Denne artikel er fjerde del i en serie om tabeludtryk. I del 1 og del 2 dækkede jeg den konceptuelle behandling af afledte tabeller. I del 3 begyndte jeg at dække optimeringsovervejelser af afledte tabeller. Denne måned dækker jeg yderligere aspekter af optimering af afledte tabeller; specifikt fokuserer jeg på substitution/unnesting af afledte tabeller.
I mine eksempler vil jeg bruge eksempeldatabaser kaldet TSQLV5 og PerformanceV5. Du kan finde scriptet, der opretter og udfylder TSQLV5 her, og dets ER-diagram her. Du kan finde scriptet, der opretter og udfylder PerformanceV5 her.
Unnesting/substitution
Unnesting/substitution af tabeludtryk er en proces med at tage en forespørgsel, der involverer indlejring af tabeludtryk, og som om at erstatte den med en forespørgsel, hvor den indlejrede logik er elimineret. Jeg skal understrege, at der i praksis ikke er nogen egentlig proces, hvor SQL Server konverterer den originale forespørgselsstreng med den indlejrede logik til en ny forespørgselsstreng uden indlejring. Det, der rent faktisk sker, er, at forespørgselsparsingsprocessen producerer et indledende træ af logiske operatorer, der nøje afspejler den oprindelige forespørgsel. Derefter anvender SQL Server transformationer til dette forespørgselstræ, hvilket eliminerer nogle af de unødvendige trin, kollapser flere trin til færre trin og flytter operatører rundt. I sine transformationer, så længe visse betingelser er opfyldt, kan SQL Server flytte tingene rundt på tværs af det, der oprindeligt var tabeludtryksgrænser – nogle gange effektivt, som om de indlejrede enheder blev fjernet. Alt dette i et forsøg på at finde en optimal plan.
I denne artikel dækker jeg både tilfælde, hvor en sådan unnesting finder sted, såvel som unnesting-hæmmere. Det vil sige, at når du bruger visse forespørgselselementer, forhindrer det SQL Server i at kunne flytte logiske operatorer i forespørgselstræet, hvilket tvinger den til at behandle operatorerne baseret på grænserne for de tabeludtryk, der blev brugt i den oprindelige forespørgsel.
Jeg starter med at demonstrere et simpelt eksempel, hvor afledte tabeller bliver uindlejrede. Jeg vil også demonstrere et eksempel på en hæmmende hæmmer. Jeg vil derefter tale om usædvanlige tilfælde, hvor unnesting kan være uønsket, hvilket resulterer i enten fejl eller ydeevneforringelse, og demonstrere, hvordan man forhindrer unnesting i disse tilfælde ved at bruge en unnesting-hæmmer.
Den følgende forespørgsel (vi kalder den forespørgsel 1) bruger flere indlejrede lag af afledte tabeller, hvor hvert af tabeludtrykkene anvender grundlæggende filtreringslogik baseret på konstanter:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Som du kan se, filtrerer hvert af tabeludtrykkene et interval af ordredatoer, der starter med en anden dato. SQL Server ophæver denne flerlagede forespørgselslogik, som gør den i stand til derefter at flette de fire filtreringsprædikater til et enkelt, der repræsenterer skæringspunktet mellem alle fire prædikater.
Undersøg planen for forespørgsel 1 vist i figur 1.
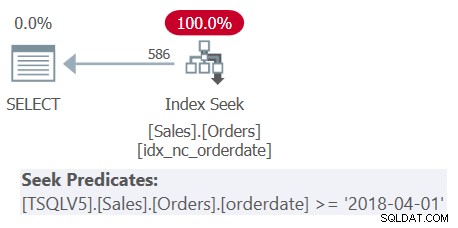 Figur 1:Plan for forespørgsel 1
Figur 1:Plan for forespørgsel 1
Bemærk, at alle fire filtreringsprædikater blev slået sammen til et enkelt prædikat, der repræsenterer skæringspunktet mellem de fire. Planen anvender en søgning i indekset idx_nc_orderdate baseret på det enkelte fusionerede prædikat som søgeprædikatet. Dette indeks er defineret på orderdate (eksplicit), orderid (implicit på grund af tilstedeværelsen af et klynget indeks på orderid) som indeksnøglerne.
Bemærk også, at selvom alle tabeludtryk bruger SELECT * og kun den yderste forespørgsel projicerer de to kolonner af interesse:orderdate og orderid, anses det førnævnte indeks for at dække. Som jeg forklarede i del 3, ignorerer SQL Server af optimeringsformål såsom valg af indeks de kolonner fra tabeludtrykkene, som i sidste ende ikke er relevante. Husk dog, at du skal have tilladelser til at forespørge på disse kolonner.
Som nævnt vil SQL Server forsøge at fjerne tabeludtryk, men vil undgå unnesting, hvis den støder ind i en unnesting-hæmmer. Med en vis undtagelse, som jeg vil beskrive senere, vil brugen af TOP eller OFFSET FETCH hæmme unnesting. Årsagen er, at forsøg på at fjerne et tabeludtryk med TOP eller OFFSET FETCH kan resultere i en ændring af den oprindelige forespørgsels betydning.
Som et eksempel kan du overveje følgende forespørgsel (vi kalder det forespørgsel 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Det indtastede antal rækker til TOP-filteret er en BIGINT-type værdi. I dette eksempel bruger jeg den maksimale BIGINT-værdi (2^63 – 1, beregne i T-SQL ved hjælp af SELECT POWER(2., 63) – 1). Selvom du og jeg ved, at vores Ordrer-tabel aldrig vil have så mange rækker, og derfor er TOP-filteret virkelig meningsløst, så skal SQL Server tage højde for den teoretiske mulighed for, at filteret er meningsfuldt. Som følge heraf fjerner SQL Server ikke tabeludtrykkene i denne forespørgsel. Planen for forespørgsel 2 er vist i figur 2.
 Figur 2:Plan for forespørgsel 2
Figur 2:Plan for forespørgsel 2
De unnesting-inhibitorer forhindrede SQL Server i at kunne flette filtreringsprædikaterne, hvilket fik planformen til at ligne den konceptuelle forespørgsel. Det er dog interessant at observere, at SQL Server stadig ignorerede de kolonner, der i sidste ende ikke var relevante for den yderste forespørgsel, og derfor var i stand til at bruge det dækkende indeks på orderdate, orderid.
For at illustrere hvorfor TOP og OFFSET-FETCH er unnesting-hæmmere, lad os tage en simpel prædikat-pushdown-optimeringsteknik. Prædikat-pushdown betyder, at optimeringsværktøjet skubber et filterprædikat til et tidligere punkt sammenlignet med det oprindelige punkt, som det vises i den logiske forespørgselsbehandling. Antag for eksempel, at du har en forespørgsel med både en indre joinforbindelse og et WHERE-filter baseret på en kolonne fra en af siderne af joinforbindelsen. Med hensyn til logisk forespørgselsbehandling formodes WHERE-filteret at blive evalueret efter joinforbindelsen. Men ofte vil optimeringsværktøjet skubbe filterprædikatet til et trin før joinforbindelsen, da dette efterlader joinforbindelsen med færre rækker at arbejde med, hvilket typisk resulterer i en mere optimal plan. Husk dog, at sådanne transformationer kun er tilladt i tilfælde, hvor betydningen af den oprindelige forespørgsel er bevaret, i den forstand, at du er garanteret at få det korrekte resultatsæt.
Overvej følgende kode, som har en ydre forespørgsel med et WHERE-filter mod en afledt tabel, som igen er baseret på et tabeludtryk med et TOP-filter:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101'; Denne forespørgsel er naturligvis ikke-deterministisk på grund af manglen på en ORDER BY-klausul i tabeludtrykket. Da jeg kørte det, fik SQL Server tilfældigvis adgang til de første tre rækker med ordredatoer tidligere end 2018, så jeg fik et tomt sæt som output:
orderid orderdate ----------- ---------- (0 rows affected)
Som nævnt forhindrede brugen af TOP i tabeludtrykket unnesting/substitution af tabeludtrykket her. Hvis SQL Server havde fjernet tabeludtrykket, ville substitutionsprocessen have resulteret i, hvad der svarer til følgende forespørgsel:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101';
Denne forespørgsel er også ikke-deterministisk på grund af manglen på ORDER BY-klausul, men den har klart en anden betydning end den oprindelige forespørgsel. Hvis tabellen Sales.Orders har mindst tre ordrer placeret i 2018 eller senere – og det gør den – vil denne forespørgsel nødvendigvis returnere tre rækker i modsætning til den oprindelige forespørgsel. Her er resultatet, jeg fik, da jeg kørte denne forespørgsel:
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)
Hvis den ikke-deterministiske karakter af ovenstående to forespørgsler forvirrer dig, er her et eksempel med en deterministisk forespørgsel:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid; Tabeludtrykket filtrerer de tre ordrer med de laveste ordens-id'er. Den ydre forespørgsel filtrerer derefter fra disse tre ordrer kun dem, der blev afgivet den 8. juli 2017 eller senere. Det viser sig, at der kun er én kvalificerende ordre. Denne forespørgsel genererer følgende output:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
Antag, at SQL Server fjernede tabeludtrykket i den oprindelige forespørgsel, hvor substitutionsprocessen resulterede i følgende forespørgselækvivalent:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20170708' ORDER BY orderid;
Betydningen af denne forespørgsel er anderledes end den oprindelige forespørgsel. Denne forespørgsel filtrerer først de ordrer, der blev afgivet den 8. juli 2017 eller senere, og filtrerer derefter de tre øverste blandt dem med de laveste ordre-id'er. Denne forespørgsel genererer følgende output:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)
For at undgå at ændre betydningen af den oprindelige forespørgsel, anvender SQL Server ikke unnesting/substitution her.
De sidste to eksempler involverede en simpel blanding af WHERE- og TOP-filtrering, men der kan være yderligere modstridende elementer som følge af unnesting. For eksempel, hvad hvis du har forskellige bestillingsspecifikationer i tabeludtrykket og den ydre forespørgsel, som i følgende eksempel:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid; Du indser, at hvis SQL Server fjernede tabeludtrykket og kollapsede de to forskellige rækkefølgespecifikationer til én, ville den resulterende forespørgsel have haft en anden betydning end den oprindelige forespørgsel. Det ville enten have filtreret de forkerte rækker eller præsenteret resultatrækkerne i den forkerte præsentationsrækkefølge. Kort sagt, du er klar over, hvorfor det sikre for SQL Server at gøre er at undgå unnesting/substitution af tabeludtryk, der er baseret på TOP- og OFFSET-FETCH-forespørgsler.
Jeg nævnte tidligere, at der er en undtagelse fra reglen om, at brugen af TOP og OFFSET-FETCH forhindrer unnesting. Det er, når du bruger TOP (100) PERCENT i et indlejret tabeludtryk, med eller uden et ORDER BY-udtryk. SQL Server indser, at der ikke er nogen reel filtrering i gang og optimerer muligheden. Her er et eksempel, der viser dette:
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; TOP-filteret ignoreres, unnesting finder sted, og du får den samme plan som den, der er vist tidligere for forespørgsel 1 i figur 1.
Når du bruger OFFSET 0 ROWS uden FETCH-sætning i et indlejret tabeludtryk, er der heller ingen reel filtrering i gang. Så teoretisk set kunne SQL Server også have optimeret denne mulighed og aktiveret unnesting, men på datoen for denne skrivning gør den det ikke. Her er et eksempel, der viser dette:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401'; Du får den samme plan som den, der er vist tidligere for forespørgsel 2 i figur 2, hvilket viser, at der ikke fandt nogen unnesting sted.
Tidligere forklarede jeg, at unnesting/substitution-processen ikke rigtig genererer en ny forespørgselsstreng, der derefter bliver optimeret, snarere har at gøre med transformationer, som SQL Server anvender til træet af logiske operatorer. Der er en forskel mellem den måde, SQL Server optimerer en forespørgsel på med indlejrede tabeludtryk versus en faktisk logisk ækvivalent forespørgsel uden indlejring. Brugen af tabeludtryk, såsom afledte tabeller, samt underforespørgsler forhindrer simpel parameterisering. Genkald forespørgsel 1 vist tidligere i artiklen:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Da forespørgslen bruger afledte tabeller, finder simpel parameterisering ikke sted. Det vil sige, at SQL Server ikke erstatter konstanterne med parametre og derefter optimerer forespørgslen, snarere optimerer forespørgslen med konstanterne. Med prædikater baseret på konstanter kan SQL Server flette de krydsende perioder, hvilket i vores tilfælde resulterede i et enkelt prædikat i planen, som vist tidligere i figur 1.
Overvej derefter følgende forespørgsel (vi kalder det forespørgsel 3), som er en logisk ækvivalent til forespørgsel 1, men hvor du selv anvender unnesting:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401';
Planen for denne forespørgsel er vist i figur 3.
 Figur 3:Plan for forespørgsel 3
Figur 3:Plan for forespørgsel 3
Denne plan anses for at være sikker til simpel parametrering, så konstanterne erstattes med parametre, og prædikaterne flettes derfor ikke sammen. Motivationen for parameterisering er naturligvis at øge sandsynligheden for plangenbrug, når der udføres lignende forespørgsler, der kun adskiller sig i de konstanter, de bruger.
Som nævnt forhindrede brugen af afledte tabeller i Query 1 simpel parameterisering. På samme måde ville brugen af underforespørgsler forhindre simpel parameterisering. For eksempel, her er vores tidligere forespørgsel 3 med et meningsløst prædikat baseret på en underforespørgsel tilføjet til WHERE-sætningen:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401' AND (SELECT 42) = 42;
Denne gang finder simpel parameterisering ikke sted, hvilket gør det muligt for SQL Server at flette de krydsende perioder repræsenteret af prædikaterne med konstanterne, hvilket resulterer i den samme plan som vist tidligere i figur 1.
Hvis du har forespørgsler med tabeludtryk, der bruger konstanter, og det er vigtigt for dig, at SQL Server parametrerede koden, og du af en eller anden grund ikke selv kan parametrere den, så husk, at du har mulighed for at bruge tvungen parametrering med en planguide. Som et eksempel opretter følgende kode en sådan planvejledning til forespørgsel 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)'; Kør forespørgsel 3 igen efter oprettelse af planvejledningen:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Du får den samme plan som den, der er vist tidligere i figur 3 med de parametriserede prædikater.
Når du er færdig, skal du køre følgende kode for at slippe planvejledningen:
EXEC sys.sp_control_plan_guide @operation = N'DROP', @name = N'TG1';
Forebyggelse af unnesting
Husk, at SQL Server ophæver tabeludtryk af optimeringsårsager. Målet er at øge sandsynligheden for at finde en plan med en lavere pris sammenlignet med uden unnesting. Det gælder for de fleste transformationsregler, der anvendes af optimeringsværktøjet. Der kan dog være nogle usædvanlige tilfælde, hvor du ønsker at forhindre unesting. Dette kan enten være for at undgå fejl (ja i nogle usædvanlige tilfælde kan unnesting resultere i fejl) eller af præstationsmæssige årsager for at tvinge en bestemt planform, svarende til at bruge andre præstationstip. Husk, du har en enkel måde at forhindre unnesting ved at bruge TOP med et meget stort tal.
Eksempel på at undgå fejl
Jeg starter med et tilfælde, hvor unnesting af tabeludtryk kan resultere i fejl.
Overvej følgende forespørgsel (vi kalder den forespørgsel 4):
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
Dette eksempel er en smule konstrueret i den forstand, at det er nemt at omskrive det andet filterprædikat, så det aldrig ville resultere i en fejl (rabat <0,1), men det er et praktisk eksempel for mig at illustrere min pointe. Rabatter er ikke-negative. Så selvom der er ordrelinjer med nul rabat, skal forespørgslen filtrere dem fra (det første filterprædikat siger, at rabatten skal være større end minimumsrabatten i tabellen). Der er dog ingen sikkerhed for, at SQL Server vil evaluere prædikaterne i skriftlig rækkefølge, så du kan ikke regne med en kortslutning.
Undersøg planen for forespørgsel 4 vist i figur 4.
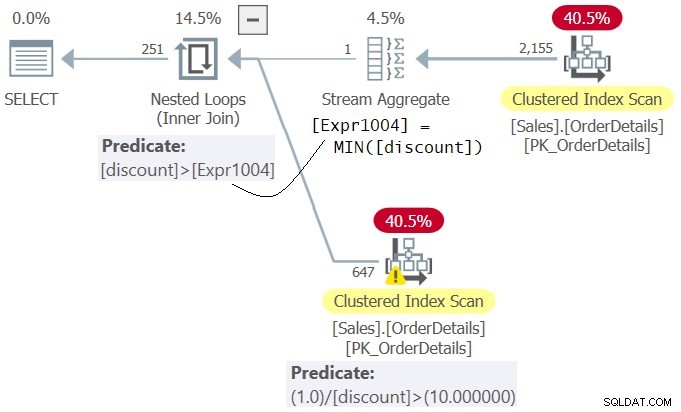 Figur 4:Plan for forespørgsel 4
Figur 4:Plan for forespørgsel 4
Bemærk, at i planen evalueres prædikatet 1.0 / rabat> 10.0 (anden i WHERE-klausulen) før prædikatrabatten>
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Måske tænker du, at du kan undgå fejlen ved at bruge en afledt tabel, der adskiller filtreringsopgaverne til en indre og en ydre, som sådan:
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; SQL Server anvender imidlertid unnesting af den afledte tabel, hvilket resulterer i den samme plan som vist tidligere i figur 4, og følgelig fejler denne kode også med en divider med nul-fejl:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
En simpel løsning her er at introducere en unesting-hæmmer, som sådan (vi kalder denne løsning forespørgsel 5):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; Planen for forespørgsel 5 er vist i figur 5.
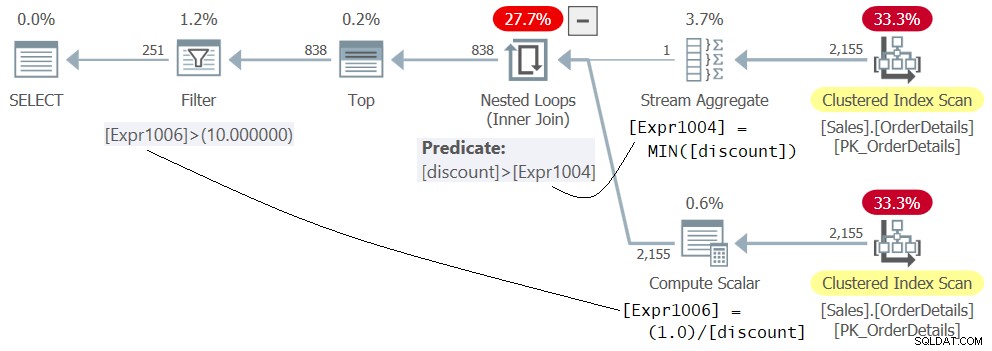 Figur 5:Plan for forespørgsel 5
Figur 5:Plan for forespørgsel 5
Bliv ikke forvirret over det faktum, at udtrykket 1.0 / rabat vises i den indre del af Nested Loops-operatoren, som om det blev evalueret først. Dette er blot definitionen af medlemmet Expr1006. Den faktiske evaluering af prædikatet Expr1006> 10.0 anvendes af Filter-operatoren som det sidste trin i planen, efter at rækkerne med minimumsrabat blev filtreret ud af Nested Loops-operatøren tidligere. Denne løsning kører uden fejl.
Eksempel på grund af ydeevne
Jeg fortsætter med et tilfælde, hvor unnesting af tabeludtryk kan skade ydeevnen.
Start med at køre følgende kode for at skifte kontekst til PerformanceV5-databasen og aktivere STATISTICS IO og TIME:
USE PerformanceV5; SET STATISTICS IO, TIME ON;
Overvej følgende forespørgsel (vi kalder den forespørgsel 6):
SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid;
Optimizeren identificerer et understøttende dækkende indeks med shipperid og orderdate som de førende nøgler. Så den opretter en plan med en bestilt scanning af indekset efterfulgt af en ordrebaseret Stream Aggregate-operatør, som vist i planen for Query 6 i figur 6.
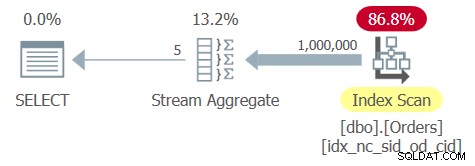 Figur 6:Plan for forespørgsel 6
Figur 6:Plan for forespørgsel 6
Tabellen Ordrer har 1.000.000 rækker, og grupperingskolonnen shipperid er meget tæt – der er kun 5 forskellige afsender-id'er, hvilket resulterer i 20 % tæthed (gennemsnitlig procent pr. særskilt værdi). Anvendelse af en fuld scanning af indeksbladet involverer læsning af et par tusinde sider, hvilket resulterer i en køretid på omkring en tredjedel af et sekund på mit system. Her er præstationsstatistikken, som jeg fik for udførelsen af denne forespørgsel:
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
Indekstræet er i øjeblikket tre niveauer dybt.
Lad os skalere antallet af ordrer med en faktor på 1.000 til 1.000.000.000, men stadig med kun 5 forskellige afsendere. Antallet af sider i indeksbladet ville vokse med en faktor 1.000, og indekstræet ville sandsynligvis resultere i et ekstra niveau (fire niveauer dybt). Denne plan har lineær skalering. Du ville ende med tæt på 4.000.000 logiske læsninger og en køretid på et par minutter.
Når du skal beregne et MIN- eller MAX-aggregat mod en stor tabel med meget høj tæthed i grupperingskolonnen (vigtigt!), og et understøttende B-træindeks, der er indtastet på grupperingskolonnen og aggregeringskolonnen, er der en meget mere optimal planform end den i figur 6. Forestil dig en planform, der scanner det lille sæt af afsender-id'er fra et eller andet indeks på afsendertabellen, og i en løkke anvender for hver afsender en søgning mod det understøttende indeks på ordrer for at opnå aggregatet. Med 1.000.000 rækker i tabellen ville 5 søgninger involvere 15 læsninger. Med 1.000.000.000 rækker ville 5 søgninger involvere 20 læsninger. Med en billion rækker, 25 læsninger i alt. Klart en meget mere optimal plan. Du kan faktisk opnå en sådan plan ved at forespørge i afsendertabellen og indhente aggregatet ved hjælp af en skalær aggregeret underforespørgsel mod ordrer, som sådan (vi kalder denne løsning forespørgsel 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid = S.shipperid) AS maxod FROM dbo.Shippers AS S;
Planen for denne forespørgsel er vist i figur 7.
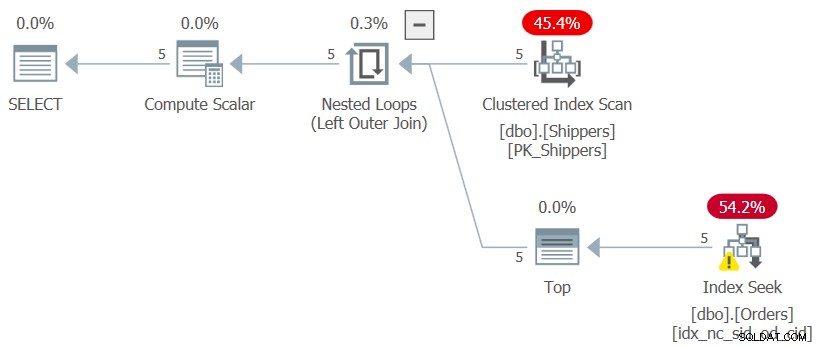 Figur 7:Plan for forespørgsel 7
Figur 7:Plan for forespørgsel 7
Den ønskede planform er opnået, og ydeevnetallene for udførelsen af denne forespørgsel er ubetydelige som forventet:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Så længe grupperingskolonnen er meget tæt, bliver størrelsen af tabellen Ordrer praktisk talt ubetydelig.
Men vent et øjeblik, før du skal fejre. Der er et krav om kun at beholde de afsendere, hvis maksimale relaterede ordredato i tabellen Ordrer er på eller efter 2018. Det lyder som en simpel nok tilføjelse. Definer en afledt tabel baseret på forespørgsel 7, og anvend filteret i den ydre forespørgsel på samme måde (vi kalder denne løsning for forespørgsel 8):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Desværre, SQL Server fjerner den afledte tabelforespørgsel, såvel som underforespørgslen, og konverterer aggregeringslogikken til den, der svarer til den grupperede forespørgselslogik, med shipperid som grupperingskolonnen. Og den måde, SQL Server kender til at optimere en grupperet forespørgsel, er baseret på en enkelt passage over inputdataene, hvilket resulterer i en plan, der ligner den, der er vist tidligere i figur 6, kun med det ekstra filter. Planen for forespørgsel 8 er vist i figur 8.
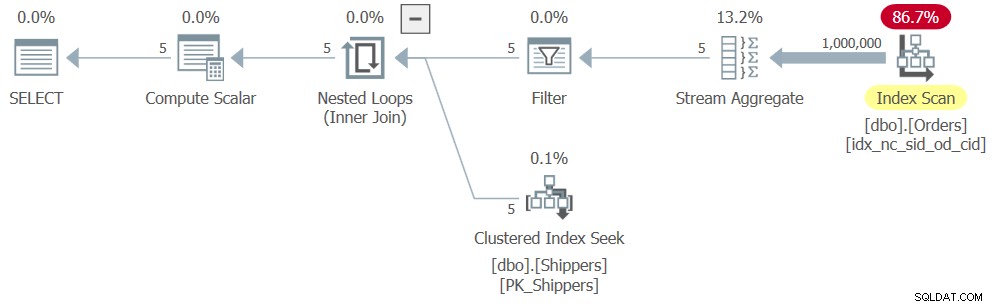 Figur 8:Plan for forespørgsel 8
Figur 8:Plan for forespørgsel 8
Som følge heraf er skaleringen lineær, og ydeevnetallene ligner dem for forespørgsel 6:
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
Løsningen er at introducere en unesting-hæmmer. Dette kan gøres ved at tilføje et TOP-filter til tabeludtrykket, som den afledte tabel er baseret på (vi kalder denne løsning Query 9):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Planen for denne forespørgsel er vist i figur 9 og har den ønskede planform med søgningerne:
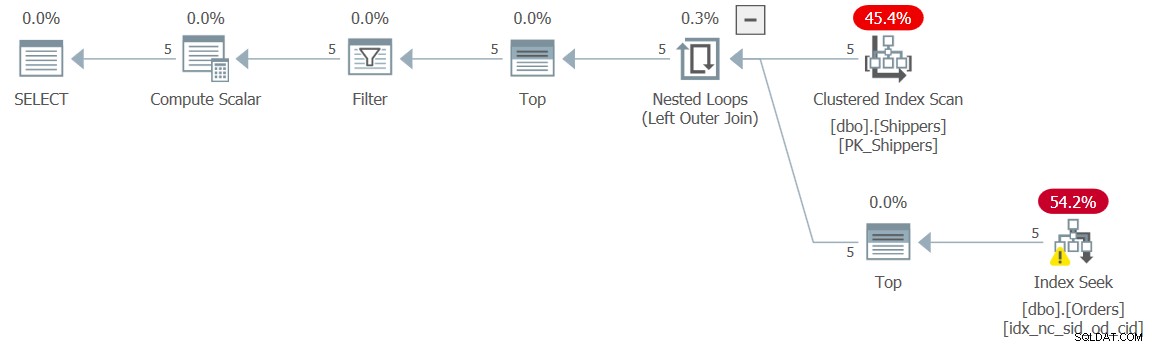 Figur 9:Plan for forespørgsel 9
Figur 9:Plan for forespørgsel 9
Ydeevnetallene for denne udførelse er selvfølgelig ubetydelige:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Endnu en mulighed er at forhindre unnesting af underforespørgslen ved at erstatte MAX-aggregatet med et tilsvarende TOP (1) filter, som sådan (vi kalder denne løsning forespørgsel 10):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Planen for denne forespørgsel er vist i figur 10 og har igen den ønskede form med søgningerne.
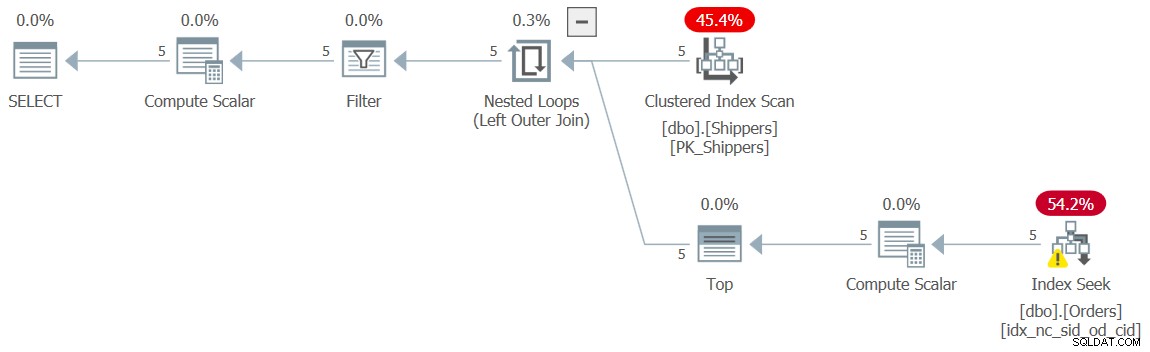 Figur 10:Plan for forespørgsel 10
Figur 10:Plan for forespørgsel 10
Jeg fik de velkendte ubetydelige præstationstal for denne udførelse:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Når du er færdig, skal du køre følgende kode for at stoppe med at rapportere effektivitetsstatistikker:
SET STATISTICS IO, TIME OFF;
Oversigt
I denne artikel fortsatte jeg den diskussion, jeg startede i sidste måned om optimering af afledte tabeller. I denne måned fokuserede jeg på unnesting af afledte tabeller. Jeg forklarede, at typisk unnesting resulterer i en mere optimal plan sammenlignet med uden unnesting, men dækkede også eksempler, hvor det er uønsket. Jeg viste et eksempel, hvor unnesting resulterede i en fejl samt et eksempel, der resulterede i ydeevneforringelse. Jeg demonstrerede, hvordan man forhindrer unnesting ved at anvende en unnesting inhibitor som TOP.
Næste måned fortsætter jeg udforskningen af navngivne tabeludtryk og flytter fokus til CTE'er.