Denne artikel er 7. del af en serie om navngivne tabeludtryk. I del 5 og del 6 dækkede jeg de konceptuelle aspekter af almindelige tabeludtryk (CTE'er). I denne og næste måned drejer mit fokus sig mod optimeringsovervejelser af CTE'er.
Jeg vil starte med hurtigt at gense det uhyggelige koncept med navngivne tabeludtryk og demonstrere dets anvendelighed på CTE'er. Jeg vil derefter vende mit fokus til vedholdenhedsovervejelser. Jeg vil tale om persistens aspekter af rekursive og ikke-rekursive CTE'er. Jeg vil forklare, hvornår det giver mening at holde sig til CTE'er i forhold til hvornår det faktisk giver mere mening at arbejde med midlertidige tabeller.
I mine eksempler fortsætter jeg med at bruge eksempeldatabaserne TSQLV5 og PerformanceV5. Du kan finde scriptet, der opretter og udfylder TSQLV5 her, og dets ER-diagram her. Du kan finde scriptet, der opretter og udfylder PerformanceV5 her.
Udskiftning/unesting
I del 4 af serien, som fokuserede på optimering af afledte tabeller, beskrev jeg en proces med unnesting/substitution af tabeludtryk. Jeg forklarede, at når SQL Server optimerer en forespørgsel, der involverer afledte tabeller, anvender den transformationsregler på det indledende træ af logiske operatorer, der er produceret af parseren, hvilket muligvis flytter ting rundt på tværs af, hvad der oprindeligt var tabeludtryksgrænser. Dette sker i en sådan grad, at når du sammenligner en plan for en forespørgsel ved hjælp af afledte tabeller med en plan for en forespørgsel, der går direkte imod de underliggende basistabeller, hvor du selv har anvendt unnesting-logikken, ser de ens ud. Jeg beskrev også en teknik til at forhindre unnesting ved at bruge TOP-filteret med et meget stort antal rækker som input. Jeg demonstrerede et par tilfælde, hvor denne teknik var ret praktisk – et hvor målet var at undgå fejl og et andet af optimeringshensyn.
TL;DR-versionen af substitution/unnesting af CTE'er er, at processen er den samme, som den er med afledte tabeller. Hvis du er tilfreds med denne erklæring, kan du være velkommen til at springe dette afsnit over og springe direkte til næste afsnit om Persistens. Du vil ikke gå glip af noget vigtigt, som du ikke har læst før. Men hvis du er ligesom mig, vil du sandsynligvis have bevis på, at det faktisk er tilfældet. Derefter vil du sandsynligvis fortsætte med at læse dette afsnit og teste koden, som jeg bruger, når jeg besøger de vigtigste eksempler, som jeg tidligere har demonstreret med afledte tabeller, og konverterer dem til at bruge CTE'er.
I del 4 demonstrerede jeg følgende forespørgsel (vi kalder det forespørgsel 1):
BRUG TSQLV5; SELECT orderid, orderdate FROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS WHERE ordredato>='20180401';
Forespørgslen involverer tre indlejringsniveauer af afledte tabeller plus en ydre forespørgsel. Hvert niveau filtrerer et andet interval af ordredatoer. Planen for forespørgsel 1 er vist i figur 1.
 Figur 1:Udførelsesplan for forespørgsel 1
Figur 1:Udførelsesplan for forespørgsel 1
Planen i figur 1 viser tydeligt, at unnesting af de afledte tabeller fandt sted, da alle filterprædikater blev slået sammen til et enkelt omfattende filterprædikat.
Jeg forklarede, at du kan forhindre unnesting-processen ved at bruge et meningsfuldt TOP-filter (i modsætning til TOP 100 PROCENT) med et meget stort antal rækker som input, som følgende forespørgsel viser (vi kalder det forespørgsel 2):
VÆLG ordre-id, ordredato FRA ( VÆLG TOP (9223372036854775807) * FRA ( VÆLG TOP (9223372036854775807) * FRA ( VÆLG TOP (9223372036854775807) * FRA (VÆLG TOP) 20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3 WHERE orderdate>='20180401';
Planen for forespørgsel 2 er vist i figur 2.
 Figur 2:Udførelsesplan for forespørgsel 2
Figur 2:Udførelsesplan for forespørgsel 2
Planen viser tydeligt, at unnesting ikke fandt sted, da du effektivt kan se de afledte tabelgrænser.
Lad os prøve de samme eksempler ved at bruge CTE'er. Her er forespørgsel 1 konverteret til at bruge CTE'er:
MED C1 AS ( VÆLG * FRA Salg. Ordrer HVOR ordredato>='20180101' ), C2 AS ( VÆLG * FRA C1 HVOR bestillingsdato>='20180201' ), C3 AS ( VÆLG * FRA C2 HVOR bestillingsdato>=' 20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Du får nøjagtig den samme plan som vist tidligere i figur 1, hvor du kan se, at udredning fandt sted.
Her er forespørgsel 2 konverteret til at bruge CTE'er:
MED C1 AS ( VÆLG TOP (9223372036854775807) * FRA Salg. Ordrer HVOR bestillingsdato>='20180101' ), C2 AS ( VÆLG TOP (9223372036854775807) * FRA VÆLG C1 WHERE'), 'FRA C1 WHERE', C1200 TOP (9223372036854775807) * FRA C2 WHERE ordredato>='20180301' ) VÆLG ordre-id, ordredato FRA C3 WHERE ordredato>='20180401';
Du får samme plan som vist tidligere i figur 2, hvor du kan se, at unnesting ikke fandt sted.
Lad os dernæst gense de to eksempler, som jeg brugte til at demonstrere det praktiske ved teknikken til at forhindre unnesting - kun denne gang ved at bruge CTE'er.
Lad os starte med den fejlagtige forespørgsel. Følgende forespørgsel forsøger at returnere ordrelinjer med en rabat, der er større end minimumsrabatten, og hvor den gensidige rabat er større end 10:
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount> (SELECT MIN(rabat) FROM Sales.OrderDetails) AND 1.0 / rabat> 10.0;
Minimumsrabatten kan ikke være negativ, men er snarere enten nul eller højere. Så du tænker sikkert, at hvis en række har en nulrabat, skal det første prædikat evalueres til falsk, og at en kortslutning skal forhindre forsøget på at evaluere det andet prædikat og dermed undgå en fejl. Men når du kører denne kode, får du en divider med nul fejl:
Besked 8134, niveau 16, tilstand 1, linje 99 Divider med nul fejl fundet.
Problemet er, at selvom SQL Server understøtter et kortslutningskoncept på det fysiske behandlingsniveau, er der ingen sikkerhed for, at den vil evaluere filterprædikaterne i skriftlig rækkefølge fra venstre mod højre. Et almindeligt forsøg på at undgå sådanne fejl er at bruge et navngivet tabeludtryk, der håndterer den del af filtreringslogikken, som du ønsker skal evalueres først, og få den ydre forespørgsel til at håndtere den filtreringslogik, som du ønsker skal evalueres som det andet. Her er den forsøgte løsning ved hjælp af en CTE:
MED C AS (VÆLG * FRA Salg.Ordredetaljer WHERE rabat> (VÆLG MIN(rabat) FRA Salg.Ordredetaljer) ) VÆLG orderid, productid, rabat FRA C WHERE 1,0 / rabat> 10,0;
Desværre resulterer ophævelsen af tabeludtrykket dog i en logisk ækvivalent til den oprindelige løsningsforespørgsel, og når du forsøger at køre denne kode, får du en divider med nul-fejl igen:
Besked 8134, niveau 16, tilstand 1, linje 108 Divider med nul fejl fundet.
Ved at bruge vores trick med TOP-filteret i den indre forespørgsel forhindrer du unnesting af tabeludtrykket, som sådan:
WITH C AS ( SELECT TOP (9223372036854775807) * FRA Sales.OrderDetails WHERE rabat> (VÆLG MIN(rabat) FRA Sales.OrderDetails) ) SELECT orderid, productid, rabat FROM C WHERE 1,0 / rabat> 10.0>Denne gang kører koden uden fejl.
Lad os gå videre til eksemplet, hvor du bruger teknikken til at forhindre unnesting af optimeringsgrunde. Følgende kode returnerer kun afsendere med en maksimal ordredato, der er den 1. januar 2018 eller senere:
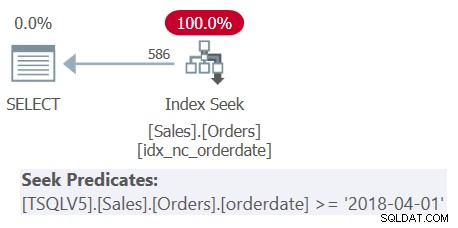
BRUG PerformanceV5; MED C AS ( VÆLG S.shipperid, (SELECT MAX(O.orderdate) FRA dbo.Orders AS O HVOR O.shipperid =S.shipperid) AS maxod FRA dbo.Shippers AS S ) VÆLG shipperid, maxod FRA C WHERE maxod> ='20180101';Hvis du undrer dig over, hvorfor ikke bruge en meget enklere løsning med en grupperet forespørgsel og et HAVING-filter, har det at gøre med tætheden af shipperid-kolonnen. Ordretabellen har 1.000.000 ordrer, og forsendelserne af disse ordrer blev håndteret af fem afsendere, hvilket betyder, at hver afsender i gennemsnit håndterede 20 % af ordrerne. Planen for en grupperet forespørgsel, der beregner den maksimale ordredato pr. afsender, vil scanne alle 1.000.000 rækker, hvilket resulterer i tusindvis af sidelæsninger. Faktisk, hvis du blot fremhæver CTE'ens indre forespørgsel (vi kalder det forespørgsel 3) ved at beregne den maksimale ordredato pr. afsender og kontrollere dens eksekveringsplan, vil du få planen vist i figur 3.
Figur 3:Udførelsesplan for forespørgsel 3
Planen scanner fem rækker i det grupperede indeks på afsendere. Pr. afsender anvender planen en søgning mod et dækkende indeks på ordrer, hvor (afsender, ordredato) er indeksets ledende nøgler, der går direkte til den sidste række i hver afsendersektion på bladniveau for at trække den maksimale ordredato for den aktuelle afsender. afsender. Da vi kun har fem afsendere, er der kun fem indekssøgningsoperationer, hvilket resulterer i en meget effektiv plan. Her er de præstationsmål, jeg fik, da jeg udførte CTE'ens indre forespørgsel:
varighed:0 ms, CPU:0 ms, læser:15Men når du kører den komplette løsning (vi kalder den forespørgsel 4), får du en helt anden plan, som vist i figur 4.
Figur 4:Udførelsesplan for forespørgsel 4
Det, der skete, er, at SQL Server fjernede tabeludtrykket og konverterede løsningen til en logisk ækvivalent af en grupperet forespørgsel, hvilket resulterede i en fuld scanning af indekset på ordrer. Her er de præstationstal, jeg fik for denne løsning:
varighed:316 ms, CPU:281 ms, læser:3854Det, vi har brug for her, er at forhindre unnesting af tabeludtrykket i at finde sted, så den indre forespørgsel ville blive optimeret med søgninger mod indekset på ordrer, og at den ydre forespørgsel blot resulterer i en tilføjelse af en Filter-operator i plan. Du opnår dette ved at bruge vores trick ved at tilføje et TOP-filter til den indre forespørgsel, som sådan (vi kalder denne løsning for forespørgsel 5):
MED C AS ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FRA dbo.Shippers AS S ) SELECT shipperid , maxod FRA C WHERE maxod>='20180101';Planen for denne løsning er vist i figur 5.
Figur 5:Udførelsesplan for forespørgsel 5
Planen viser, at den ønskede effekt blev opnået, og præstationstallene bekræfter derfor dette:
varighed:0 ms, CPU:0 ms, læser:15Så vores test bekræfter, at SQL Server håndterer substitution/unnesting af CTE'er ligesom det gør for afledte tabeller. Det betyder, at du ikke bør foretrække det ene frem for det andet på grund af optimeringsårsager, snarere på grund af begrebsmæssige forskelle, der betyder noget for dig, som diskuteret i del 5.
Vedholdenhed
En almindelig misforståelse angående CTE'er og navngivne tabeludtryk generelt er, at de fungerer som en slags persistensvehikel. Nogle tror, at SQL Server fortsætter resultatsættet af den indre forespørgsel til en arbejdstabel, og at den ydre forespørgsel faktisk interagerer med denne arbejdstabel. I praksis bliver almindelige ikke-rekursive CTE'er og afledte tabeller ikke vedvarende. Jeg beskrev den unnesting-logik, som SQL Server anvender ved optimering af en forespørgsel, der involverer tabeludtryk, hvilket resulterer i en plan, der interagerer lige med de underliggende basistabeller. Bemærk, at optimeringsværktøjet kan vælge at bruge arbejdstabeller til at bevare mellemliggende resultatsæt, hvis det giver mening at gøre det enten af ydeevnemæssige årsager eller andre, såsom Halloween-beskyttelse. Når den gør det, ser du Spool- eller Index Spool-operatører i planen. Sådanne valg er dog ikke relateret til brugen af tabeludtryk i forespørgslen.
Rekursive CTE'er
Der er et par undtagelser, hvor SQL Server bevarer tabeludtrykkets data. Den ene er brugen af indekserede visninger. Hvis du opretter et klynget indeks på en visning, bevarer SQL Server den indre forespørgsels resultatsæt i visningens klyngede indeks og holder det synkroniseret med eventuelle ændringer i de underliggende basistabeller. Den anden undtagelse er, når du bruger rekursive forespørgsler. SQL Server skal bevare de mellemliggende resultatsæt af ankeret og de rekursive forespørgsler i en spool, så den kan få adgang til sidste rundes resultatsæt repræsenteret af den rekursive reference til CTE-navnet, hver gang det rekursive medlem udføres.
For at demonstrere dette vil jeg bruge en af de rekursive forespørgsler fra del 6 i serien.
Brug følgende kode til at oprette tabellen Employees i tempdb-databasen, udfylde den med eksempeldata og oprette et understøttende indeks:
INDSTIL ANTAL TIL; BRUG tempdb; DROP TABEL HVIS FINNES dbo.Medarbejdere; GÅ OPRET TABEL dbo.Medarbejdere ( empid INT IKKE NULL BEGRÆNSNING PK_Employees PRIMÆR NØGLE, mgrid INT NULL BEGRÆNSNING FK_Employees_Employees REFERENCER dbo.Employees, employname VARCHAR(25)
NOLL MON NULL (NOT, løn IKKE MON NULL) (NOT, løn MON NULL) INSERT INTO dbo.Employees(empid, mgrid, empname, salary) VALUES(1, NULL, 'David' , $10000.00), (2, 1, 'Eitan' , $7000.00), (3, 1, 'Ina' , $7500.00) , (4, 2, 'Seraph' , $5000.00), (5, 2, 'Jiru' , $5500.00), (6, 2, 'Steve' , $4500.00), (7, 3, 'Aaron' , $5000.00), ( 8, 5, 'Lilach' , $3500.00), (9, 7, 'Rita' , $3000.00), (10, 5, 'Sean' , $3000.00), (11, 7, 'Gabriel', $3000.00), (12, 9, 'Emilia' , $2000,00), (13, 9, 'Michael', $2000,00), (14, 9, 'Didi', $1500,00); CREATE UNIQUE INDEX idx_unc_mgrid_empid ON dbo.Employees(mgrid, empid) INCLUDE(empname, salary); GÅJeg brugte følgende rekursive CTE til at returnere alle underordnede af en input-undertræ-rodmanager ved at bruge medarbejder 3 som input-manager i dette eksempel:
DECLARE @root AS INT =3; MED C AS ( VÆLG empid, mgrid, empname FRA dbo. Medarbejdere HVOR empid =@root UNION ALLE VÆLG S.empid, S.mgrid, S.empname FRA C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid ) VÆLG empid, mgrid, empname FRA C;Planen for denne forespørgsel (vi kalder den forespørgsel 6) er vist i figur 6.
Figur 6:Udførelsesplan for forespørgsel 6
Bemærk, at det allerførste, der sker i planen, til højre for rod SELECT-knuden, er oprettelsen af en B-træ-baseret arbejdstabel repræsenteret af Index Spool-operatoren. Den øverste del af planen håndterer ankermedlemmets logik. Det trækker input-medarbejderrækkerne fra det klyngede indeks på Medarbejdere og skriver det til spoolen. Den nederste del af planen repræsenterer det rekursive medlems logik. Det udføres gentagne gange, indtil det returnerer et tomt resultatsæt. Det ydre input til Nested Loops-operatøren henter managerne fra den foregående runde fra spolen (Table Spool-operatør). Det indre input bruger en Index Seek-operator mod et ikke-klynget indeks, der er oprettet på Employees(mgrid, empid) for at opnå de direkte underordnede af lederne fra den foregående runde. Resultatsættet for hver udførelse af den nederste del af planen skrives også til indeksspolen. Bemærk, at der i alt blev skrevet 7 rækker til spolen. En returneret af ankermedlemmet og 6 mere returneret ved alle henrettelser af det rekursive medlem.
Som en sidebemærkning er det interessant at bemærke, hvordan planen håndterer standard maxrekursionsgrænsen, som er 100. Bemærk, at den nederste Compute Scalar-operator bliver ved med at øge en intern tæller kaldet Expr1011 med 1 med hver udførelse af det rekursive medlem. Derefter sætter Assert-operatøren et flag til nul, hvis denne tæller overstiger 100. Hvis dette sker, stopper SQL Server udførelsen af forespørgslen og genererer en fejl.
Hvornår skal du ikke fortsætte
Tilbage til ikke-rekursive CTE'er, som normalt ikke bliver vedvarende, er det op til dig at finde ud af fra et optimeringsperspektiv, hvornår det er en god ting at bruge dem kontra faktiske persistensværktøjer som midlertidige tabeller og tabelvariabler i stedet for. Jeg vil gennemgå et par eksempler for at demonstrere, hvornår hver tilgang er mere optimal.
Lad os starte med et eksempel, hvor CTE'er klarer sig bedre end midlertidige tabeller. Det er ofte tilfældet, når du ikke har flere evalueringer af den samme CTE, snarere, måske bare en modulær løsning, hvor hver CTE kun evalueres én gang. Følgende kode (vi kalder det forespørgsel 7) forespørger i ordretabellen i ydeevnedatabasen, som har 1.000.000 rækker, for at returnere ordreår, hvor mere end 70 forskellige kunder afgav ordrer:
BRUG PerformanceV5; MED C1 AS ( SELECT YEAR(orderdate) AS orderyear, custid FROM dbo.Orders ), C2 AS ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts FROM C1 GROUP BY orderyear ) SELECT orderyear, numcusts FROM C2 WHERE numcusts<70; /pre>Denne forespørgsel genererer følgende output:
orderyear numcusts ------------------ ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000Jeg kørte denne kode ved hjælp af SQL Server 2019 Developer Edition og fik planen vist i figur 7.
Figur 7:Udførelsesplan for forespørgsel 7
Bemærk, at ophævelsen af CTE'en resulterede i en plan, der trækker dataene fra et indeks på ordretabellen og ikke involverer nogen spooling af CTE'ens indre forespørgselsresultatsæt. Jeg fik følgende ydelsestal, da jeg udførte denne forespørgsel på min maskine:
varighed:265 ms, CPU:828 ms, læser:3970, skriver:0Lad os nu prøve en løsning, der bruger midlertidige tabeller i stedet for CTE'er (vi kalder det løsning 8), som sådan:
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; VÆLG ordreår, COUNT(DISTINCT custid) AS numcust INTO #T2 FROM #T1 GROUP BY orderyear; VÆLG ordreår, numcust FRA #T2 HVOR numcusts> 70; SLIP TABEL #T1, #T2;Planerne for denne løsning er vist i figur 8.
Figur 8:Planer for løsning 8
Læg mærke til, at Tabelindsæt-operatorerne skriver resultatsættene til de midlertidige tabeller #T1 og #T2. Den første er særlig dyr, da den skriver 1.000.000 rækker til #T1. Her er de præstationsnumre, jeg fik for denne udførelse:
varighed:454 ms, CPU:1517 ms, læser:14359, skriver:359Som du kan se, er løsningen med CTE'erne meget mere optimal.
Hvornår skal du fortsætte
Så er det sådan, at en modulær løsning, der kun involverer en enkelt evaluering af hver CTE, altid foretrækkes frem for at bruge midlertidige tabeller? Ikke nødvendigvis. I CTE-baserede løsninger, der involverer mange trin og resulterer i udførlige planer, hvor optimizeren skal anvende masser af kardinalitetsestimater på mange forskellige punkter i planen, kan du ende med akkumulerede unøjagtigheder, der resulterer i suboptimale valg. En af teknikkerne til at forsøge at tackle sådanne tilfælde er at fastholde nogle mellemliggende resultatsæt selv i midlertidige tabeller og endda oprette indekser på dem, hvis det er nødvendigt, hvilket giver optimeringsværktøjet en frisk start med nye statistikker, hvilket øger sandsynligheden for bedre kvalitetskardinalitetsestimater. forhåbentlig føre til mere optimale valg. Om dette er bedre end en løsning, der ikke bruger midlertidige tabeller, er noget, du bliver nødt til at teste. Nogle gange vil afvejningen af ekstra omkostninger for vedvarende mellemresultatsæt for at få bedre kvalitetskardinalitetsestimater være det værd.
Et andet typisk tilfælde, hvor brug af midlertidige tabeller er den foretrukne tilgang, er, når den CTE-baserede løsning har flere evalueringer af den samme CTE, og CTE'ens indre forespørgsel er ret dyr. Overvej følgende CTE-baserede løsning (vi kalder den forespørgsel 9), som matcher hvert ordreår og måned et andet ordreår og måned, der har det nærmeste ordreantal:
MED OrdCount AS ( SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numbers FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate) ) SELECT O1.orderyear, O1 .ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FRA OrdCount AS O1 CROSS APPLY ( VÆLG TOP (1) O2.orderyear, O2.ordermonth, O2.numorders FRA OrdCount AS O2 WHERE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2;Denne forespørgsel genererer følgende output:
ordreår ordremåned antal ordreår2 ordremåned2 tal2 ----------- ------------------ ------------------ --- ------------------ ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 1 2056 2016 4 2056 2056 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2017 7 21238 2016 2 1984 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 2019 2019 6 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 RowPlanen for forespørgsel 9 er vist i figur 9.
Figur 9:Udførelsesplan for forespørgsel 9
Den øverste del af planen svarer til forekomsten af OrdCount CTE, der er kaldet O1. Denne reference resulterer i én evaluering af CTE OrdCount. Denne del af planen trækker rækkerne fra et indeks på ordretabellen, grupperer dem efter år og måned og aggregerer antallet af ordrer pr. gruppe, hvilket resulterer i 49 rækker. Den nederste del af planen svarer til den korrelerede afledte tabel O2, som anvendes pr. række fra O1, og derfor udføres 49 gange. Hver udførelse forespørger OrdCount CTE og resulterer derfor i en separat evaluering af CTE'ens indre forespørgsel. Du kan se, at den nederste del af planen scanner alle rækker fra indekset på Ordrer, grupperer og samler dem. Du får som udgangspunkt i alt 50 evalueringer af CTE, hvilket resulterer i 50 gange at scanne de 1.000.000 rækker fra ordrer, gruppere og aggregere dem. Det lyder ikke som en særlig effektiv løsning. Her er de præstationsmål, jeg fik, da jeg udførte denne løsning på min maskine:
varighed:16 sekunder, CPU:56 sekunder, læser:130404, skriver:0I betragtning af, at der kun er et par dusin måneder involveret, ville det være meget mere effektivt at bruge en midlertidig tabel til at gemme resultatet af en enkelt aktivitet, der grupperer og aggregerer rækkerne fra ordrer og derefter har både de ydre og indre inputs af APPLY-operatøren interagerer med den midlertidige tabel. Her er løsningen (vi kalder den løsning 10) ved hjælp af en midlertidig tabel i stedet for CTE:
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numorders INTO #OrdCount FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate); VÆLG O1.ordreyear, O1.ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FRA #OrdCount AS O1 CROSS APPLY (VÆLG TOP (1) O2.orderyear, O2.ordermonth , O2.numorders FRA #OrdCount AS O2 HVOR O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2; SLIP TABEL #OrdCount;Her er der ikke meget mening i at indeksere den midlertidige tabel, da TOP-filteret er baseret på en beregning i dets bestillingsspecifikation, og derfor er en sortering uundgåelig. Det kan dog sagtens være, at det i andre tilfælde med andre løsninger også vil være relevant for dig at overveje at indeksere dine midlertidige tabeller. I hvert fald er planen for denne løsning vist i figur 10.
Figur 10:Udførelsesplaner for løsning 10
Se i topplanen, hvordan det tunge løft, der involverer scanning af 1.000.000 rækker, gruppering og sammenlægning af dem, kun sker én gang. 49 rækker skrives til den midlertidige tabel #OrdCount, og derefter interagerer bundplanen med den midlertidige tabel for både de ydre og indre input fra Nested Loops-operatøren, som håndterer APPLY-operatørens logik.
Her er ydelsestallene, som jeg fik for udførelsen af denne løsning:
varighed:0,392 sekunder, CPU:0,5 sekunder, læser:3636, skriver:3Den er hurtigere i størrelsesordener end den CTE-baserede løsning.
Hvad er det næste?
I denne artikel startede jeg dækningen af optimeringsovervejelser relateret til CTE'er. Jeg viste, at unnesting/substitution-processen, der finder sted med afledte tabeller, fungerer på samme måde med CTE'er. Jeg diskuterede også det faktum, at ikke-rekursive CTE'er ikke bliver vedholdende og forklarede, at når persistens er en vigtig faktor for ydeevnen af din løsning, skal du håndtere det selv ved at bruge værktøjer som midlertidige tabeller og tabelvariabler. Næste måned vil jeg fortsætte diskussionen ved at dække yderligere aspekter af CTE-optimering.