IGNORE_DUP_KEY mulighed for unikke indekser angiver, hvordan SQL Server reagerer på et forsøg på at INSERT duplikerede værdier:Det gælder kun for tabeller (ikke visninger) og kun for inserts. En hvilken som helst indsæt del af en MERGE sætning ignorerer enhver IGNORE_DUP_KEY indeksindstilling.
Når IGNORE_DUP_KEY er OFF , resulterer den første dublet, der stødes på, i en fejl , og ingen af de nye rækker er indsat.
Når IGNORE_DUP_KEY er ON , indsatte rækker, der ville krænke unikhed, kasseres. De resterende rækker er indsat. En advarsel meddelelsen udsendes i stedet for en fejl:
Artikeloversigt
IGNORE_DUP_KEY indeksindstilling kan angives for både klyngede og ikke-klyngede unikke indekser. Brug af det på et klynget indeks kan resultere i meget dårligere ydeevne end for et ikke-klynget unikt indeks.
Størrelsen af præstationsforskellen afhænger af, hvor mange unikke krænkelser, der stødes på under INSERT operation. Jo flere overtrædelser, jo dårligere klarer det klyngede unikke indeks i sammenligning. Hvis der overhovedet ikke er nogen overtrædelser, kan den klyngede indeksindsættelse endda fungere bedre.
Klyngede unikke indeksindsættelser
For et klynget unikt indeks med IGNORE_DUP_KEY indstillet, håndteres dubletter af lagermotoren .
Meget af det arbejde, der er involveret i at indsætte hver række, udføres, før duplikatet detekteres. For eksempel en Clustered Index Insert Operatøren navigerer ned i det klyngede indeks b-træ til det punkt, hvor den nye række vil gå, og tager sidelåse og det sædvanlige hierarki af låse, før den opdager den dubletnøgle.
Når duplikatnøgletilstanden detekteres, vises en fejl er hævet. I stedet for at annullere eksekvering og returnere fejlen til klienten, håndteres fejlen internt. Den problematiske række er ikke indsat, og udførelsen fortsætter og leder efter den næste række, der skal indsættes. Hvis den række støder på en dubletnøgle, bliver en anden fejl rejst og håndteret, og så videre.
Undtagelser er meget dyre at kaste og fange. Et betydeligt antal dubletter vil bremse eksekveringen meget mærkbart.
Ikke-klyngede unikke indeksindsættelser
For et ikke-klynget unikt indeks med IGNORE_DUP_KEY indstillet, håndteres dubletter af forespørgselsprocessoren . Dubletter detekteres, og der udsendes en advarsel, før hver indsættelse forsøges.
Forespørgselsprocessoren fjerner dubletter fra indsættelsesstrømmen og sikrer, at lagermotoren ikke kan se dubletter. Som et resultat heraf bliver ingen unikke nøgleovertrædelsesfejl rejst eller håndteret internt.
Afvejningen
Der er en afvejning mellem omkostningerne ved at opdage og fjerne dubletnøgler i udførelsesplanen, versus omkostningerne ved at udføre betydeligt indsatsrelateret arbejde, og smide og fange fejl, når en dublet er fundet.
Hvis dubletter forventes at være meget sjældne , kan storage engine-løsningen (clustered index) meget vel være mere effektiv. Når dubletter er mindre sjældne, vil forespørgselsbehandlertilgangen sandsynligvis betale sig. Det nøjagtige overgangspunkt vil afhænge af faktorer såsom køretidseffektiviteten af de udførelsesplankomponenter, der bruges til at opdage og fjerne dubletter.
Resten af denne artikel giver en demo og ser mere detaljeret på, hvorfor storage engine-tilgangen kan præstere så dårligt.
Demo
Følgende script opretter en midlertidig tabel med en million rækker. Den har 1.000 unikke værdier og 1.000 rækker for hver unik værdi. Dette datasæt vil blive brugt som datakilde for indsættelser i tabeller med forskellige indekskonfigurationer.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Basislinje
Følgende indsættelse i en tabelvariabel med et ikke-unikt klynget indeks tager omkring 900 ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Bemærk manglen på IGNORE_DUP_KEY på måltabelvariablen.
Klyngede unikke indeks
Indsættelse af de samme data til en unik klynge indeks med IGNORE_DUP_KEY sæt ON tager omkring 15.900 ms — næsten 18 gange værre:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Ikke-klyngede unikke indeks
Indsættelse af data til en unik ikke-klyngede indeks med IGNORE_DUP_KEY sæt ON tager omkring 700 ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Ydeevneoversigt
Baseline-testen tager 900 ms for at indsætte alle en million rækker. Den ikke-klyngede indekstest tager 700 ms for kun at indsætte de 1.000 forskellige nøgler. Den klyngede indekstest tager 15.900 ms for at indsætte de samme 1.000 unikke rækker.
Denne test er bevidst sat op for at fremhæve dårlig ydeevne af lagermotorimplementeringen ved at generere 999 enheder spildt arbejde (låse, låse, fejlhåndtering) for hver succesfuld række.
Den tilsigtede besked er ikke den IGNORE_DUP_KEY vil altid præstere dårligt på klyngede indekser, bare hvad det kan, og der kan være stor forskel mellem klyngede og ikke-klyngede indekser.
Clustered Index Execution Plan
Der er ikke en enorm mængde at se i den klyngede indeksindsættelsesplan:
Der er 1.000.000 rækker, der sendes til Clustered Index Insert operator, som vises som 'returnerende' 1.000 rækker. Når vi graver i plandetaljerne, kan vi se:
- 1.244.008 logiske læsninger hos indsættelsesoperatøren.
- Størstedelen af udførelsestiden bruges på Indsæt operatør.
- 11 ms af
SOS_SCHEDULER_YIELDventer (dvs. ingen andre venter).
Intet, der virkelig forklarer 15.900 ms af forløbet tid.
Hvorfor ydeevnen er så dårlig
Det er tydeligt, at denne plan skal udføre en masse arbejde for hver række:
- Naviger de klyngede indeks b-træ-niveauer, lås og lås, mens det går, for at finde indsættelsespunktet for den nye post.
- Hvis nogen af de nødvendige indekssider ikke er i hukommelsen, skal de hentes fra disken.
- Konstruer en ny b-træ række i hukommelsen.
- Forbered logposter.
- Hvis der findes en nøgleduplikat (det er ikke en spøgelsesrecord), skal du rejse en fejl, håndtere den fejl internt, frigive den aktuelle række og fortsætte på et passende sted i koden for at behandle den næste kandidatrække.
Det er alt sammen en rimelig mængde arbejde, og husk, at det hele sker for hver række .
Den del, jeg vil koncentrere mig om, er fejlsøgningen og håndteringen, fordi det er ekstremt dyrt. De resterende aspekter nævnt ovenfor var allerede gjort så billige som muligt ved at bruge en tabelvariabel og midlertidig tabel i demoen.
Undtagelser
Den første ting, jeg vil gøre, er at vise, at Clustered Index Insert operatøren rejser virkelig en undtagelse, når den støder på en dubletnøgle.
En måde at vise dette direkte på er ved at vedhæfte en debugger og fange et stakspor på det punkt, hvor undtagelsen er kastet:
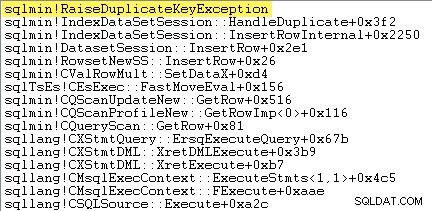
Det vigtige her er, at det er meget dyrt at kaste og fange undtagelser.
Overvågning af SQL Server ved hjælp af Windows Performance Recorder, mens testen kørte, og analyse af resultaterne i Windows Performance Analyzer viser:
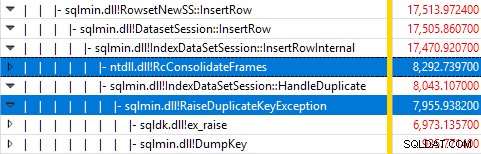
Næsten al forespørgselsudførelsestid bruges i sqlmin!IndexDataSetSession::InsertRowInternal som man kunne forvente for en forespørgsel, der ikke gør andet end at indsætte rækker.
Overraskelsen er, at 45 % af den tid bruges på at rejse undtagelser via sqlmin!RaiseDuplicateKeyException og yderligere 47 % bruges i den tilknyttede undtagelses catch-blok (ntdll!RcConsolidateFrames hierarki).
For at opsummere:At hæve og fange undtagelser udgør 92 % af eksekveringstiden af vores testklyngede indeksindsættelsesforespørgsel.
Problemer med dataindsamling
Skarpøjede læsere bemærker muligvis en betydelig mængde – omkring 12 % – af undtagelsestiden, hvilket øger tiden brugt i sqlmin!DumpKey i Windows Performance Analyzer-grafikken. Dette er værd at undersøge hurtigt sammen med et par relaterede emner.
Som en del af at rejse en undtagelse skal SQL Server indsamle nogle data, der kun er tilgængelige på det tidspunkt, hvor fejlen opstod. Fejlnummeret forbundet med en dubletnøgleundtagelse er 2627. Meddelelsesteksten i sys.messages for det fejlnummer er:
Oplysninger til at udfylde disse stedsmarkører skal indsamles på det tidspunkt, hvor fejlen opstår - den vil ikke være tilgængelig senere! Det betyder at slå op og formatere typen af begrænsning, dens navn, det fulde navn på målobjektet og den specifikke nøgleværdi. Alt det tager tid.
Følgende staksporing viser serveren, der formaterer dubletnøgleværdien som en Unicode-streng under DumpKey ring:
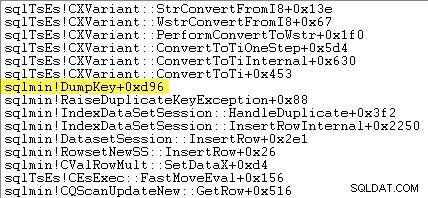
Undtagelseshåndtering involverer også indfangning af et stakspor:
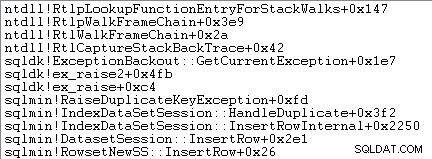
SQL Server registrerer også oplysninger om undtagelser (inklusive stackframes) i en lille ringbuffer, som følgende viser:
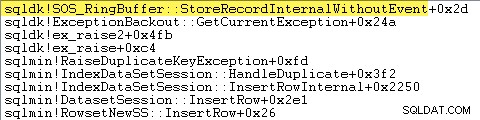
Du kan se disse ringebufferposter ved hjælp af en kommando som:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Et eksempel på xml-posten for en dubletnøgleundtagelse følger. Bemærk stabelrammerne:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Alt dette baggrundsarbejde sker for enhver undtagelse. I vores test betyder det, at det sker 999.000 gange - én gang for hver række, der støder på en dublet nøgleovertrædelse.
Der er mange måder at se dette på, for eksempel ved at køre en Profiler-sporing ved hjælp af undtagelsen hændelse i Fejl og advarsler klasse. I vores testtilfælde vil dette til sidst producere 999.000 rækker med TextData elementer som dette:
Overtrædelse af UNIQUE KEY constraint 'UQ__#AC166DE__3213663B8B6E2E0E'Kan ikke indsætte dubletnøgle i objekt 'dbo.@T'.
Duplikatnøgleværdien er (173).
At vedhæfte Profiler betyder, at hver undtagelseshåndteringshændelse får en hel del ekstra overhead, da de ekstra nødvendige data indsamles og formateres. De tidligere nævnte standarddata indsamles altid, selvom ingen aktivt bruger oplysningerne.
For at være klar:Ydeevnetallene rapporteret i denne artikel blev alle opnået uden en debugger tilknyttet, og ingen anden aktiv overvågning.
Ikke-klyngede indeksudførelsesplan
På trods af at den er så meget hurtigere, er den ikke-klyngede indeksindsættelsesplan en del mere kompleks, så jeg vil dele den op i to dele.
Det generelle tema er, at denne plan er hurtigere, fordi den eliminerer dubletter før forsøger at indsætte dem i måltabellen.
Del 1
Først højre side af den ikke-klyngede indeksplan:
Denne del af planen afviser alle rækker, der har et nøglematch i måltabellen for det unikke indeks med IGNORE_DUP_KEY sæt ON .
Du forventer måske at se en Anti Semi Join her, men SQL Server har ikke den nødvendige infrastruktur til at udsende den påkrævede duplikatnøgleadvarsel med en Anti Semi Join operatør. (Hvis det ikke allerede giver mening, skal det snart.)
I stedet får vi en plan med en række interessante funktioner:
- Den Clustered Index Scan er
Ordered:Truefor at give input til Merge Left Semi Join sorteret efter kolonnec1i#Datatabel. - Indeksscanningen af tabelvariablen er
Ordered:False - Sorteringen rækker rækker efter kolonne
c1i tabelvariablen. Denne ordre kunne have været leveret af en ordre scanning af tabelvariabelindekset påc1, men optimeringsværktøjet bestemmer Sorteringen er den billigste måde at give det påkrævede niveau af Halloween-beskyttelse. - Tabelvariablen Indeksscanning har intern
UPDLOCKogSERIALIZABLEtip anvendt for at sikre målstabilitet under planens udførelse. - Den Merge Left Semi Join kontrollerer for match i tabelvariablen for hver værdi af
c1returneret fra#Databord. I modsætning til en almindelig semi-join, udsender den hver række modtaget på dens øvre input. Den sætter et flag i en probesøjle for at angive, om den aktuelle række fandt et match eller ej. Probesøjlen udsendes fra Merge Left Semi Join som et udtryk med navnetExpr1012. - Den påstand operatør kontrollerer værdien af probekolonnen
Expr1012. Første gang den ser en række med en probekolonneværdi, der ikke er nul (hvilket indikerer, at en indeksnøglematch blev fundet), udsender den en "Duplicate key was ignored" besked. - Den påstand overfører kun rækker, hvor probesøjlen er nul. Dette eliminerer indgående rækker, der ville producere en dublet nøglefejl.
Det hele kan virke komplekst, men det er i bund og grund så simpelt som at sætte et flag, hvis der findes et match, udsende en advarsel første gang flaget sættes, og kun sende rækker videre mod indsætningen, der ikke allerede findes i måltabellen .
Del 2
Den anden del af planen følger påstanden operatør:
Den forrige del af planen fjernede rækker, der havde et match i måltabellen. Denne del af planen fjerner dubletter inden for indsættelsessættet .
Forestil dig for eksempel, at der ikke er nogen rækker i måltabellen, hvor c1 = 1 . Vi kan stadig forårsage en dubletnøglefejl, hvis vi forsøger at indsætte to rækker med c1 = 1 fra kildetabellen. Det er vi nødt til at undgå for at respektere semantikken i IGNORE_DUP_KEY = ON .
Dette aspekt håndteres af Segmentet og Top operatører.
Segmentet operatør sætter et nyt flag (mærket Segment1015 ) når den støder på en række med en ny værdi for c1 . Da rækker er præsenteret i c1 ordre (takket være den ordrebevarende Flet ), kan planen stole på alle rækker med den samme c1 værdi, der kommer i en sammenhængende strøm.
Toppen operatør sender én række for hver gruppe af dubletter, som angivet af Segment flag. Hvis Top operatør støder på mere end én række for det samme Segment gruppe (c1 værdi), udsender den en "Duplikatnøgle blev ignoreret" advarsel, hvis det er første gang, planen støder på denne tilstand.
Nettoeffekten af alt dette er, at kun én række sendes til indsættelsesoperatorerne for hver unik værdi af c1 , og en advarsel genereres om nødvendigt.
Udførelsesplanen har nu elimineret alle potentielle duplikerede nøgleovertrædelser, så den resterende Tabelindsæt og Indeksindsæt operatører kan sikkert indsætte rækker til heap og ikke-klyngede indeks uden frygt for en duplikatnøglefejl.
Husk at UPDLOCK og SERIALIZABLE hints, der anvendes til måltabellen, sikrer, at sættet ikke kan ændres under udførelse. Med andre ord kan en samtidig sætning ikke ændre måltabel, således at der opstår en duplikatnøglefejl ved Indsæt operatører. Det er ikke et problem her, da vi bruger en privat tabelvariabel, men SQL Server tilføjer stadig hints som en generel sikkerhedsforanstaltning.
Uden disse hints kunne en samtidig proces tilføje en række til måltabellen, der ville generere en duplikatnøgleovertrædelse, på trods af kontrollerne foretaget af del 1 af planen. SQL Server skal være sikker på, at eksistenskontrolresultaterne forbliver gyldige.
Den nysgerrige læser kan se nogle af funktionerne beskrevet ovenfor ved at aktivere sporingsflag 3604 og 8607 for at se optimeringsoutputtræet:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Sidste tanker
IGNORE_DUP_KEY indeksmulighed er ikke noget, de fleste mennesker vil bruge meget ofte. Alligevel er det interessant at se på, hvordan denne funktionalitet implementeres, og hvorfor der kan være store ydeevneforskelle mellem IGNORE_DUP_KEY på klyngede og ikke-klyngede indekser.
I mange tilfælde vil det betale sig at følge forespørgselsprocessoren og se efter at skrive forespørgsler, der eksplicit eliminerer dubletter i stedet for at stole på IGNORE_DUP_KEY . I vores eksempel ville det betyde at skrive:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Dette udføres på omkring 400 ms , bare for ordens skyld.