I del 1 og del 2 af denne serie dækkede jeg de logiske eller konceptuelle aspekter af navngivne tabeludtryk generelt og afledte tabeller specifikt. Denne måned og den næste vil jeg dække de fysiske behandlingsaspekter af afledte tabeller. Husk fra del 1 fysisk datauafhængighed princippet om relationsteori. Den relationelle model og standardforespørgselssproget, der er baseret på den, formodes kun at beskæftige sig med de konceptuelle aspekter af dataene og overlade de fysiske implementeringsdetaljer som lagring, optimering, adgang og behandling af dataene til databaseplatformen (implementering ). I modsætning til den konceptuelle behandling af data, som er baseret på en matematisk model og et standardsprog, og derfor er meget ens i de forskellige relationelle databasestyringssystemer derude, er den fysiske behandling af dataene ikke baseret på nogen standard og har derfor tendens til at være meget platformsspecifik. I min dækning af den fysiske behandling af navngivne tabeludtryk i serien fokuserer jeg på behandlingen i Microsoft SQL Server og Azure SQL Database. Den fysiske behandling i andre databaseplatforme kan være meget anderledes.
Husk, at det, der udløste denne serie, er en vis forvirring, der eksisterer i SQL Server-fællesskabet omkring navngivne tabeludtryk. Både hvad angår terminologi og hvad angår optimering. Jeg behandlede nogle terminologiske overvejelser i de første to dele af serien, og jeg vil behandle flere i fremtidige artikler, når jeg diskuterer CTE'er, synspunkter og inline TVF'er. Hvad angår optimering af navngivne tabeludtryk, er der forvirring omkring følgende elementer (jeg nævner afledte tabeller her, da det er fokus i denne artikel):
- Vedholdenhed: Bevarer en afledt tabel nogen steder? Bliver det fastholdt på disken, og hvordan håndterer SQL Server hukommelse til det?
- Kolonneprojektion: Hvordan fungerer indeksmatching med afledte tabeller? For eksempel, hvis en afledt tabel projicerer et bestemt undersæt af kolonner fra en underliggende tabel, og den yderste forespørgsel projicerer en undergruppe af kolonnerne fra den afledte tabel, er SQL Server smart nok til at finde ud af optimal indeksering baseret på den endelige undergruppe af kolonner er det faktisk nødvendigt? Og hvad med tilladelser; har brugeren brug for tilladelser til alle kolonner, der refereres til i de indre forespørgsler, eller kun til de sidste, der faktisk er nødvendige?
- Flere referencer til kolonnealiasser: Hvis den afledte tabel har en resultatkolonne, der er baseret på en ikke-deterministisk beregning, f.eks. et kald til funktionen SYSDATETIME, og den ydre forespørgsel har flere referencer til den kolonne, vil beregningen kun blive udført én gang eller separat for hver ydre reference ?
- Unnesting/substitution/inlining: Ophæver eller indlejrer SQL Server den afledte tabelforespørgsel? Det vil sige, udfører SQL Server en substitutionsproces, hvorved den konverterer den originale indlejrede kode til én forespørgsel, der går direkte mod basistabellerne? Og hvis det er tilfældet, er der en måde at instruere SQL Server for at undgå denne unnesting-proces?
Disse er alle vigtige spørgsmål, og svarene på disse spørgsmål har betydelige præstationsimplikationer, så det er en god idé at have en klar forståelse af, hvordan disse elementer håndteres i SQL Server. I denne måned vil jeg tage fat på de første tre punkter. Der er ret meget at sige om det fjerde punkt, så jeg vil dedikere en separat artikel til det næste måned (Del 4).
I mine eksempler vil jeg bruge en prøvedatabase kaldet TSQLV5. Du kan finde scriptet, der opretter og udfylder TSQLV5 her, og dets ER-diagram her.
Vedholdenhed
Nogle mennesker antager intuitivt, at SQL Server bevarer resultatet af tabeludtryksdelen af den afledte tabel (resultatet af den indre forespørgsel) i en arbejdstabel. På datoen for denne skrivning er det ikke tilfældet; men da persistensovervejelser er en leverandørs valg, kunne Microsoft beslutte at ændre dette i fremtiden. Faktisk er SQL Server i stand til at bevare mellemliggende forespørgselsresultater i arbejdstabeller (typisk i tempdb) som en del af forespørgselsbehandlingen. Hvis den vælger at gøre det, ser du en form for en spool-operatør i planen (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). SQL Servers valg af, om du vil spoole noget i en arbejdstabel eller ej, har dog i øjeblikket intet at gøre med din brug af navngivne tabeludtryk i forespørgslen. SQL Server spooler nogle gange mellemresultater af ydeevnemæssige årsager, såsom at undgå gentaget arbejde (selv om det i øjeblikket ikke er relateret til brugen af navngivne tabeludtryk), og nogle gange af andre årsager, såsom Halloween-beskyttelse.
Som nævnt vil jeg i næste måned komme til detaljerne om unnesting af afledte tabeller. For nu er det tilstrækkeligt at sige, at SQL Server normalt anvender en unnesting/inlining-proces til afledte tabeller, hvor den erstatter de indlejrede forespørgsler med en forespørgsel mod de underliggende basistabeller. Nå, jeg oversimplifiserer lidt. Det er ikke sådan, at SQL Server bogstaveligt talt konverterer den originale T-SQL-forespørgselsstreng med de afledte tabeller til en ny forespørgselsstreng uden disse; SQL Server anvender snarere transformationer til et internt logisk træ af operatører, og resultatet er, at de afledte tabeller typisk bliver uindlejrede. Når du ser på en udførelsesplan for en forespørgsel, der involverer afledte tabeller, kan du ikke se nogen omtale af dem, fordi de til de fleste optimeringsformål ikke eksisterer. Du ser adgang til de fysiske strukturer, der indeholder dataene for de underliggende basistabeller (heap, B-tree rowstore indekser og columnstore indekser for disk-baserede tabeller og træ og hash indekser for hukommelsesoptimerede tabeller).
Der er tilfælde, der forhindrer SQL Server i at fjerne en afledt tabel, men selv i disse tilfælde bevarer SQL Server ikke tabeludtrykkets resultat i en arbejdstabel. Jeg giver detaljerne sammen med eksempler næste måned.
Da SQL Server ikke bevarer afledte tabeller, snarere interagerer direkte med de fysiske strukturer, der indeholder dataene for de underliggende basistabeller, er spørgsmålet om, hvordan hukommelsen håndteres for afledte tabeller, uklart. Hvis de underliggende basistabeller er diskbaserede, skal deres relevante sider behandles i bufferpuljen. Hvis de underliggende tabeller er hukommelsesoptimerede, skal deres relevante rækker i hukommelsen behandles. Men det er ikke anderledes, end når du selv forespørger på de underliggende tabeller uden at bruge afledte tabeller. Så der er ikke noget særligt her. Når du bruger afledte tabeller, behøver SQL Server ikke at anvende nogen særlige hukommelsesovervejelser for disse. Til de fleste forespørgselsoptimeringsformål eksisterer de ikke.
Hvis du har et tilfælde, hvor du har brug for at fortsætte et mellemtrins resultat i en arbejdstabel, skal du bruge midlertidige tabeller eller tabelvariabler – ikke navngivne tabeludtryk.
Kolonneprojektion og et ord på SELECT *
Projektion er en af de oprindelige operatorer af relationel algebra. Antag, at du har en relation R1 med attributterne x, y og z. Projektionen af R1 på en delmængde af dens attributter, f.eks. x og z, er en ny relation R2, hvis overskrift er delmængden af projekterede attributter fra R1 (x og z i vores tilfælde), og hvis krop er sættet af tupler dannet ud fra den originale kombination af projicerede attributværdier fra R1's tupler.
Husk på, at en relations krop - som er et sæt af tupler - pr definition ikke har nogen dubletter. Så det siger sig selv, at resultatrelationens tupler er den distinkte kombination af attributværdier, der fremskrives fra den oprindelige relation. Husk dog, at brødteksten i en tabel i SQL er et multisæt af rækker og ikke et sæt, og normalt vil SQL ikke eliminere duplikerede rækker, medmindre du instruerer det til det. Givet en tabel R1 med kolonnerne x, y og z, kan følgende forespørgsel potentielt returnere duplikerede rækker og følger derfor ikke relationel algebras projektionsoperators semantik for at returnere et sæt:
SELECT x, z FROM R1;
Ved at tilføje en DISTINCT-sætning eliminerer du duplikerede rækker og følger tættere semantikken i relationel projektion:
SELECT DISTINCT x, z FROM R1;
Selvfølgelig er der nogle tilfælde, hvor du ved, at resultatet af din forespørgsel har adskilte rækker uden behov for en DISTINCT-sætning, f.eks. når en delmængde af de kolonner, du returnerer, inkluderer en nøgle fra den forespurgte tabel. For eksempel, hvis x er en nøgle i R1, er de to ovenstående forespørgsler logisk ækvivalente.
Husk i hvert fald de spørgsmål, jeg nævnte tidligere omkring optimering af forespørgsler, der involverer afledte tabeller og kolonneprojektion. Hvordan fungerer indeksmatching? Hvis en afledt tabel projicerer et bestemt undersæt af kolonner fra en underliggende tabel, og den yderste forespørgsel projicerer en undergruppe af kolonnerne fra den afledte tabel, er SQL Server smart nok til at finde ud af optimal indeksering baseret på den endelige undergruppe af kolonner, der faktisk er havde brug for? Og hvad med tilladelser; har brugeren brug for tilladelser til alle kolonner, der refereres til i de indre forespørgsler, eller kun til de sidste, der faktisk er nødvendige? Antag også, at tabeludtryksforespørgslen definerer en resultatkolonne, der er baseret på en beregning, men den ydre forespørgsel projicerer ikke denne kolonne. Er beregningen overhovedet evalueret?
Start med det sidste spørgsmål, lad os prøve det. Overvej følgende forespørgsel:
USE TSQLV5; GO SELECT custid, city, 1/0 AS div0error FROM Sales.Customers;
Som du ville forvente, mislykkes denne forespørgsel med en divider med nul-fejl:
Msg 8134, Level 16, State 1Divider med nul fejl fundet.
Derefter skal du definere en afledt tabel kaldet D baseret på ovenstående forespørgsel, og i den ydre forespørgsel projekterer D kun på custid og by, som sådan:
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D; Som nævnt anvender SQL Server normalt unnesting/substitution, og da der ikke er noget i denne forespørgsel, der forhindrer unnesting (mere om dette næste måned), svarer ovenstående forespørgsel til følgende forespørgsel:
SELECT custid, city FROM Sales.Customers;
Igen, jeg oversimplifiserer lidt her. Virkeligheden er en smule mere kompleks, end at disse to forespørgsler betragtes som virkelig identiske, men jeg kommer til disse kompleksiteter næste måned. Pointen er, at udtrykket 1/0 ikke engang dukker op i forespørgslens eksekveringsplan og bliver slet ikke evalueret, så ovenstående forespørgsel kører med succes uden fejl.
Alligevel skal tabeludtrykket være gyldigt. Overvej f.eks. følgende forespørgsel:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Selvom den ydre forespørgsel kun projicerer en kolonne fra den indre forespørgsels grupperingssæt, er den indre forespørgsel ikke gyldig, da den forsøger at returnere kolonner, der hverken er en del af grupperingssættet eller indeholdt i en aggregeret funktion. Denne forespørgsel mislykkes med følgende fejl:
Msg 8120, Level 16, State 1Kolonne 'Sales.Customers.custid' er ugyldig i valglisten, fordi den ikke er indeholdt i hverken en aggregeret funktion eller GROUP BY-sætningen.
Lad os derefter tage fat på spørgsmålet om indeksmatchning. Hvis den ydre forespørgsel kun projicerer en delmængde af kolonnerne fra den afledte tabel, vil SQL Server være smart nok til at udføre indeksmatchning kun baseret på de returnerede kolonner (og selvfølgelig alle andre kolonner, der ellers spiller en meningsfuld rolle, såsom filtrering, gruppering og så videre)? Men før vi tager fat på dette spørgsmål, undrer du dig måske over, hvorfor vi overhovedet gider det. Hvorfor ville du have de indre forespørgselsreturkolonner, som den ydre forespørgsel ikke har brug for?
Svaret er enkelt, at forkorte koden ved at lade den indre forespørgsel bruge den berygtede SELECT *. Vi ved alle, at det er en dårlig praksis at bruge SELECT *, men det er primært tilfældet, når det bruges i den yderste forespørgsel. Hvad hvis du forespørger i en tabel med en bestemt overskrift, og senere ændres denne overskrift? Applikationen kan ende med fejl. Selvom du ikke ender med fejl, kan du ende med at generere unødvendig netværkstrafik ved at returnere kolonner, som applikationen egentlig ikke har brug for. Plus, du udnytter indeksering mindre optimalt i et sådant tilfælde, da du reducerer chancerne for at matche dækkende indekser, der er baseret på de virkelig nødvendige kolonner.
Når det er sagt, føler jeg mig faktisk ret tryg ved at bruge SELECT * i et tabeludtryk, vel vidende at jeg alligevel kun vil projicere de virkelig nødvendige kolonner i den yderste forespørgsel. Fra et logisk synspunkt er det ret sikkert med nogle mindre forbehold, som jeg snart kommer til. Det er så længe indeksmatching udføres optimalt i sådan et tilfælde, og den gode nyhed er det.
For at demonstrere dette, antag, at du skal forespørge i Sales.Orders-tabellen og returnere de tre seneste ordrer for hver kunde. Du planlægger at definere en afledt tabel kaldet D baseret på en forespørgsel, der beregner rækkenumre (resultatkolonne rownum), der er opdelt efter custid og ordnet efter ordredato DESC, orderid DESC. Den ydre forespørgsel vil filtrere fra D (relationel begrænsning ) kun de rækker, hvor rownum er mindre end eller lig med 3, og projekt D på custid, orderdate, orderid og rownum. Sales.Orders har nu flere kolonner end dem, du skal projicere, men for kortheds skyld vil du have, at den indre forespørgsel skal bruge SELECT * plus rækkenummerberegningen. Det er sikkert og vil blive håndteret optimalt med hensyn til indeksmatching.
Brug til følgende kode for at oprette det optimale dækkende indeks til at understøtte din forespørgsel:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Her er forespørgslen, der arkiverer den aktuelle opgave (vi kalder den forespørgsel 1):
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Læg mærke til den indre forespørgsels SELECT * og den ydre forespørgsels eksplicitte kolonneliste.
Planen for denne forespørgsel, som gengivet af SentryOne Plan Explorer, er vist i figur 1.
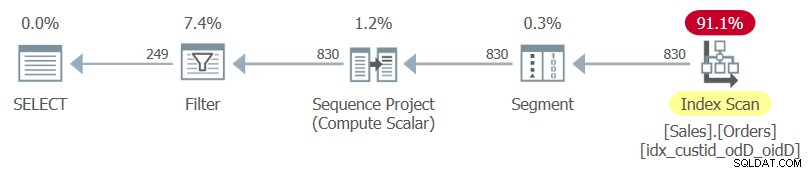 Figur 1:Plan for forespørgsel 1
Figur 1:Plan for forespørgsel 1
Bemærk, at det eneste indeks, der bruges i denne plan, er det optimale dækkende indeks, som du lige har oprettet.
Hvis du kun fremhæver den indre forespørgsel og undersøger dens udførelsesplan, vil du se tabellens klyngede indeks brugt efterfulgt af en sorteringsoperation.
Så det er gode nyheder.
Hvad angår tilladelser, er det en anden historie. I modsætning til indeksmatching, hvor du ikke har brug for indekset til at inkludere kolonner, der refereres til af de indre forespørgsler, så længe de i sidste ende ikke er nødvendige, skal du have tilladelser til alle refererede kolonner.
For at demonstrere dette skal du bruge følgende kode til at oprette en bruger kaldet bruger1 og tildele nogle tilladelser (VÆLG tilladelser på alle kolonner fra Sales.Kunder og kun på de tre kolonner fra Salg.Ordre, der i sidste ende er relevante i ovenstående forespørgsel):
CREATE USER user1 WITHOUT LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
Kør følgende kode for at efterligne bruger1:
EXECUTE AS USER = 'user1';
Prøv at vælge alle kolonner fra Sales.Ordre:
SELECT * FROM Sales.Orders;
Som forventet får du følgende fejl på grund af manglende tilladelser på nogle af kolonnerne:
Msg 230, Level 14, State 1SELECT-tilladelsen blev nægtet i kolonnen 'empid' for objektet 'Orders', databasen 'TSQLV5', skemaet 'Sales'.
Msg 230 , Level 14, State 1
SELECT-tilladelsen blev nægtet i kolonnen 'requireddate' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Sales'.
Besked 230, Level 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'shippeddate' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Sales'.
Besked 230, niveau 14, Tilstand 1
VÆLG-tilladelsen blev nægtet i kolonnen 'forsenderid' for objektet 'Ordre', databasen 'TSQLV5', skema 'Salg'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'fragt' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Salg'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'skibsnavn' for objektet 'Ordre', database 'TSQLV5', skema 'Salg'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'skibsadresse' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Salg'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'shipcity' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Sales'.
Besked 230, niveau 14, tilstand 1
SELECT tilladelse blev nægtet på kolonnen 'shipregion' for objektet 'Order', databasen 'TSQLV5', skema 'Sales'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen var afvist i kolonnen 'shippostalcode' for objektet 'Order', database 'TSQLV5', skema 'Sales'.
Besked 230, niveau 14, tilstand 1
VÆLG-tilladelsen blev nægtet den kolonnen 'skibsland' for objektet 'Ordre', database 'TSQLV5', skema 'Salg'.
Prøv følgende forespørgsel, projicerer og interagerer kun med kolonner, som bruger1 har tilladelser til:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Alligevel får du kolonnetilladelsesfejl på grund af manglen på tilladelser på nogle af de kolonner, der refereres til af den indre forespørgsel via dens SELECT *:
Msg 230, Level 14, State 1SELECT-tilladelsen blev nægtet i kolonnen 'empid' for objektet 'Orders', databasen 'TSQLV5', skemaet 'Sales'.
Msg 230 , Level 14, State 1
SELECT-tilladelsen blev nægtet i kolonnen 'requireddate' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Sales'.
Besked 230, Level 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'shippeddate' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Sales'.
Besked 230, niveau 14, Tilstand 1
VÆLG-tilladelsen blev nægtet i kolonnen 'forsenderid' for objektet 'Ordre', databasen 'TSQLV5', skema 'Salg'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'fragt' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Salg'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'skibsnavn' for objektet 'Ordre', database 'TSQLV5', skema 'Salg'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'skibsadresse' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Salg'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen blev nægtet i kolonnen 'shipcity' for objektet 'Ordre', databasen 'TSQLV5', skemaet 'Sales'.
Besked 230, niveau 14, tilstand 1
SELECT tilladelse blev nægtet på kolonnen 'shipregion' for objektet 'Order', databasen 'TSQLV5', skema 'Sales'.
Besked 230, niveau 14, tilstand 1
SELECT-tilladelsen var afvist i kolonnen 'shippostalcode' for objektet 'Order', database 'TSQLV5', skema 'Sales'.
Besked 230, niveau 14, tilstand 1
VÆLG-tilladelsen blev nægtet den kolonnen 'skibsland' for objektet 'Ordre', database 'TSQLV5', skema 'Salg'.
Hvis det faktisk i din virksomhed er en praksis kun at tildele brugere tilladelser til relevante kolonner, som de skal interagere med, ville det være fornuftigt at bruge en smule længere kode og være eksplicit om kolonnelisten i både de indre og ydre forespørgsler, sådan:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Denne gang kører forespørgslen uden fejl.
En anden variation, der kræver, at brugeren kun har tilladelser til de relevante kolonner, er at være eksplicit om kolonnenavnene i den indre forespørgsels SELECT-liste og bruge SELECT * i den ydre forespørgsel, som sådan:
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Denne forespørgsel kører også uden fejl. Jeg ser dog denne version som en, der er tilbøjelig til fejl, hvis der senere bliver foretaget ændringer i et indre niveau af indlejring. Som nævnt tidligere er den bedste praksis for mig at være eksplicit om kolonnelisten i den yderste forespørgsel. Så så længe du ikke har nogen bekymringer om manglende tilladelse til nogle af kolonnerne, føler jeg mig godt tilpas med SELECT * i indre forespørgsler, men en eksplicit kolonneliste i den yderste forespørgsel. Hvis anvendelse af specifikke kolonnetilladelser er en almindelig praksis i virksomheden, så er det bedst blot at være eksplicit om kolonnenavne på alle niveauer af indlejring. Husk, at være eksplicit omkring kolonnenavne på alle niveauer af indlejring er faktisk obligatorisk, hvis din forespørgsel bruges i et skemabundet objekt, da skemabinding ikke tillader brugen af SELECT * overalt i forespørgslen.
På dette tidspunkt skal du køre følgende kode for at fjerne det indeks, du oprettede tidligere på Sales.Orders:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
Der er en anden sag med et lignende dilemma vedrørende legitimiteten af at bruge SELECT *; i den indre forespørgsel i EXISTS-prædikatet.
Overvej følgende forespørgsel (vi kalder den forespørgsel 2):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid); Planen for denne forespørgsel er vist i figur 2.
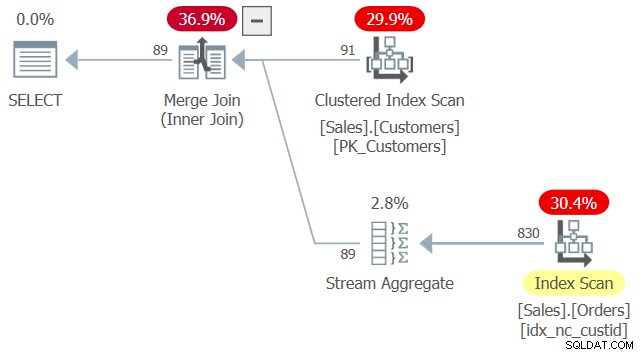 Figur 2:Plan for forespørgsel 2
Figur 2:Plan for forespørgsel 2
Ved anvendelse af indeksmatching regnede optimeringsværktøjet med, at indekset idx_nc_custid er et dækkende indeks på Sales.Orders, da det indeholder custid-kolonnen - den eneste rigtige relevante kolonne i denne forespørgsel. Det er på trods af, at dette indeks ikke indeholder nogen anden kolonne end custid, og at den indre forespørgsel i EXISTS-prædikatet siger SELECT *. Indtil videre ligner adfærden brugen af SELECT * i afledte tabeller.
Hvad der er anderledes ved denne forespørgsel er, at den kører uden fejl, på trods af at bruger1 ikke har tilladelser til nogle af kolonnerne fra Sales.Orders. Der er et argument for at retfærdiggøre ikke at kræve tilladelser på alle kolonner her. Når alt kommer til alt, skal EXISTS-prædikatet kun kontrollere, om der findes matchende rækker, så den indre forespørgsels SELECT-liste er virkelig meningsløs. Det ville nok have været bedst, hvis SQL slet ikke krævede en SELECT-liste i sådan et tilfælde, men det skib er allerede sejlet. Den gode nyhed er, at SELECT-listen effektivt ignoreres – både med hensyn til indeksmatching og med hensyn til påkrævede tilladelser.
Det ser også ud til, at der er en anden forskel mellem afledte tabeller og EXISTS, når du bruger SELECT * i den indre forespørgsel. Husk denne forespørgsel fra tidligere i artiklen:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Hvis du husker det, genererede denne kode en fejl, da den indre forespørgsel er ugyldig.
Prøv den samme indre forespørgsel, kun denne gang i EXISTS-prædikatet (vi kalder dette Statement 3):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!'; Mærkeligt nok betragter SQL Server denne kode som gyldig, og den kører med succes. Planen for denne kode er vist i figur 3.
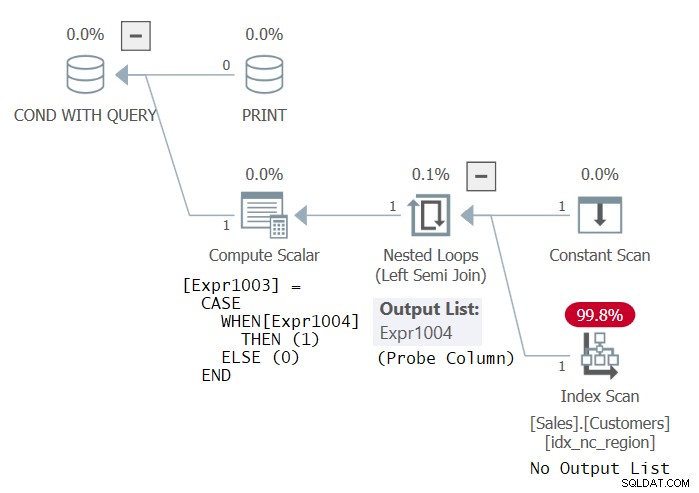 Figur 3:Plan for Statement 3
Figur 3:Plan for Statement 3
Denne plan er identisk med den plan, du ville få, hvis den indre forespørgsel bare var SELECT * FROM Sales.Customers (uden GROUP BY). Når alt kommer til alt, tjekker du for eksistensen af grupper, og hvis der er rækker, er der naturligvis grupper. Jeg tror i hvert fald, at det faktum, at SQL Server betragter denne forespørgsel som gyldig, er en fejl. SQL-koden skal selvfølgelig være gyldig! Men jeg kan se, hvorfor nogle kunne hævde, at SELECT-listen i EXISTS-forespørgslen formodes at blive ignoreret. I hvert fald bruger planen en probet venstre semi join, som ikke behøver at returnere nogen kolonner, snarere blot undersøge en tabel for at kontrollere, om der findes nogen rækker. Indekset på kunder kan være et hvilket som helst indeks.
På dette tidspunkt kan du køre følgende kode for at stoppe med at efterligne bruger1 og slippe den:
REVERT; DROP USER IF EXISTS user1;
Tilbage til det faktum, at jeg synes, det er en praktisk praksis at bruge SELECT * i indre niveauer af nesting, jo flere niveauer du har, jo mere forkorter og forenkler denne praksis din kode. Her er et eksempel med to indlejringsniveauer:
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear; Der er tilfælde, hvor denne praksis ikke kan bruges. For eksempel, når den indre forespørgsel forbinder tabeller med almindelige kolonnenavne, som i følgende eksempel:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Både Sales.Customers og Sales.Orders har en kolonne kaldet custid. Du bruger et tabeludtryk, der er baseret på en joinforbindelse mellem de to tabeller til at definere den afledte tabel D. Husk, at en tabels overskrift er et sæt kolonner, og som et sæt kan du ikke have duplikerede kolonnenavne. Derfor mislykkes denne forespørgsel med følgende fejl:
Msg 8156, Level 16, State 1Kolonnen 'custid' blev angivet flere gange for 'D'.
Her skal du være eksplicit om kolonnenavne i den indre forespørgsel og sørge for, at du enten returnerer custid fra kun en af tabellerne, eller tildeler unikke kolonnenavne til resultatkolonnerne, hvis du ønsker at returnere begge. Oftere ville du bruge den tidligere tilgang, som sådan:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Igen kan du være eksplicit med kolonnenavnene i den indre forespørgsel og bruge SELECT * i den ydre forespørgsel, som sådan:
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Men som jeg nævnte tidligere, anser jeg det for en dårlig praksis ikke at være eksplicit om kolonnenavne i den yderste forespørgsel.
Flere referencer til kolonnealiasser
Lad os fortsætte til næste punkt - flere referencer til afledte tabelkolonner. Hvis den afledte tabel har en resultatkolonne, der er baseret på en ikke-deterministisk beregning, og den ydre forespørgsel har flere referencer til den kolonne, vil beregningen så kun blive evalueret én gang eller separat for hver reference?
Lad os starte med det faktum, at flere referencer til den samme ikke-deterministiske funktion i en forespørgsel formodes at blive evalueret uafhængigt. Overvej følgende forespørgsel som et eksempel:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
Denne kode genererer følgende output, der viser to forskellige GUID'er:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Omvendt, hvis du har en afledt tabel med en kolonne, der er baseret på en ikke-deterministisk beregning, og den ydre forespørgsel har flere referencer til den kolonne, formodes beregningen kun at blive evalueret én gang. Overvej følgende forespørgsel (vi kalder denne forespørgsel 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2 FROM ( SELECT NEWID() AS mynewid ) AS D;
Planen for denne forespørgsel er vist i figur 4.
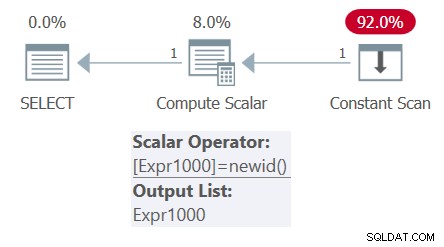 Figur 4:Plan for forespørgsel 4
Figur 4:Plan for forespørgsel 4
Bemærk, at der kun er én påkaldelse af NEWID-funktionen i planen. Følgelig viser output den samme GUID to gange:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
Så de to ovenstående forespørgsler er ikke logisk ækvivalente, og der er tilfælde, hvor inlining/substitution ikke finder sted.
Med nogle ikke-deterministiske funktioner er det lidt vanskeligere at demonstrere, at flere påkaldelser i en forespørgsel håndteres separat. Tag funktionen SYSDATETIME som et eksempel. Den har 100 nanosekunders præcision. Hvad er chancerne for, at en forespørgsel som den følgende faktisk viser to forskellige værdier?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
Hvis du keder dig, kan du trykke F5 gentagne gange, indtil det sker. Hvis du har vigtigere ting at gøre med din tid, foretrækker du måske at køre en løkke, som sådan:
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; For eksempel, da jeg kørte denne kode, fik jeg 1971.
Hvis du vil sikre dig, at den ikke-deterministiske funktion kun aktiveres én gang og stole på den samme værdi i flere forespørgselsreferencer, skal du sørge for, at du definerer et tabeludtryk med en kolonne baseret på funktionsankaldelsen og har flere referencer til den kolonne fra den ydre forespørgsel, som sådan (vi kalder denne forespørgsel 5):
SELECT mydt AS mydt1, mydt AS mydt1 FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
Planen for denne forespørgsel er vist i figur 5.
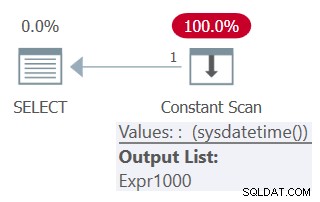 Figur 5:Plan for forespørgsel 5
Figur 5:Plan for forespørgsel 5
Bemærk i planen, at funktionen kun aktiveres én gang.
Nu kunne dette være en rigtig interessant øvelse for patienter at slå F5 gentagne gange, indtil du får to forskellige værdier. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END; Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D; Oversigt
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.