Længe forbi er de dage, hvor en database blev implementeret som en enkelt node eller instans - en kraftfuld, selvstændig server, som havde til opgave at håndtere alle anmodninger til databasen. Vertikal skalering var vejen at gå - udskift serveren med en anden, endnu mere kraftfuld. I disse tider behøvede man ikke rigtig at være generet af netværkets ydeevne. Så længe anmodningerne kom ind, var alt godt.
Men i dag er databaser bygget som klynger med noder forbundet over et netværk. Det er ikke altid et hurtigt, lokalt netværk. Med virksomheder, der når global skala, skal databaseinfrastruktur også spænde over hele kloden, for at forblive tæt på kunderne og for at reducere latens. Det kommer med yderligere udfordringer, som vi skal stå over for, når vi designer et meget tilgængeligt databasemiljø. I dette blogindlæg vil vi se nærmere på de netværksproblemer, du kan komme ud for, og give nogle forslag til, hvordan du kan håndtere dem.
To hovedmuligheder for MySQL eller MariaDB HA
Vi dækkede dette særlige emne ret omfattende i et af hvidbøgerne, men lad os se på de to vigtigste måder at opbygge høj tilgængelighed for MySQL og MariaDB på.
Galera-klynge
Galera Cluster er delt-intet, praktisk talt synkron klyngeteknologi til MySQL. Det giver mulighed for at bygge multi-writer opsætninger, der kan strække sig over hele kloden. Galera trives i miljøer med lav latency, men den kan også konfigureres til at fungere med lange WAN-forbindelser. Galera har en indbygget kvorummekanisme, som sikrer, at data ikke bliver kompromitteret i tilfælde af netværksopdeling af nogle af noderne.
MySQL-replikering
MySQL-replikering kan være enten asynkron eller semi-synkron. Begge er designet til at bygge storskala replikeringsklynger. Som i enhver anden master-slave eller primær-sekundær replikeringsopsætning kan der kun være én forfatter, masteren. Andre noder, slaver, bruges til failover-formål, da de indeholder kopien af datasættet fra maseren. Slaver kan også bruges til at læse dataene og fjerne noget af arbejdsbyrden fra masteren.
Begge løsninger har deres egne grænser og funktioner, begge lider af forskellige problemer. Begge kan blive påvirket af ustabile netværksforbindelser. Lad os tage et kig på disse begrænsninger, og hvordan vi kan designe miljøet for at minimere påvirkningen af en ustabil netværksinfrastruktur.
Galera Cluster - Netværksproblemer
Lad os først tage et kig på Galera Cluster. Som vi diskuterede, fungerer det bedst i et miljø med lav latency. Et af de største latency-relaterede problemer i Galera er måden, hvorpå Galera håndterer skrivningerne. Vi vil ikke gå ind i alle detaljerne i denne blog, men læse mere i vores Galera Cluster til MySQL tutorial. Den nederste linje er, at på grund af certificeringsprocessen for skrivninger, hvor alle noder i klyngen skal blive enige om, hvorvidt skrivningen kan anvendes eller ej, er din skriveydeevne for enkelt række strengt begrænset af netværkets rundturstid mellem skribenten node og den længst væk node. Så længe latensen er acceptabel, og så længe du ikke har for mange hot spots i dine data, kan WAN-opsætninger fungere fint. Problemet starter, når netværksforsinkelsen stiger fra tid til anden. Skrivninger vil derefter tage 3 eller 4 gange længere end normalt, og som et resultat kan databaser begynde at blive overbelastet med langvarige skrivninger.
En af de store funktioner ved Galera Cluster er dens evne til at registrere klyngetilstanden og reagere på netværksopdeling. Hvis en node i klyngen ikke kan nås, vil den blive smidt ud af klyngen, og den vil ikke være i stand til at udføre nogen skrivninger. Dette er afgørende for at bevare dataenes integritet i det tidsrum, hvor klyngen er opdelt - kun størstedelen af klyngen vil acceptere skrivninger. Mindretallet vil klage. For at håndtere dette introducerer Galera en bred vifte af kontroller og konfigurerbare timeouts for at undgå falske advarsler om meget forbigående netværksproblemer. Desværre, hvis netværket er upålideligt, vil Galera Cluster ikke være i stand til at fungere korrekt - noder vil begynde at forlade klyngen, slutte sig til den senere. Det vil især være problematisk, når vi har Galera Cluster, der spænder over WAN - adskilte dele af klyngen kan forsvinde tilfældigt, hvis det sammenkoblede netværk ikke fungerer korrekt.
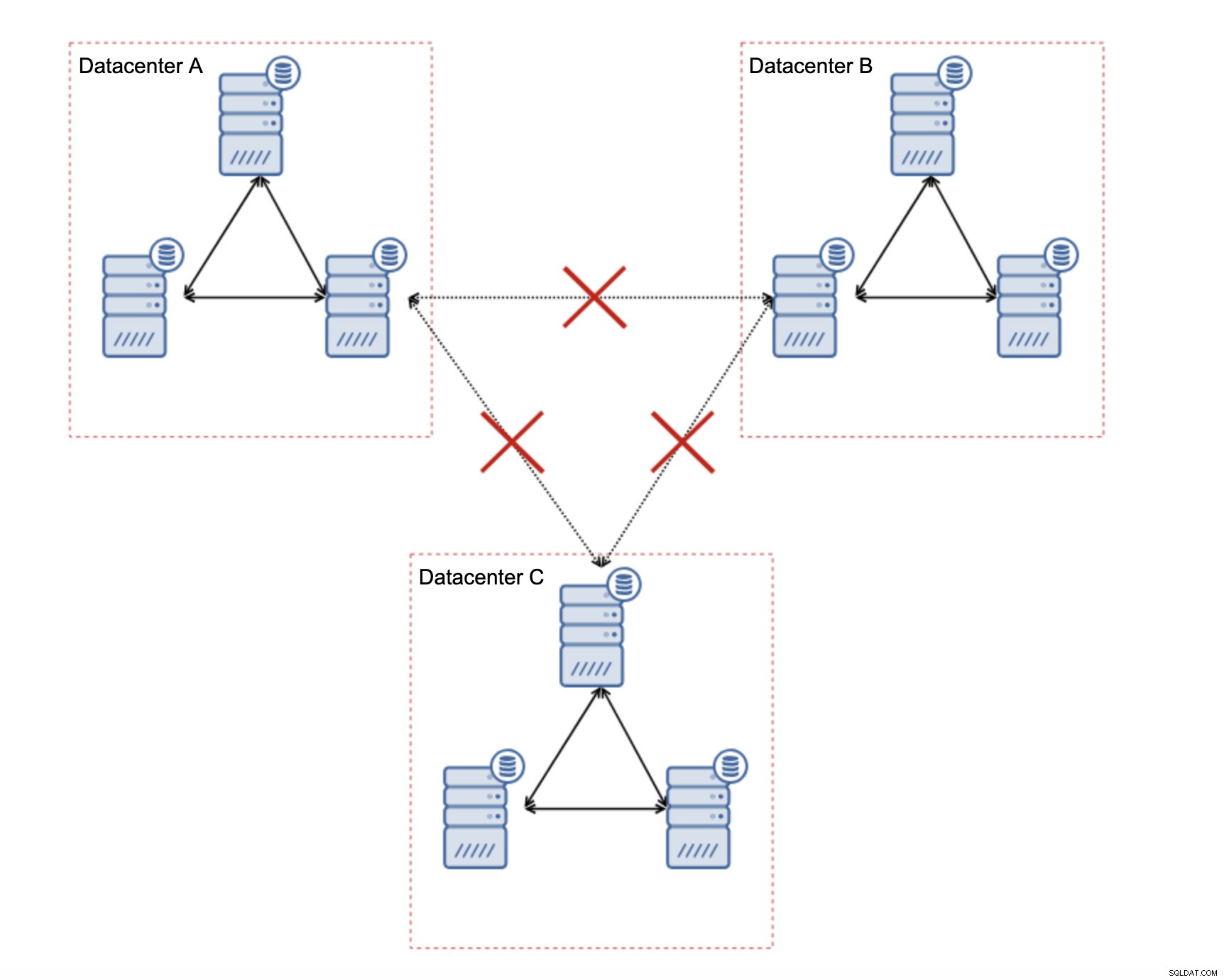
Hvordan designes Galera Cluster til et ustabilt netværk?
Først og fremmest, hvis du har netværksproblemer i det enkelte datacenter, er der ikke meget du kan gøre, medmindre du vil være i stand til at løse disse problemer på en eller anden måde. Upålideligt lokalt netværk er en no go for Galera Cluster, du er nødt til at genoverveje at bruge en anden løsning (selvom, for at være ærlig, vil upålidelig netværk altid være et problem). På den anden side, hvis problemerne kun er relateret til WAN-forbindelser (og dette er et af de mest typiske tilfælde), kan det være muligt at erstatte WAN Galera-links med almindelig asynkron replikering (hvis Galera WAN-tuning ikke hjalp).
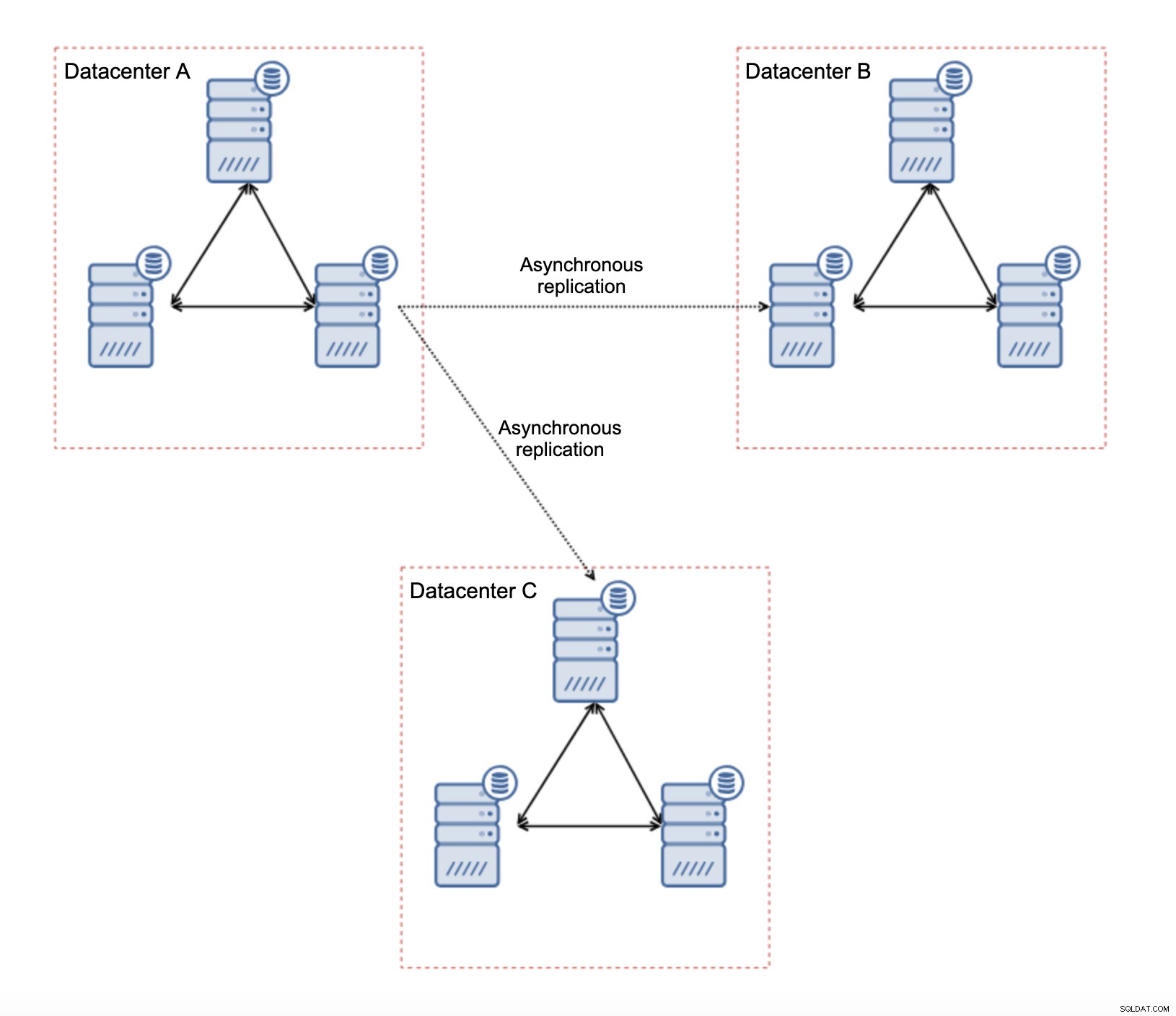
Der er flere iboende begrænsninger i denne opsætning - hovedproblemet er, at skrivningerne plejede at ske lokalt. Nu skal alle skrivninger gå til "master" datacenteret (DC A i vores tilfælde). Dette er ikke så slemt, som det lyder. Vær venligst opmærksom på, at i et al-Galera-miljø vil skrivninger blive bremset af latensen mellem noder placeret i forskellige datacentre. Selv lokale skriverier vil blive påvirket. Det vil være mere eller mindre den samme afmatning som med asynkron opsætning, hvor du ville sende skrivningerne på tværs af WAN til "master" datacenteret.
Brug af asynkron replikering kommer med alle de problemer, der er typiske for den asynkrone replikering. Replikationsforsinkelse kan blive et problem - ikke at Galera ville være mere effektiv, det er bare at Galera ville bremse trafikken via flowkontrol, mens replikering ikke har nogen mekanisme til at drosle trafikken på masteren.
Et andet problem er failoveren:hvis "master" Galera-knuden (den, der fungerer som master for slaverne i andre datacentre) ville fejle, skal der oprettes en eller anden mekanisme for at omdirigere slaver til en anden, fungerende masterknude. Det kan være en slags script, det er også muligt at prøve noget med VIP, hvor "slaven" Galera-klyngen aftager Virtual IP, som altid er tildelt den levende Galera-knude i "master"-klyngen.
Den største fordel ved en sådan opsætning er, at vi fjerner WAN Galera-linket, hvilket betyder, at vores "master"-klynge ikke bliver bremset af det faktum, at nogle af noderne er adskilt geografisk. Som vi nævnte, mister vi evnen til at skrive i alle datacentrene, men latensmæssig skrivning på tværs af WAN er det samme som at skrive lokalt til Galera-klyngen, som spænder over WAN. Som et resultat burde den overordnede latenstid forbedres. Asynkron replikering er også mindre sårbar over for de ustabile netværk. I værste fald vil replikeringslinket bryde, og det vil blive genskabt, når netværkene konvergerer.
Hvordan designes MySQL-replikering til et ustabilt netværk?
I det foregående afsnit dækkede vi Galera-klyngen, og en løsning var at bruge asynkron replikering. Hvordan ser det ud i en almindelig asynkron replikeringsopsætning? Lad os se på, hvordan et ustabilt netværk kan forårsage de største forstyrrelser i replikeringsopsætningen.
Først og fremmest latency - et af de vigtigste smertepunkter for Galera Cluster. I tilfælde af replikering er det næsten et ikke-problem. Medmindre du bruger semi-synkron replikering, dvs. - i et sådant tilfælde vil øget latens bremse nedskrivningen. I asynkron replikering har latens ingen indflydelse på skriveydelsen. Det kan dog have en vis indflydelse på replikationsforsinkelsen. Det er ikke noget så vigtigt, som det var for Galera, men du kan forvente flere forsinkelsesspidser og generelt mindre stabil replikeringsydelse, hvis netværket mellem noder lider af høj latenstid. Dette skyldes for det meste, at masteren lige så godt kan betjene flere skrivninger, før dataoverførsel til slaven kan startes på netværk med høj latency.
Netværkets ustabilitet kan helt sikkert påvirke replikeringslinks, men det er igen ikke så kritisk. MySQL-slaver vil forsøge at genoprette forbindelse til deres mastere, og replikering vil begynde.
Hovedproblemet med MySQL-replikering er faktisk noget, som Galera Cluster løser internt - netværkspartitionering. Vi taler om netværksopdelingen som den tilstand, hvor segmenter af netværket er adskilt fra hinanden. MySQL-replikering bruger én enkelt writer node - master. Uanset hvordan du designer dit miljø, skal du sende dine skrifter til mesteren. Hvis masteren ikke er tilgængelig (af en eller anden årsag), kan applikationen ikke udføre sit job, medmindre den kører i en slags skrivebeskyttet tilstand. Derfor er der behov for at vælge den nye master så hurtigt som muligt. Det er her, problemerne dukker op.
For det første, hvordan man fortæller, hvilken vært der er en mester, og hvilken der ikke er. En af de sædvanlige måder er at bruge "read_only"-variablen til at skelne slaver fra masteren. Hvis noden har read_only aktiveret (set read_only=1), er den en slave (da slaver ikke skal håndtere direkte skrivninger). Hvis noden er read_only deaktiveret (set read_only=0), er det en master. For at gøre tingene mere sikre er en almindelig tilgang at indstille read_only=1 i MySQL-konfiguration - i tilfælde af en genstart er det mere sikkert, hvis noden dukker op som en slave. Sådant "sprog" kan forstås af proxyer som ProxySQL eller MaxScale.
Lad os tage et kig på et eksempel.
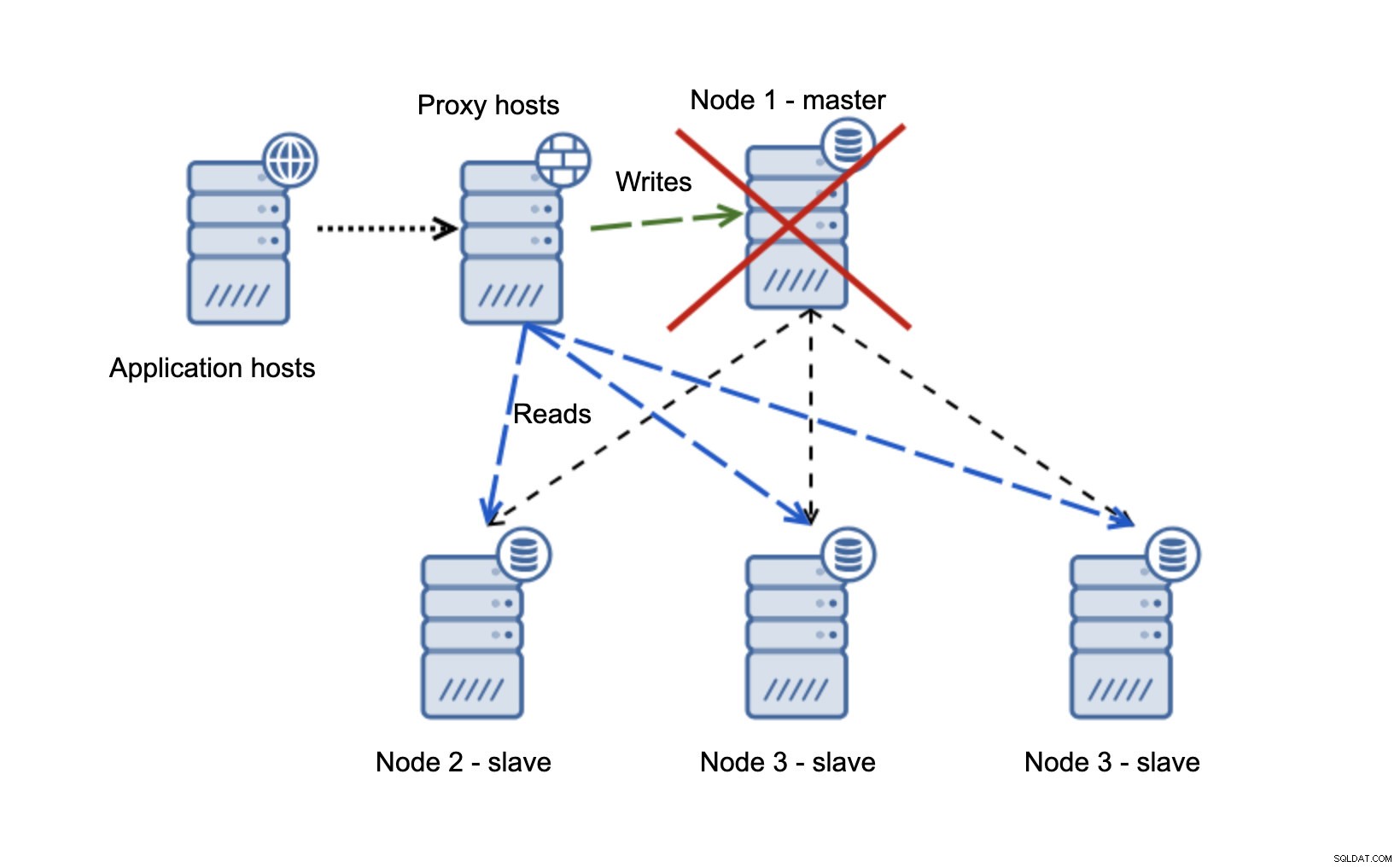
Vi har applikationsværter, som forbinder til proxy-laget. Proxyer udfører læse/skrive-splitningen og sender SELECT'er til slaver og skriver til master. Hvis master er nede, udføres failover, ny master fremmes, proxy-laget registrerer det og begynder at sende skrivninger til en anden node.
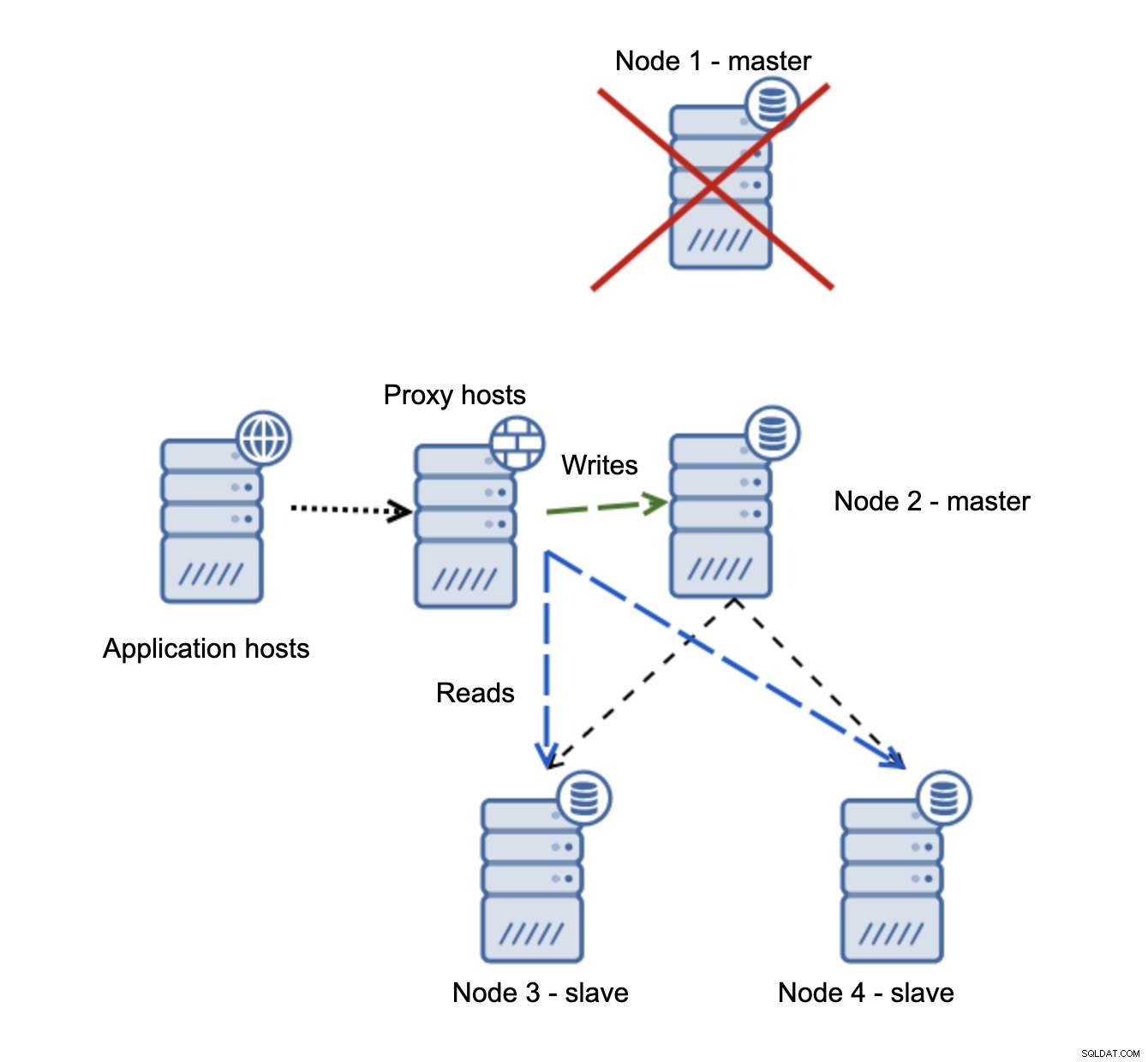
Hvis node1 genstarter, vil den komme med read_only=1, og den vil blive registreret som en slave. Det er ikke ideelt, da det ikke replikerer, men det er acceptabelt. Ideelt set bør den gamle mester slet ikke dukke op, før den er genopbygget og slaveret af den nye mester.
En meget mere problematisk situation er, hvis vi skal håndtere netværkspartitionering. Lad os overveje den samme opsætning:applikationsniveau, proxyniveau og databaser.
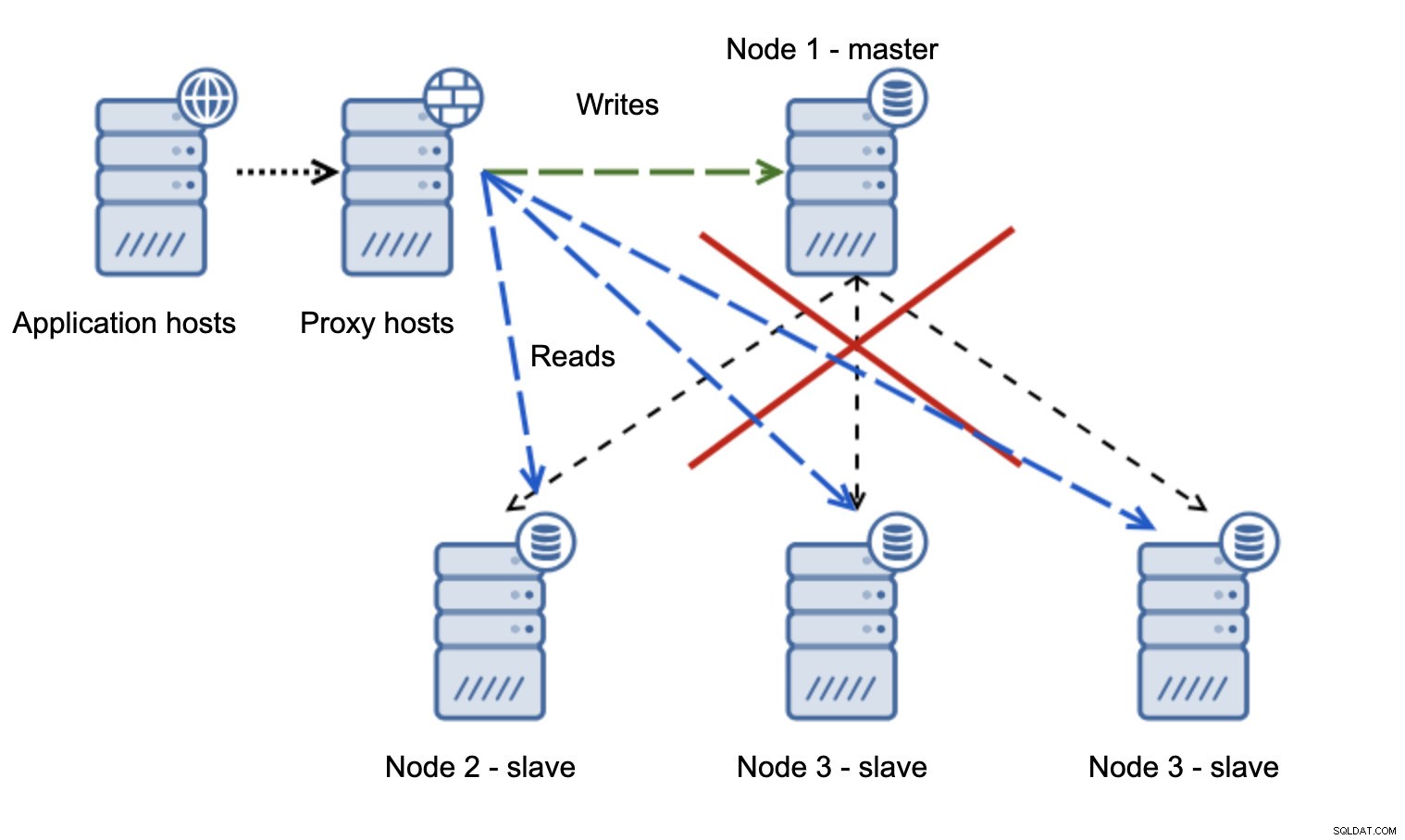
Når netværket gør, at masteren ikke kan nås, er applikationen ikke brugbar, da ingen skriver kommer til deres destination. Ny mester forfremmes, skrivere omdirigeres til den. Hvad vil der så ske, hvis netværksproblemerne ophører, og den gamle master bliver tilgængelig? Det er ikke blevet stoppet, derfor bruger det stadig read_only=0:
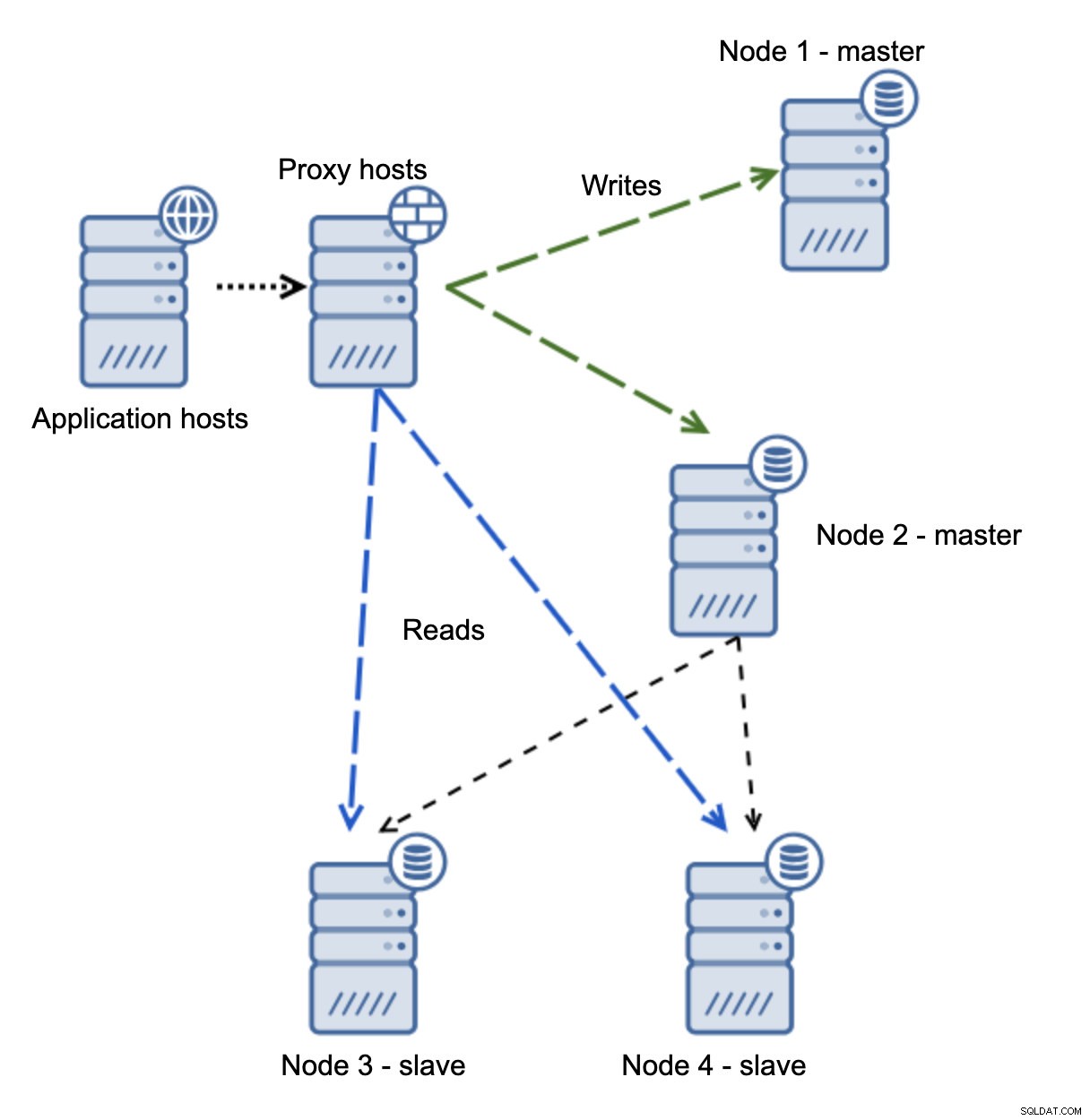
Du er nu havnet i en splittet hjerne, da skrivninger blev rettet til to noder. Denne situation er ret dårlig, da det kan tage et stykke tid at flette divergerende datasæt, og det er en ret kompleks proces.
Hvad kan man gøre for at undgå dette problem? Der er ingen sølvkugle, men nogle handlinger kan tages for at minimere sandsynligheden for, at en splittet hjerne sker.
Først og fremmest kan du være smartere til at registrere masterens tilstand. Hvordan ser slaverne det? Kan de kopiere fra det? Måske kan nogle af slaverne stadig oprette forbindelse til masteren, hvilket betyder at masteren er i gang eller i det mindste gør det muligt at stoppe den, hvis det skulle være nødvendigt. Hvad med proxy-laget? Ser alle proxynoder masteren som utilgængelig? Hvis nogle stadig kan oprette forbindelse, kan du så prøve at bruge disse noder til at ssh ind i masteren og stoppe den før failover?
Softwaren til failover-styring kan også være smartere til at registrere netværkets tilstand. Måske bruger den RAFT eller en anden klyngeprotokol til at bygge en kvorumsbevidst klynge. Hvis en failover-styringssoftware kan detektere den splittede hjerne, kan den også tage nogle handlinger baseret på dette, som for eksempel at indstille alle noder i det partitionerede segment til read_only at sikre, at den gamle master ikke vises som skrivbar, når netværkene konvergerer.
Du kan også inkludere værktøjer som Consul eller Etcd til at gemme klyngens tilstand. Proxylaget kan konfigureres til at bruge data fra Consul, ikke tilstanden for read_only-variablen. Det vil derefter være op til failover-styringssoftwaren at foretage nødvendige ændringer i Consul, så alle proxyer sender trafikken til en korrekt, ny master.
Nogle af disse tip kan endda kombineres for at gøre fejlregistreringen endnu mere pålidelig. Alt i alt er det muligt at minimere chancerne for, at replikeringsklyngen lider under upålidelige netværk.
Som du kan se, uanset om vi taler om Galera eller MySQL-replikering, kan ustabile netværk blive et alvorligt problem. På den anden side, hvis du designer miljøet rigtigt, kan du stadig få det til at fungere. Vi håber, at dette blogindlæg vil hjælpe dig med at skabe miljøer, der fungerer stabilt, selvom netværkene ikke er det.