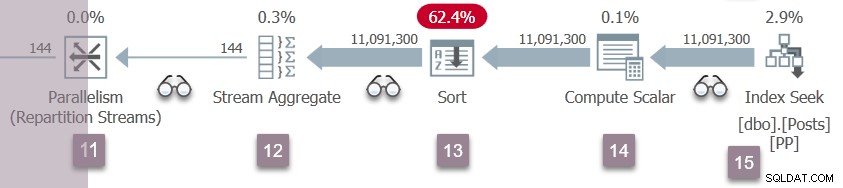
Der er nu seks parallelle opgaver (to hver i grenene B, C og D) deler tid i fællesskab på de to planlæggere, der er tildelt yderligere parallelle opgaver i denne forespørgsel.
Afdeling A er fuldført
De to parallelle opgaver i gren B vender tilbage fra deres Open opkald på node 11-omfordelingsstrømme, op forbi node 10-strømaggregatet, gennem flette-sammenføjningen ved node 3 og tilbage til producentsiden af samle-strømmene ved node 2. Profiler sidst aktive og akkumulerede forløbne &CPU-tider opdateres, når vi stiger op i træet i indlejret Open metoder.
Hos producenten siden af samlestrømsudvekslingen, synkroniserer de to parallelle opgaver i Branch B ved at åbne udvekslingsporten, og vent derefter på CXPACKET for forbrugersiden at åbne.
forældreopgaven venter på forbrugersiden af samlestrømmene er nu frigivet fra dens CXPACKET vente, hvilket gør det muligt at fuldføre åbningen af udvekslingsporten på forbrugersiden. Dette frigør igen producenterne fra deres (korte) CXPACKET vente. Node 2-indsamlingsstrømmene er nu blevet åbnet af alle ejere.
Fuldførelse af forespørgselsscanningen
forældreopgaven stiger nu op i forespørgselsscanningstræet fra samlestrømbørsen og vender tilbage fra Open opkald på centralen, segment og sekvensprojekt operatører i afdeling A.
Dette fuldender åbningen forespørgselsscanningstræet, initieret alt dette for længe siden ved opkaldet til CQueryScan::StartupQuery . Alle grene af parallelplanen er nu begyndt at udføre.
Returnerende rækker
Udførelsesplanen er klar til at begynde at returnere rækker som svar på GetRow opkald ved roden af forespørgselsscanningstræet, initieret af et opkald til CQueryScan::GetRow . Jeg vil ikke gå i detaljer, da det er strengt uden for rammerne af en artikel om, hvordan parallelle planer starter op .
Alligevel er den korte sekvens:
- Den overordnede opgave kalder
GetRowpå sekvensprojektet, som kalderGetRowpå segmentet, som kalderGetRowpå forbrugeren side af samle-strømme udveksling. - Hvis der endnu ikke er nogen rækker tilgængelige på børsen, venter den overordnede opgave på
CXCONSUMER. - I mellemtiden har de uafhængigt kørende gren B parallelle opgaver rekursivt kaldet
GetRowstarter ved producenten side af samle-strømme udveksling. - Rækker leveres til gren B af forbrugersiden af omfordelingsstrømudvekslingerne ved node 5 og 12.
- Gren C og D behandler stadig rækker fra deres sortering gennem deres respektive strømaggregater. Filial B-opgaver skal muligvis vente på
CXCONSUMERved omopdelingsstrømme node 5 og 12, så en komplet række rækker bliver tilgængelige. - Rækker, der dukker op fra den indlejrede
GetRowopkald i gren B samles til rækkepakker hos producenten side af samle-strømme udveksling. - Overordnet opgaves
CXCONSUMERvent på forbrugersiden af samlestrømmene slutter, når en pakke bliver tilgængelig. - En række ad gangen behandles derefter gennem de overordnede operatører i gren A og til sidst videre til klienten.
- Til sidst løber rækkerne ud, og en indlejret
Closeopkaldet bølger ned af træet, på tværs af centralerne, og parallel udførelse slutter.
Opsummering og afsluttende bemærkninger
Først en oversigt over udførelsessekvensen for denne særlige parallelle udførelsesplan:
- Den overordnede opgave åbner gren A . Tidlig fase behandlingen begynder ved udvekslingen af samlestrømme.
- Opkald i den tidlige fase af forældreopgaven går ned i scanningstræet til indekssøgningen ved node 9, og stiger derefter tilbage til genpartitioneringsudvekslingen ved node 5.
- Den overordnede opgave starter parallelle opgaver for gren C , og venter derefter, mens de læser alle tilgængelige rækker ind i de blokerende sorteringsoperatorer ved node 7.
- Tidlige faseopkald stiger op til flettesammenføjningen og går derefter ned i det indre input til centralen ved node 11.
- Opgaver for Afdeling D startes ligesom for gren C, mens den overordnede opgave venter ved node 11.
- Tidlige fasekald vender tilbage fra node 11 så langt som samlestrømmene. Den tidlige fase slutter her.
- Den overordnede opgave opretter parallelle opgaver for Brench B , og venter, indtil åbningen af gren B er fuldført.
- Gren B-opgaver når node 5 ompartitionsstrømmene, synkroniserer, fuldfører udvekslingen og frigiver Branch C-opgaver for at begynde at aggregere rækker fra sorteringerne.
- Når Branch B-opgaver når node 12 ompartitionsstrømmene, synkroniserer de, fuldfører udvekslingen og frigiver Branch D-opgaver for at begynde at aggregere rækker fra sorteringen.
- Gren B-opgaver vender tilbage til indsamlingsstrømmene udveksler og synkroniseres, hvilket frigiver den overordnede opgave fra ventetiden. Den overordnede opgave er nu klar til at starte processen med at returnere rækker til klienten.
Du vil måske gerne se udførelsen af denne plan i Sentry One Plan Explorer. Sørg for at aktivere indstillingen "Med Live-forespørgselsprofil" for indsamling af faktisk plan. Det gode ved at udføre forespørgslen direkte i Plan Explorer er, at du vil være i stand til at gå gennem flere optagelser i dit eget tempo og endda spole tilbage. Det vil også vise en grafisk oversigt over I/O, CPU og venter synkroniseret med profildataene for live-forespørgsler.
Yderligere bemærkninger
Opstigning i forespørgselsscanningstræet under behandling i den tidlige fase sætter første og sidste aktive tidspunkter ved hver profileringsiterator for den overordnede opgave, men akkumulerer ikke forløbet tid eller CPU-tid. Går op i træet under Open og GetRow kalder på en parallel opgave angiver sidste aktive tid og akkumulerer forløbet tid og CPU-tid ved hver profilerings-iterator pr. opgave.
Behandling i tidlig fase er specifik for parallelle planer i rækketilstand. Det er nødvendigt at sikre, at udvekslinger initialiseres i den rigtige rækkefølge, og at alt parallelt maskineri fungerer korrekt.
Forældreopgaven udfører ikke altid hele den tidlige fasebearbejdning. Tidlige faser starter ved en rodudveksling, men hvordan disse opkald navigerer i træet afhænger af de iteratorer, der stødes på. Jeg valgte en sammenføjning til denne demo, fordi den tilfældigvis kræver behandling i tidlig fase for begge input.
Tidlige faser ved (for eksempel) en parallel hash-sammenføjning forplanter sig kun ned i build-inputtet. Når hash-forbindelsen går over til dens probefase, åbner den iteratorer på det input, inklusive eventuelle udvekslinger. Endnu en runde med tidlig fasebehandling igangsættes, håndteret af (præcis) en af de parallelle opgaver, der spiller rollen som overordnet opgave.
Når behandling i tidlig fase støder på en parallel gren, der indeholder en blokerende iterator, starter den de yderligere parallelle opgaver for den gren og venter på, at disse producenter fuldfører deres åbningsfase. Den gren kan også have undergrene, som håndteres på samme måde, rekursivt.
Nogle grene i en parallelplan i rækketilstand kan være påkrævet for at køre på en enkelt tråd (f.eks. på grund af et globalt aggregat eller top). Disse 'serielle zoner' kører også på en ekstra 'parallel' opgave, den eneste forskel er, at der kun er én opgave, udførelseskontekst og arbejder for den gren. Tidlig fasebehandling fungerer på samme måde uanset antallet af opgaver, der er tildelt en filial. For eksempel rapporterer en 'seriel zone' timings for den overordnede opgave (eller en parallel opgave, der spiller den rolle) såvel som den enkelte ekstra opgave. Dette viser sig i showplan som data for "tråd 0" (tidlige faser) såvel som "tråd 1" (tillægsopgaven).
Afsluttende tanker
Alt dette repræsenterer bestemt et ekstra lag af kompleksitet. Afkastet af denne investering er brug af runtime-ressourcer (primært tråde og hukommelse), reducerede synkroniseringsventer, øget gennemløb, potentielt nøjagtige ydeevnemålinger og en minimeret chance for parallelle deadlocks inden for forespørgsler.
Selvom rækketilstands-parallelisme stort set er blevet overskygget af den mere moderne batch-mode parallel eksekveringsmotor, har rækketilstandsdesignet stadig en vis skønhed. De fleste iteratorer kommer til at lade som om, de stadig kører i en seriel plan, med næsten al synkronisering, flowkontrol og planlægning håndteret af udvekslingerne. Den omhu og opmærksomhed, der er tydelig i implementeringsdetaljer som tidlig fasebehandling, gør det muligt for selv de største parallelle planer at udføre succesfuldt, uden at forespørgselsdesigneren tænker for meget over de praktiske vanskeligheder.