Dengang SQL Server 2012 stadig var i beta, bloggede jeg om den nye FORMAT() funktion:SQL Server v.Next (Denali):CTP3 T-SQL-forbedringer:FORMAT().
På det tidspunkt var jeg så begejstret for den nye funktionalitet, at jeg ikke engang tænkte på at lave nogen præstationstest. Jeg adresserede dette i et nyere blogindlæg, men udelukkende i forbindelse med at fjerne tid fra et datetime:Trimning af tid fra datetime – en opfølgning.
I sidste uge troldede min gode ven Jason Horner (blog | @jasonhorner) mig med disse tweets:
| |
Mit problem med dette er bare at FORMAT() ser praktisk ud, men det er ekstremt ineffektivt sammenlignet med andre tilgange (oh og det AS VARCHAR ting er også dårligt). Hvis du laver dette enkeltvis og for små resultater, ville jeg ikke bekymre mig for meget om det; men i skala kan det blive ret dyrt. Lad mig illustrere med et eksempel. Lad os først oprette en lille tabel med 1000 pseudo-tilfældige datoer:
SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
Lad os nu prime cachen med data fra denne tabel og illustrere tre af de almindelige måder, folk har tendens til at præsentere netop tiden på:
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
Lad os nu udføre individuelle forespørgsler, der bruger disse forskellige teknikker. Vi kører dem hver 5 gange, og vi kører følgende varianter:
- Valg af alle 1.000 rækker
- Valger TOP (1) sorteret efter den klyngede indeksnøgle
- Tildeling til en variabel (som fremtvinger en fuld scanning, men forhindrer SSMS-gengivelse i at forstyrre ydeevnen)
Her er scriptet:
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
Nu kan vi måle ydeevnen med følgende forespørgsel (mit system er ret stille; på dit skal du muligvis udføre mere avanceret filtrering end blot execution_count ):
SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
Resultaterne i mit tilfælde var ret konsistente:
| Forespørgsel (trunkeret) | Varighed (mikrosekunder) | |||
|---|---|---|---|---|
| total_elapsed | avg_elapsed | total_clr | ||
| VÆLG 1.000 rækker | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_time output (klik for at forstørre):
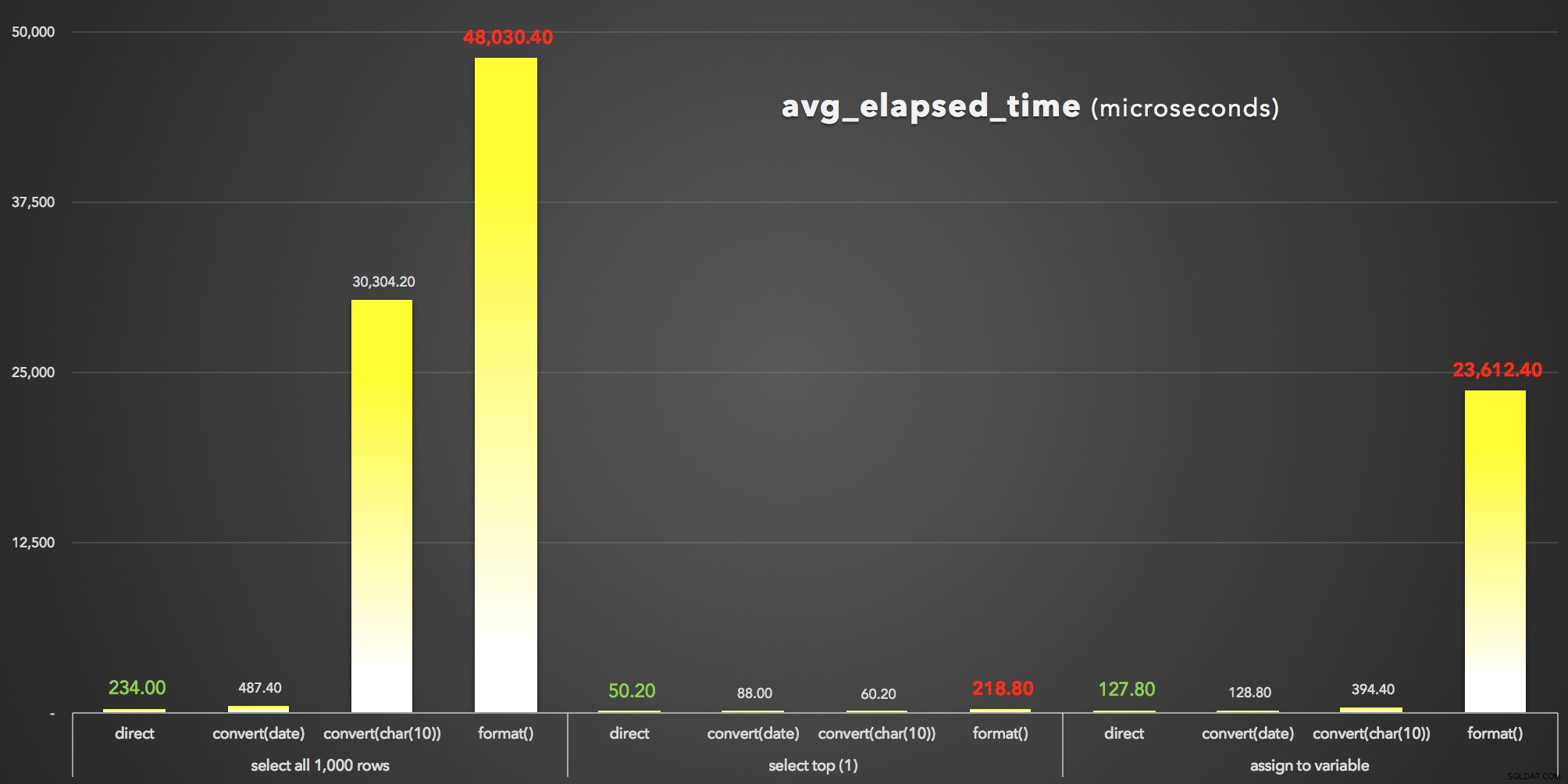 FORMAT() er klart taberen:resultater for avg_elapsed_time (mikrosekunder)
FORMAT() er klart taberen:resultater for avg_elapsed_time (mikrosekunder)
Hvad vi kan lære af disse resultater (igen):
- Først og fremmest
FORMAT()er dyrt . FORMAT()kan ganske vist give mere fleksibilitet og give mere intuitive metoder, der stemmer overens med dem på andre sprog som C#. Men ud over dets overhead, og mensCONVERT()stiltal er kryptiske og mindre udtømmende, du skal muligvis bruge den ældre tilgang alligevel, daFORMAT()er kun gyldig i SQL Server 2012 og nyere.- Selv standby
CONVERT()metode kan være drastisk dyr (dog kun alvorligt i det tilfælde, hvor SSMS skulle gengive resultaterne - den håndterer tydeligt strenge anderledes end datoværdier). - Bare at trække datetime-værdien direkte ud af databasen var altid mest effektivt. Du bør profilere, hvilken ekstra tid det tager for din ansøgning at formatere datoen som ønsket på præsentationsniveauet - det er højst sandsynligt, at du slet ikke vil have SQL Server til at involvere sig i prettying-formatet (og faktisk vil mange hævde at det er her den logik altid hører hjemme).
Vi taler kun om mikrosekunder her, men vi taler også kun om 1.000 rækker. Skaler det ud til dine faktiske tabelstørrelser, og virkningen af at vælge den forkerte formateringstilgang kan være ødelæggende.
Hvis du vil prøve dette eksperiment på din egen maskine, har jeg uploadet et eksempelscript:FormatIsNiceAndAllBut.sql_.zip