I den første del af denne blogserie har jeg præsenteret et par benchmarkresultater, der viser, hvordan PostgreSQL OLTP-ydeevnen ændrede sig siden 8.3, udgivet i 2008. I denne del planlægger jeg at gøre det samme, men for analytiske / BI-forespørgsler, der behandler store mængder af data.
Der er en række branchebenchmarks for at teste denne arbejdsbyrde, men nok den mest almindeligt brugte er TPC-H, så det er det, jeg vil bruge til dette blogindlæg. Der er også TPC-DS, et andet TPC-benchmark til test af beslutningsstøttesystemer, som kan ses som en udvikling eller erstatning af TPC-H. Jeg har besluttet at holde mig til TPC-H af et par grunde.
For det første er TPC-DS meget mere kompleks, både hvad angår skema (flere tabeller) og antal forespørgsler (22 vs. 99). Det ville være meget sværere at indstille dette korrekt, især når man har at gøre med flere PostgreSQL-versioner. For det andet bruger nogle af TPC-DS-forespørgslerne funktioner, der ikke understøttes af ældre PostgreSQL-versioner (f.eks. grupperingssæt), hvilket gør disse forespørgsler irrelevante for nogle versioner. Og endelig vil jeg sige, at folk er meget mere fortrolige med TPC-H sammenlignet med TPC-DS.
Målet med dette er ikke at tillade sammenligning med andre databaseprodukter, kun at give en rimelig langsigtet karakterisering af, hvordan PostgreSQL-ydelsen har udviklet sig siden PostgreSQL 8.3.
Bemærk :For en meget interessant analyse af TPC-H benchmark anbefaler jeg på det kraftigste papiret "TPC-H Analyzed:Hidden Messages and Lessons Learned from an Influential Benchmark" fra Boncz, Neumann og Erling.
Hardwaren
De fleste af resultaterne i dette blogindlæg kommer fra den "større boks", jeg har på vores kontor, som har disse parametre:
- 2x E5-2620 v4 (16 kerner, 32 tråde)
- 64 GB RAM
- Intel Optane 900P 280 GB NVMe SSD (data)
- 3 x 7.2k SATA RAID0 (midlertidig tablespace)
- kerne 5.6.15, ext4 filsystem
Jeg er sikker på, at du kan købe betydeligt mere kraftige maskiner, men jeg mener, at dette er godt nok til at give os relevante data. Der var to konfigurationsvarianter - en med parallelitet deaktiveret, en med parallelitet aktiveret. De fleste af parameterværdierne er de samme i begge tilfælde, indstillet til tilgængelige hardwareressourcer (CPU, RAM, lager). Du kan finde en mere detaljeret information om konfigurationen i slutningen af dette indlæg.
Benchmark
Jeg vil gerne gøre det meget klart, at det ikke er mit mål at implementere et gyldigt TPC-H-benchmark, der kunne bestå alle de kriterier, der kræves af TPC. Mit mål er at evaluere, hvordan ydeevnen af forskellige analytiske forespørgsler ændrede sig over tid, ikke at jagte et abstrakt mål for ydeevne pr. dollar eller noget lignende.
Så jeg har besluttet kun at bruge en delmængde af TPC-H - i det væsentlige bare indlæse dataene og køre de 22 forespørgsler (samme parametre på alle versioner). Der er ingen dataopdateringer, datasættet er statisk efter den første indlæsning. Jeg har valgt en række skalafaktorer, 1, 10 og 75, så vi har resultater for fits-in-shared-buffers (1), fits-in-memory (10) og more-end-memory (75) . Jeg ville gå efter 100 for at gøre det til en "god sekvens", der i nogle tilfælde ikke ville passe ind i 280 GB lagerpladsen (takket være indekser, midlertidige filer osv.). Bemærk, at skalafaktor 75 ikke engang anerkendes af TPC-H som en gyldig skalafaktor.
Men giver det overhovedet mening at benchmarke 1GB eller 10GB datasæt? Folk har en tendens til at fokusere på meget større databaser, så det kan virke lidt dumt at besvære med at teste dem. Men jeg tror ikke, det ville være nyttigt – langt de fleste databaser i naturen er ret små, efter min erfaring. Og selv når hele databasen er stor, arbejder folk normalt kun med en lille delmængde af den – nyere data, uafklarede ordrer osv. Så jeg tror, det giver mening at teste selv med de små datasæt.
Data indlæses
Lad os først se, hvor lang tid det tager at indlæse data i databasen - uden og med parallelitet. Jeg viser kun resultater fra datasættet på 75 GB, fordi den overordnede adfærd er næsten den samme for de mindre sager.
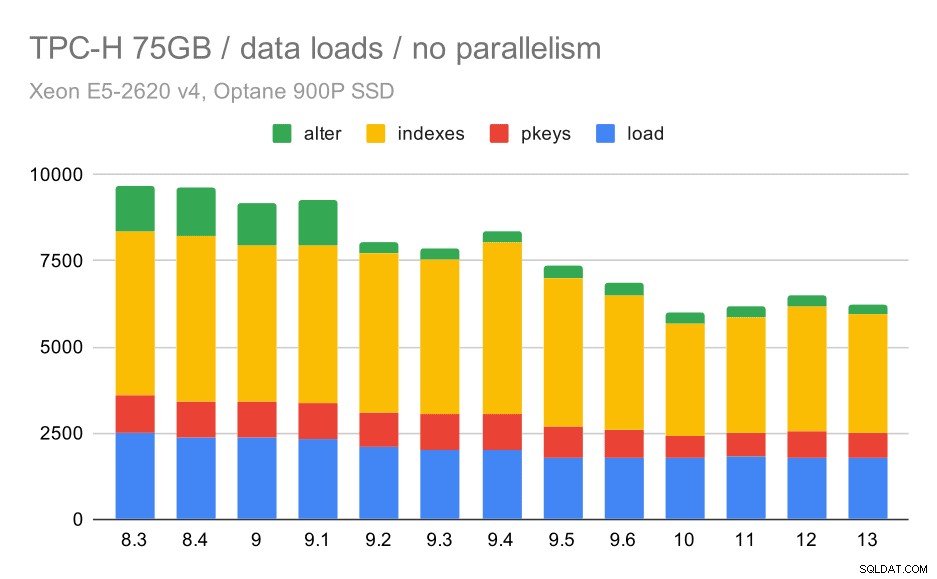
TPC-H-dataindlæsningsvarighed – skala 75 GB, ingen parallelitet
Du kan tydeligt se, at der er en konstant tendens til forbedringer, der barberer omkring 30% af varigheden af blot ved at forbedre effektiviteten i alle fire trin – KOPIERING, oprettelse af primærnøgler og indekser og (især) opsætning af fremmednøgler. "Alter"-forbedringen i 9.2 er særlig tydelig.
| KOPI | PKEYS | INDEKSER | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Lad os nu se, hvordan aktivering af parallelisme ændrer adfærden. Følgende diagram sammenligner resultater med parallelitet aktiveret - markeret med "(p)" - med resultater med parallelitet deaktiveret.
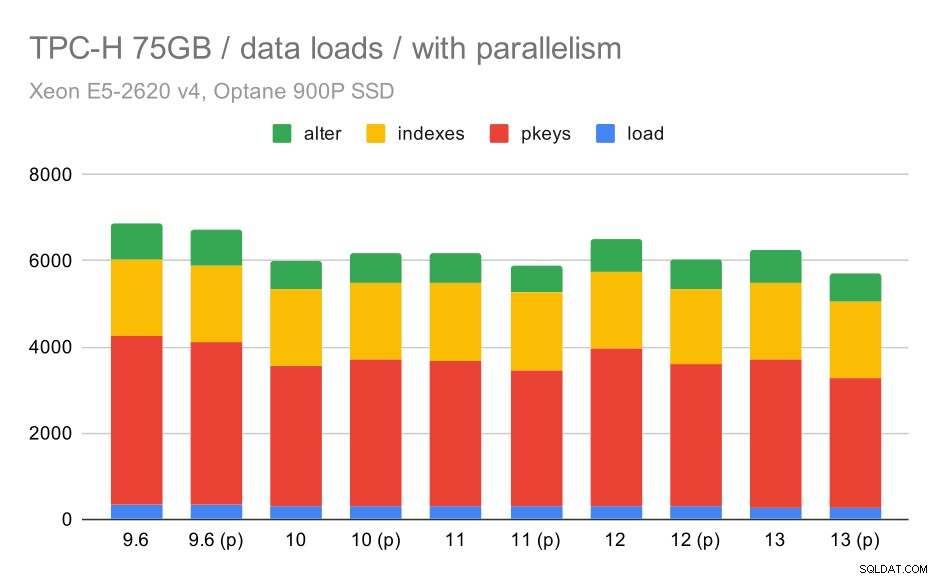
TPC-H-dataindlæsningsvarighed – skala 75 GB, parallelitet aktiveret.
Desværre ser det ud til, at effekten af parallelisme er meget begrænset i denne test - det hjælper en smule, men forskellene er ret små. Så den samlede forbedring forbliver omkring 30 %.
| KOPI | PKEYS | INDEKSER | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Forespørgsler
Nu kan vi tage et kig på forespørgsler. TPC-H har 22 forespørgselsskabeloner - jeg har genereret et sæt faktiske forespørgsler og kørte dem på alle versioner to gange - først efter at have droppet alle caches og genstartet forekomsten, derefter med den opvarmede cache. Alle numrene i diagrammerne er de bedste af disse to kørsler (i de fleste tilfælde er det selvfølgelig den anden).
Ingen parallelitet
Uden parallelitet er resultaterne på det mindste datasæt ret klare - hver søjle er opdelt i flere dele med forskellige farver for hver af de 22 forespørgsler. Det er svært at sige, hvilken del der er knyttet til den nøjagtige forespørgsel, men det er tilstrækkeligt til at identificere tilfælde, hvor én forespørgsel forbedres eller bliver meget værre mellem to kørsler. For eksempel i det første diagram er det meget tydeligt, at Q21 blev meget hurtigere mellem 8,3 og 8,4.
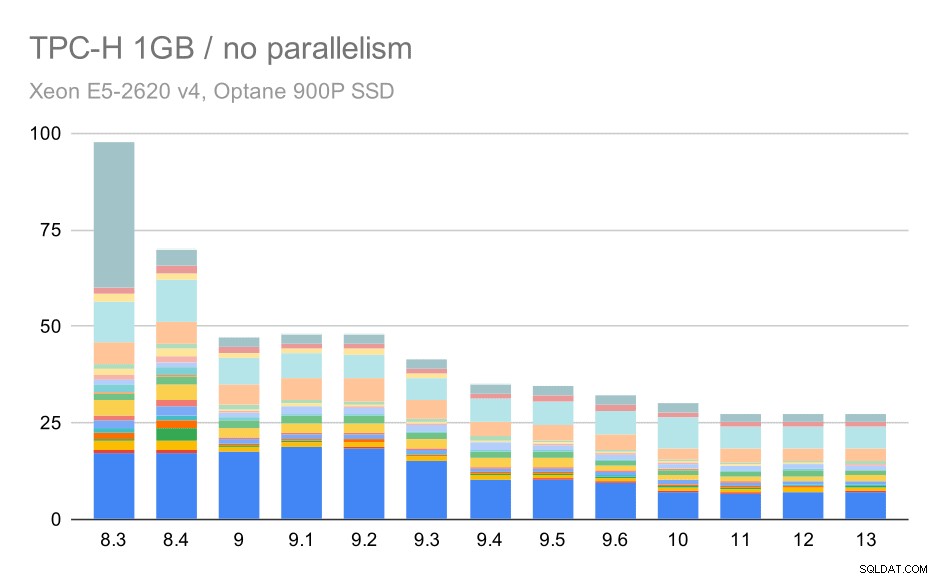
TPC-H-forespørgsler på små datasæt (1 GB) – parallelitet deaktiveret
For 10GB-skalaen er resultaterne noget svære at fortolke, for på 8.3 tager en af forespørgslerne (Q21) så lang tid at udføre, at den overskygger alt andet.
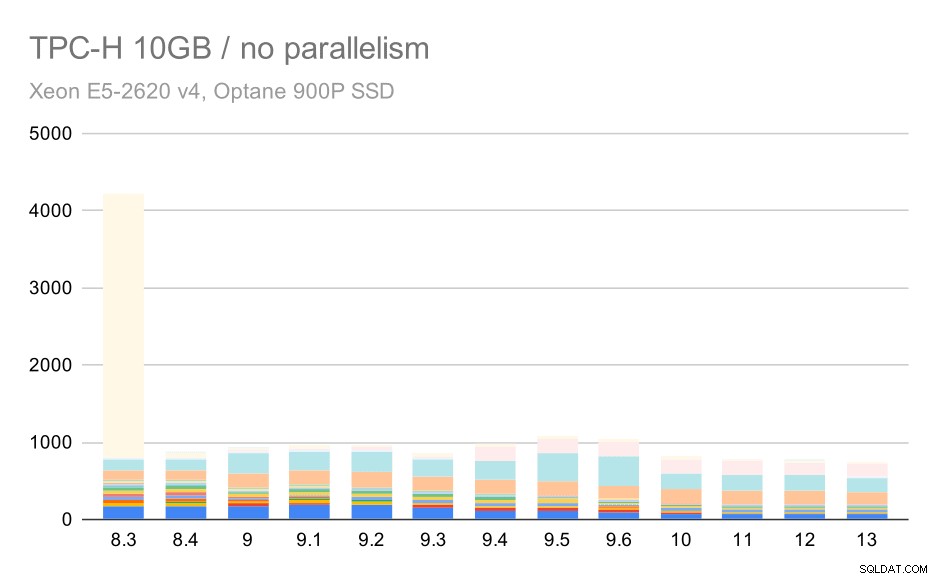
TPC-H-forespørgsler på medium datasæt (10 GB) – parallelitet deaktiveret
Så lad os se, hvordan diagrammet ville se ud uden Q21:
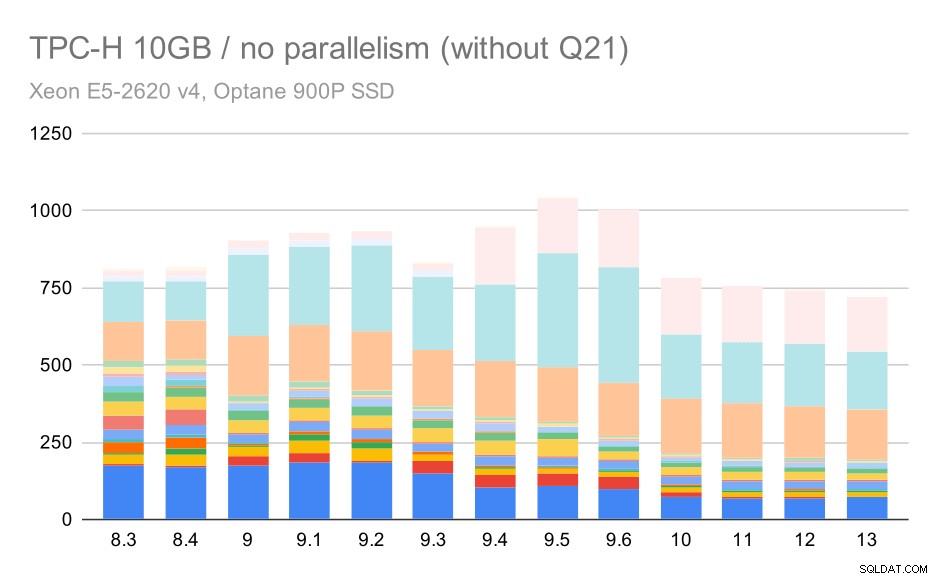
TPC-H-forespørgsler på medium datasæt (10 GB) – parallelitet deaktiveret, uden problematisk Q2
OK, det er nemmere at læse. Vi kan tydeligt se, at de fleste af forespørgslerne (op til Q17) blev hurtigere, men så blev to af forespørgslerne (Q18 og Q20) noget langsommere. Vi vil se et lignende problem på det største datasæt, så jeg vil diskutere, hvad der kan være årsagen.
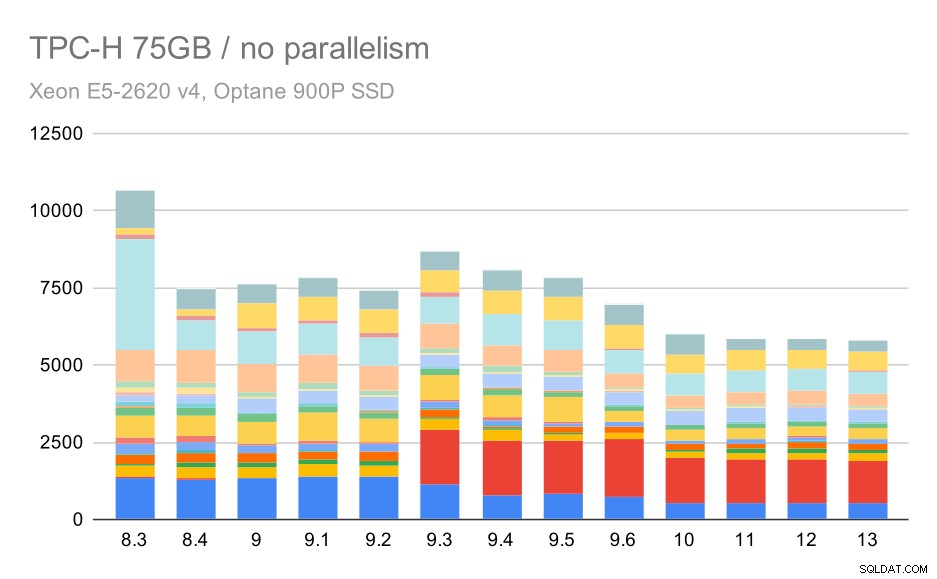
TPC-H-forespørgsler på stort datasæt (75 GB) – parallelitet deaktiveret
Igen ser vi en pludselig stigning for en af forespørgslerne i 9.3 - denne gang er det Q2, uden hvilket diagrammet ser sådan ud:
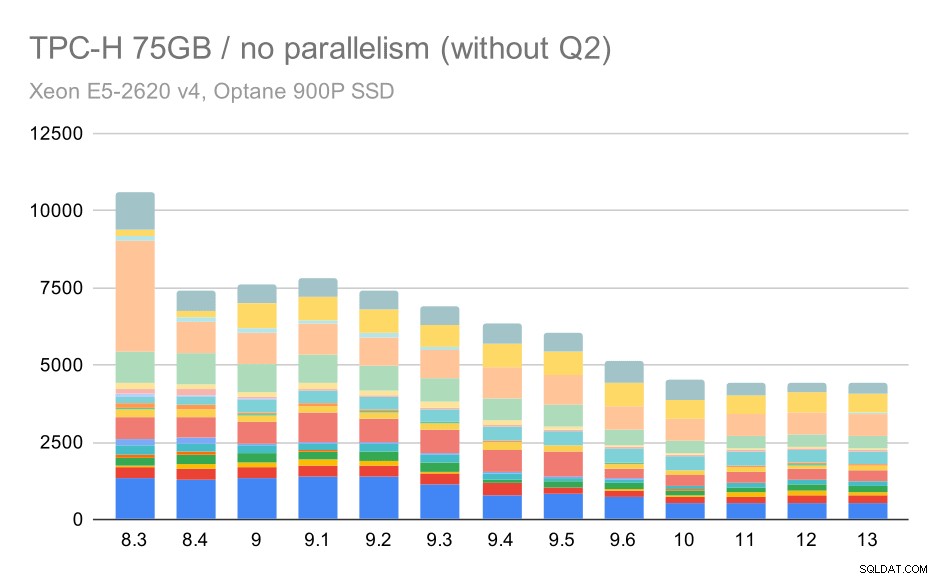
TPC-H-forespørgsler på stort datasæt (75 GB) – parallelitet deaktiveret, uden problematisk 2. kvartal
Det er generelt en ret pæn forbedring, der fremskynder hele udførelsen fra ~2,7 timer til kun ~1,2 timer, blot ved at gøre planlæggeren og optimeringsværktøjet smartere og ved at gøre udføreren mere effektiv (husk, at paralleliteten blev deaktiveret i disse kørsler) .
Så hvad kan problemet være med Q2, hvilket gør det langsommere i 9.3? Det enkle svar er, at hver gang du gør planlæggeren og optimizeren smartere – enten ved at konstruere nye typer stier/planer, eller ved at gøre den afhængig af nogle statistikker, betyder det også, at der kan begås nye fejl, når statistikken eller estimaterne er forkerte. I Q2 refererer WHERE-sætningen til en samlet underforespørgsel – en forenklet version af forespørgslen kan se sådan ud:
megetProblemet er, at vi ikke kender gennemsnitsværdien på planlægningstidspunktet, hvilket gør det umuligt at beregne tilstrækkeligt gode estimater for WHERE-tilstanden. Det faktiske 2. kvartal indeholder yderligere joinforbindelser, og planlægningen af disse afhænger grundlæggende af gode skøn over de sammenføjede relationer. I ældre versioner ser optimeringsværktøjet ud til at have gjort det rigtige, men så i 9.3 gjorde vi det smartere på en eller anden måde, men med det dårlige skøn formår det ikke at træffe den rigtige beslutning. Med andre ord var de gode planer i ældre versioner bare held, takket være planlæggerens begrænsninger.
Jeg vil vædde på, at regressionerne af Q18 og Q20 på det mindre datasæt også er forårsaget af noget lignende, selvom jeg ikke har undersøgt dem i detaljer.
Jeg tror, at nogle af disse optimeringsproblemer kan løses ved at justere omkostningsparametrene (f.eks. random_page_cost osv.), men jeg har ikke prøvet det på grund af tidsbegrænsninger. Det viser dog, at opgraderinger ikke automatisk forbedrer alle forespørgsler - nogle gange kan en opgradering udløse en regression, så passende test af din applikation er en god idé.
Parallelisme
Så lad os se, hvor meget forespørgselsparallelisme ændrer resultaterne. Igen ser vi kun på resultater fra udgivelser siden 9.6 mærkning af resultater med "(p)", hvor parallel forespørgsel er aktiveret.
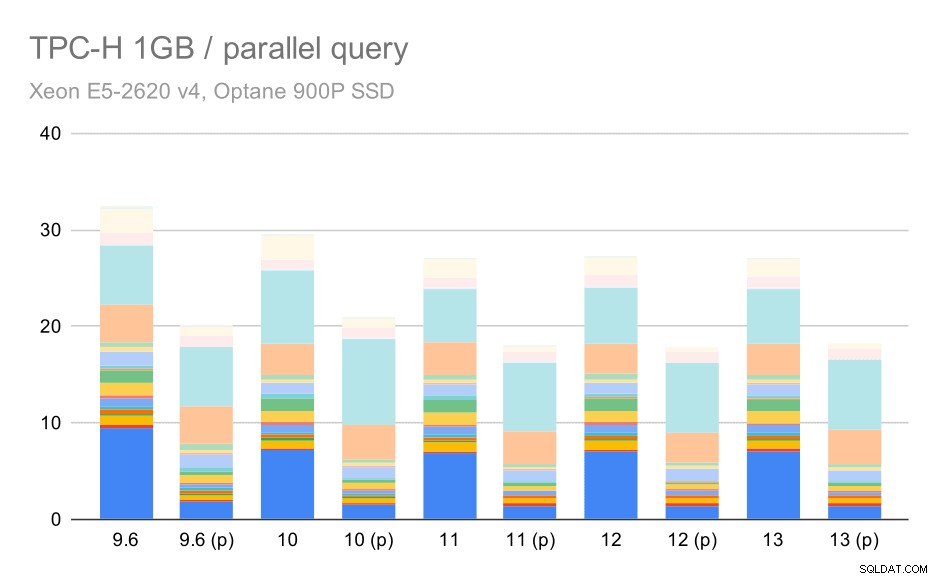
TPC-H-forespørgsler på små datasæt (1 GB) – parallelitet aktiveret
Det er klart, at parallelisme hjælper en hel del - det barberer omkring 30% af selv på dette lille datasæt. På det mellemstore datasæt er der ikke meget forskel mellem almindelige og parallelle kørsler:
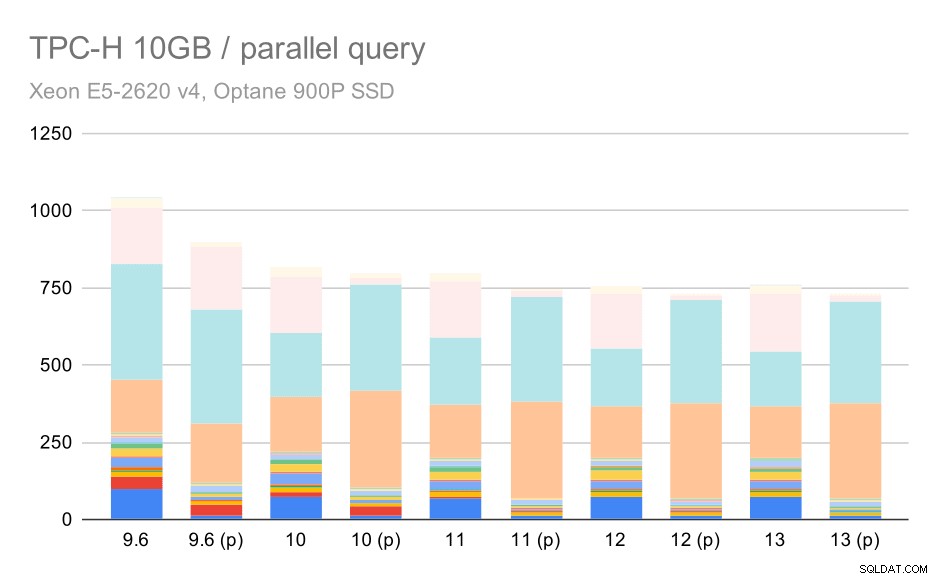
TPC-H-forespørgsler på medium datasæt (10 GB) – parallelitet aktiveret
Dette er endnu en demonstration af det allerede diskuterede problem – at muliggøre parallelitet gør det muligt at overveje yderligere forespørgselsplaner, og det er klart, at estimaterne eller omkostningerne ikke stemmer overens med virkeligheden, hvilket resulterer i dårlige planvalg.
Og endelig det store datasæt, hvor de komplette resultater ser således ud:
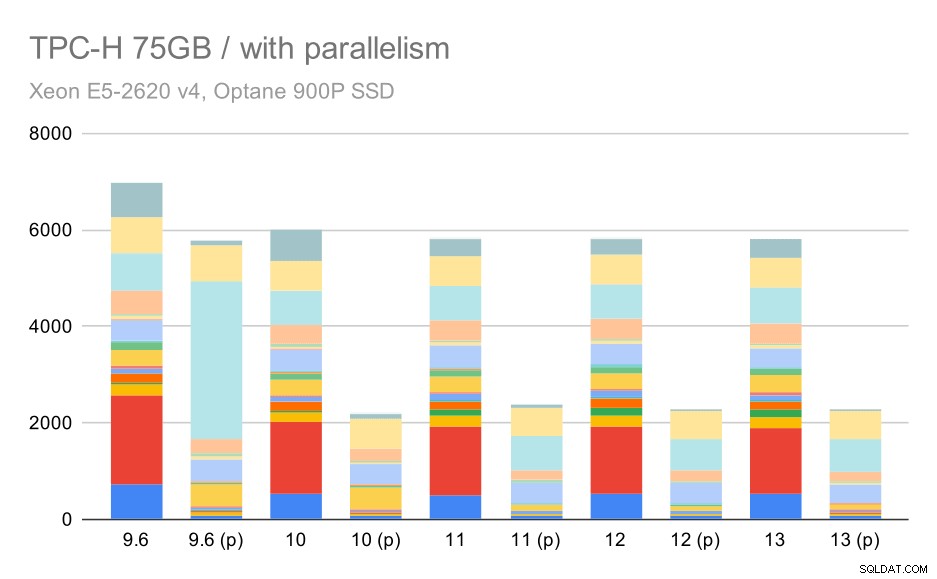
TPC-H-forespørgsler på stort datasæt (75 GB) – parallelitet aktiveret
Her virker det til vores fordel at aktivere parallelismen – optimeringsværktøjet formår at bygge en billigere parallelplan for Q2, der tilsidesætter det dårlige planvalg introduceret i 9.3. Men for fuldstændighedens skyld er her resultaterne uden Q2.
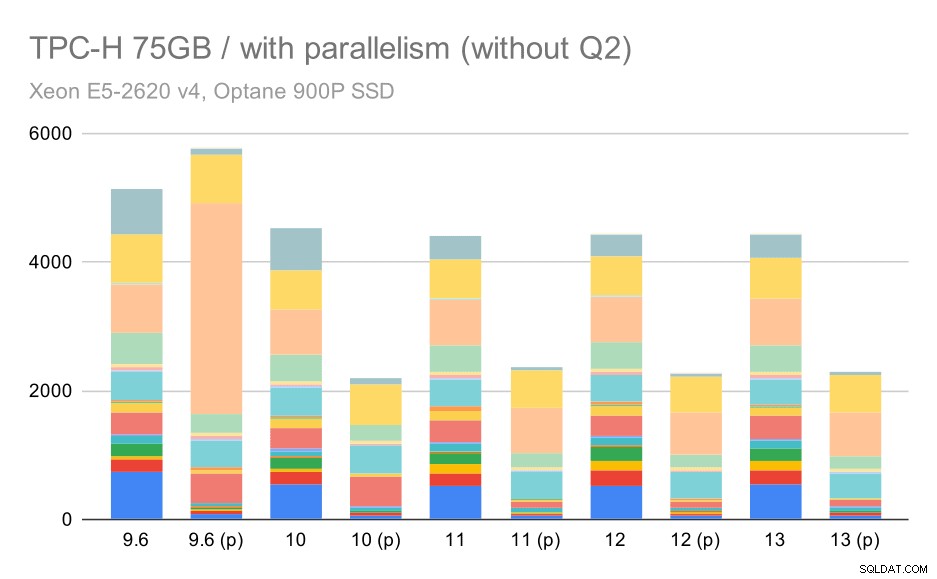
TPC-H-forespørgsler på stort datasæt (75 GB) – parallelitet aktiveret, uden problematisk 2. kvartal
Selv her kan du få øje på nogle dårlige valg af parallelle plan – for eksempel er den parallelle plan for Q9 værre indtil 11, hvor den bliver hurtigere – sandsynligvis takket være 11 understøttende yderligere parallelle eksekvereknuder. På den anden side bliver nogle parallelle forespørgsler (Q18, Q20) langsommere på 11, så det er ikke kun regnbuer og enhjørninger.
Oversigt og fremtid
Jeg synes, at disse resultater godt demonstrerer de optimeringer, der er implementeret siden PostgreSQL 8.3. Testene med parallelitet deaktiveret illustrerer forbedringer i effektivitet (dvs. at gøre mere med den samme mængde ressourcer) – dataindlæsningerne blev ~30 % hurtigere, og forespørgsler blev ~2x hurtigere. Det er rigtigt, at jeg er stødt på nogle problemer med ineffektive forespørgselsplaner, men det er en iboende risiko, når man gør forespørgselsplanlæggeren smartere. Vi arbejder løbende på at gøre resultaterne mere pålidelige, og jeg er sikker på, at jeg kunne afbøde de fleste af disse problemer ved at justere konfigurationen lidt.
Resultaterne med parallelitet aktiveret viser, at vi kan udnytte ekstra ressourcer effektivt (især CPU-kerner). Dataindlæsningerne ser ikke ud til at have særlig gavn af dette – i hvert fald ikke i dette benchmark, men indvirkningen på udførelse af forespørgsler er betydelig, hvilket resulterer i ~2x fremskyndelse (selvom forskellige forespørgsler naturligvis påvirkes forskelligt).
Der er mange muligheder for at forbedre dette i fremtidige PostgreSQL-versioner. For eksempel er der en patch-serie, der implementerer parallelitet til COPY, hvilket fremskynder dataindlæsningerne. Der er forskellige programrettelser, der forbedrer udførelsen af analytiske forespørgsler – fra små lokaliserede optimeringer til store projekter som søjleopbevaring og udførelse, samlet push-down osv. Der kan også vindes meget ved at bruge deklarativ partitionering – en funktion, jeg for det meste ignorerede, mens jeg arbejdede med dette benchmark, simpelthen fordi det ville øge omfanget alt for meget. Og jeg er sikker på, at der er mange andre muligheder, som jeg ikke engang kan forestille mig, men klogere mennesker i PostgreSQL-fællesskabet arbejder allerede på dem.
Bilag:PostgreSQL-konfiguration
Parallelisme deaktiveret
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB
Parallelisme aktiveret
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB