I min tidligere blog diskuterede vi forskellige måder at vælge eller scanne data fra en enkelt tabel på. Men i praksis er det ikke nok at hente data fra en enkelt tabel. Det kræver at vælge data fra flere tabeller og derefter korrelere mellem dem. Korrelation af disse data mellem tabeller kaldes sammenføjning af tabeller, og det kan gøres på forskellige måder. Da sammenføjning af tabeller kræver inputdata (f.eks. fra tabelscanningen), kan det aldrig være en bladknude i den genererede plan.
F.eks. overvej et simpelt forespørgselseksempel som SELECT * FRA TBL1, TBL2 hvor TBL1.ID> TBL2.ID; og antag, at den genererede plan er som nedenfor:
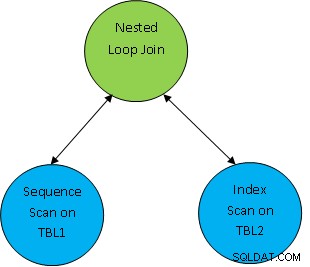
Så her bliver de første begge tabeller scannet, og derefter slås de sammen som pr. korrelationsbetingelsen som TBL.ID> TBL2.ID
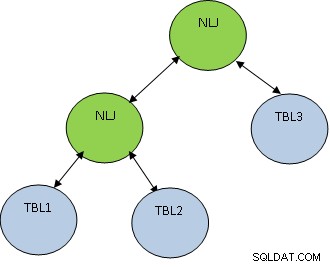
Ud over joinmetoden er joinrækkefølgen også meget vigtig. Overvej nedenstående eksempel:
VÆLG * FRA TBL1, TBL2, TBL3 HVOR TBL1.ID=TBL2.ID OG TBL2.ID=TBL3.ID;
Tænk på, at TBL1, TBL2 OG TBL3 har henholdsvis 10, 100 og 1000 poster.
Betingelsen TBL1.ID=TBL2.ID returnerer kun 5 poster, hvorimod TBL2.ID=TBL3.ID returnerer 100 poster, så er det bedre at forbinde TBL1 og TBL2 først, så et mindre antal poster får sluttet sig til TBL3. Planen vil være som vist nedenfor:
PostgreSQL understøtter nedenstående slags joins:
- Indlejret Loop Join
- Hash-tilmelding
- Flet tilmelding
Hver af disse Join-metoder er lige nyttige afhængigt af forespørgslen og andre parametre, f.eks. forespørgsel, tabeldata, join-klausul, selektivitet, hukommelse osv. Disse join-metoder er implementeret af de fleste relationsdatabaser.
Lad os oprette en forudindstillet tabel og udfylde nogle data, som vil blive brugt hyppigt til bedre at forklare disse scanningsmetoder.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZE I alle vores efterfølgende eksempler betragter vi standardkonfigurationsparameteren, medmindre andet er specifikt angivet.
Indlejret Loop Join
Nested Loop Join (NLJ) er den enkleste joinalgoritme, hvor hver post af ydre relation matches med hver post af indre relation. Sammenføjningen mellem relation A og B med betingelse A.ID Nested Loop Join (NLJ) er den mest almindelige joinforbindelsesmetode, og den kan bruges næsten på ethvert datasæt med enhver type join-klausul. Da denne algoritme scanner alle tupler af indre og ydre relationer, anses det for at være den mest omkostningskrævende joinoperation. I henhold til ovenstående tabel og data vil følgende forespørgsel resultere i en Nested Loop Join som vist nedenfor: Da join-klausulen er "<", er den eneste mulige join-metode her Nested Loop Join. Bemærk her en ny slags node som Materialize; denne node fungerer som mellemliggende resultatcache, dvs. i stedet for at hente alle tuples af en relation flere gange, gemmes det første gang hentede resultat i hukommelsen og ved næste anmodning om at få tuple serveres fra hukommelsen i stedet for at hente fra relationssiderne igen . Hvis alle tupler ikke kan passes ind i hukommelsen, går spild-over tupler til en midlertidig fil. Det er for det meste nyttigt i tilfælde af Nested Loop Join og til en vis grad i tilfælde af Merge Join, da de er afhængige af genscanning af indre relation. Materialize Node er ikke kun begrænset til cacheresultat af relation, men den kan cache resultater af enhver node nedenfor i plantræet. TIP:Hvis join-klausulen er "=", og indlejret loop-join er valgt mellem en relation, så er det virkelig vigtigt at undersøge, om mere effektiv join-metode såsom hash eller merge join kan vælges ved at tuning-konfiguration (f.eks. work_mem, men ikke begrænset til ) eller ved at tilføje et indeks osv. Nogle af forespørgslerne har muligvis ikke join-klausul, i så fald er det eneste valg at deltage i Nested Loop Join. For eksempel. overvej nedenstående forespørgsler i henhold til de forudindstillede data: Forbindelsen i ovenstående eksempel er kun et kartesisk produkt af begge tabeller. Denne algoritme fungerer i to faser: Forbindelsen mellem relation A og B med betingelsen A.ID =B.ID kan repræsenteres som nedenfor: I henhold til ovenstående foruddefinerede tabel og data, vil følgende forespørgsel resultere i en Hash Join som vist nedenfor: Her er hashtabellen oprettet på tabellen blogtable2, fordi det er den mindre tabel, så den minimale hukommelse, der kræves til hashtabellen og hele hashtabellen, kan passe i hukommelsen. Merge Join er en algoritme, hvor hver post af ydre relation matches med hver post af indre relation, indtil der er mulighed for join-klausulmatching. Denne join-algoritme bruges kun, hvis begge relationer er sorteret og join-klausuloperatoren er "=". Sammenføjningen mellem relation A og B med betingelsen A.ID =B.ID kan repræsenteres som nedenfor: Eksemplet forespørgsel, der resulterede i en Hash Join, som vist ovenfor, kan resultere i en Merge Join, hvis indekset bliver oprettet på begge tabeller. Dette skyldes, at tabeldataene kan hentes i sorteret rækkefølge på grund af indekset, som er et af hovedkriterierne for Merge Join-metoden: Så, som vi ser, bruger begge tabeller indeksscanning i stedet for sekventiel scanning, på grund af hvilken begge tabeller vil udsende sorterede poster. PostgreSQL understøtter forskellige planlæggerrelaterede konfigurationer, som kan bruges til at antyde, at forespørgselsoptimeringsværktøjet ikke vælger en bestemt slags joinmetoder. Hvis joinmetoden valgt af optimizeren ikke er optimal, så kan disse konfigurationsparametre slås fra for at tvinge forespørgselsoptimizeren til at vælge en anden slags joinmetoder. Alle disse konfigurationsparametre er "til" som standard. Nedenfor er planlæggerens konfigurationsparametre, der er specifikke for join-metoder. Der er mange planrelaterede konfigurationsparametre, der bruges til forskellige formål. I denne blog er det begrænset til kun at deltage i metoder. Disse parametre kan ændres fra en bestemt session. Så hvis vi ønsker at eksperimentere med planen fra en bestemt session, så kan disse konfigurationsparametre manipuleres, og andre sessioner vil stadig fortsætte med at fungere, som de er. Overvej nu ovenstående eksempler på flette-join og hash-join. Uden et indeks valgte forespørgselsoptimereren en Hash Join til nedenstående forespørgsel som vist nedenfor, men efter brug af konfigurationen skifter den til Merge join selv uden indeks: Initialt er Hash Join valgt, fordi data fra tabeller ikke er sorteret. For at vælge flettesammenføjningsplanen skal den først sortere alle poster hentet fra begge tabeller og derefter anvende flettesammenføjningen. Så omkostningerne ved sortering vil være yderligere, og dermed vil de samlede omkostninger stige. Så muligvis, i dette tilfælde, er de samlede (inklusive øgede) omkostninger mere end de samlede omkostninger ved Hash Join, så Hash Join er valgt. Når konfigurationsparameteren enable_hashjoin er ændret til "off", betyder det, at forespørgselsoptimering direkte tildeler en omkostning for hash join som deaktiveringsomkostning (=1.0e10, dvs. 10000000000.00). Omkostningerne ved enhver mulig tilslutning vil være mindre end dette. Så det samme forespørgselsresultat i Merge Join efter enable_hashjoin blev ændret til "off", da selv inklusive sorteringsomkostningerne er de samlede omkostninger ved Merge Join mindre end deaktiveringsomkostninger. Overvej nu nedenstående eksempel: Som vi kan se ovenfor, selvom den indlejrede sløjfe-sammenføjning-relaterede konfigurationsparameter er ændret til "fra", vælger den stadig indlejret sløjfe-sammenføjning, da der ikke er nogen alternativ mulighed for nogen anden form for sammenføjningsmetode for at få valgte. I simplere termer, da Nested Loop Join er den eneste mulige joinforbindelse, så vil det, uanset prisen, altid være vinderen (det samme som jeg plejede at være vinderen i 100m løb, hvis jeg løb alene...:-)). Læg også mærke til forskellen i omkostningerne i den første og anden plan. Den første plan viser de faktiske omkostninger for Nested Loop Join, men den anden viser deaktiveringsomkostningerne for samme. Alle former for PostgreSQL join-metoder er nyttige og bliver udvalgt baseret på arten af forespørgslen, data, join-klausul osv. Hvis forespørgslen ikke fungerer som forventet, dvs. join-metoder er ikke valgt som forventet, kan brugeren lege med forskellige tilgængelige plankonfigurationsparametre og se, om der mangler noget.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s) postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows) Hash Join
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Flet tilmelding
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break; postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows) Konfiguration
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows) postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Konklusion