"Waitstats hjælper os med at identificere præstationsrelaterede tællere. Men venteoplysninger i sig selv er ikke nok til præcist at diagnosticere ydeevneproblemer. Køkomponenten i vores metodik kommer fra Performance Monitor-tællere, som giver et overblik over systemets ydeevne fra et ressourcesynspunkt."Tom Davidson, Åbning af Microsofts Performance-Tuning Toolbox
SQL Server Pro Magazine, december 2003
Waits and Queues er blevet brugt som en metode til justering af SQL Server-ydelse, siden Tom Davidson publicerede ovenstående artikel samt det velkendte SQL Server 2005 Waits and Queues whitepaper i 2006. Når det anvendes i kombination med ressourcemålinger, kan ventetider være værdifulde for vurdering af visse præstationskarakteristika ved arbejdsbyrden og hjælp til at styre tuningindsatsen. Waits-data vises af mange SQL Server-ydelsesovervågningsløsninger, og jeg har været fortaler for tuning ved hjælp af denne metode siden begyndelsen. Fremgangsmåden var indflydelsesrig i designet af SQL Sentry-ydelsesdashboardet, som præsenterer ventetider flankeret af køer (nøgleressourcemålinger) for at levere et omfattende overblik over serverens ydeevne.
Nogle ser dog ud til at have overset Davidsons pointe med hensyn til vigtigheden af ressourcer og stoler næsten udelukkende på ventetider for at præsentere et billede af forespørgselsydeevne og systemsundhed. Ventestatistikker kommer direkte fra SQL Server-motoren og er nemme at forbruge og kategorisere. Ventende forespørgsler betyder ventende applikationer og brugere, og ingen kan lide at vente! Det er lettere at evangelisere tuning med ventetider som den enestående løsning til at gøre forespørgsler og applikationer hurtigere, end det er at fortælle hele historien, som er mere involveret.
Desværre kan en ventefokuseret tilgang til udelukkelse af ressourceanalyse vildlede og i værste fald lade dig flyve blind. SentryOne-teammedlemmerne Kevin Kline og Steve Wright har tidligere været inde på dette her og her. I dette indlæg vil jeg tage et dybere dyk ned i nogle nyere undersøgelser muliggjort af Query Store, der har kastet nyt lys over, hvor mangelfuld vente-eksklusiv tuning virkelig kan være.
De mest populære forespørgsler, der ikke var
For nylig kontaktede en SentryOne-kunde mig om præstationsbekymringer med deres SentryOne-database. Der er en enkelt SQL Server-database i hjertet af hvert SentryOne-overvågningsmiljø, og denne kunde overvågede omkring 600 servere med vores software. I den skala er det ikke usædvanligt at se lejlighedsvise problemer med forespørgselsydeevne og foretage en lille justering, og nogle angiveligt nye forespørgsler i arbejdsbyrden var kilden til deres bekymring.
Jeg deltog i en skærmdelingssession for at se, og kunden præsenterede mig først for data fra et andet system, der også overvågede SentryOne-databasen. Systemet brugte en ventemetode på forespørgselsniveau og viste to lagrede procedurer som ansvarlige for cirka halvdelen af ventetiden på SQL Sentry-databaseserveren. Dette var usædvanligt, fordi disse to procedurer altid kører meget hurtigt og aldrig har været tegn på et reelt ydeevneproblem i vores database. Forvirret skiftede jeg over til SQL Sentry for at se, hvad det ville vise os, og blev overrasket over at se, at over det samme interval var #1 proceduren i det andet system #6, #7 og #8 med hensyn til total varighed, CPU og logisk lyder henholdsvis:
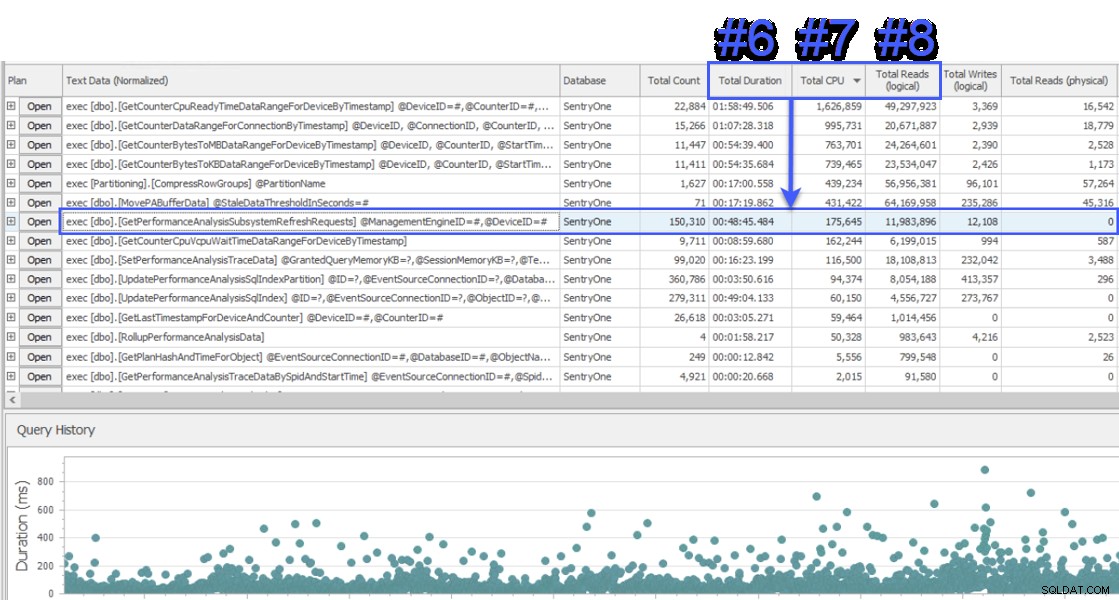 SQL Sentrys "Top SQL"-visning
SQL Sentrys "Top SQL"-visning
Fra et ressourceforbrugssynspunkt betød dette, at forespørgslerne over det repræsenterede 75 % af den samlede varighed, 87 % af den samlede CPU og 88 % af logiske læsninger. Desuden var #2 proceduren i det andet system ikke engang i top 30 i SQL Sentry, på nogen måde! Disse to forespørgsler var langt fra top 2, og de forespørgsler, der stod for det meste af de faktiske forbruget på systemet blev stærkt underrepræsenteret.
Jeg havde altid antaget, at der var en stærkere sammenhæng mellem de øverste tjenere og de bedste ressourceforbrugere, men jeg havde aldrig udført en direkte sammenligning på forespørgselsniveau som denne, så disse resultater var mildest talt overraskende. Min interesse vakte, jeg besluttede at undersøge, om denne situation var typisk eller unormal.
Query Store 2017 til undsætning
I SQL Server 2017 og nyere fanger Query Store ventetider på forespørgselsniveau ud over forespørgselsressourceforbruget. Erin Stellato lavede et godt indlæg om Query Store waits her. Det er lavere overhead og mere præcist end forespørgselsventer DMV'er hvert sekund i håb om at fange forespørgsler under flyvningen, standardtilgangen, der bruges af andre værktøjer, inklusive det førnævnte.
SQL Sentry har altid fanget ventetider, men på SQL Server-instansniveau, på grund af disse bekymringer om overhead og nøjagtighed. Detaljerede ventetider på forespørgsler er tilgængelige på forespørgsel via integreret Plan Explorer, og vi evaluerer at udvide ventetiden på forekomstniveau med data på forespørgselsniveau fra Query Store, når de er tilgængelige.
Til denne bestræbelse fik jeg hjælp fra SentryOne Product Advisory Council, en gruppe SentryOne-kunder, partnere og venner i branchen, som deltager i en privat Slack-kanal. Jeg delte dette script for at dumpe de foregående 8 timers data fra Query Store og modtog resultater tilbage for 11 produktionsservere på tværs af flere vertikaler, herunder finansielle tjenester, spiludgivelse, fitnesssporing og forsikring.
Ventekategorier i Query Store er dokumenteret her. Alle kategorier blev inkluderet i analysen bortset fra disse, som blev fjernet af de nævnte grunde:
- Parallelisme - Det kan voldsomt oppuste en forespørgsels ventetid langt ud over dens faktiske varighed, da flere tråde kan afbryde de tilknyttede ventetider, hvilket forvirrer korrelationen med varighed og andre målinger. Yderligere, selvom CXPACKET/CXCONSUMER-opdelingen er nyttig, betyder CXPACKET stadig kun, at du har parallelitet og ikke nødvendigvis er problematisk eller handlingsvenlig.
- CPU – Signalventetid kan være nyttigt til at konstatere CPU-flaskehalse via korrelation med ressourceventer, men Query Store inkluderer i øjeblikket kun SOS_SCHEDULER_YIELD i denne kategori, hvilket ikke er en ventetid i traditionel forstand som beskrevet her. Det egner sig ikke til nem sammenligning eller korrelation, især når SQL Server er på en VM, der lever på en overtegnet vært. For eksempel var Query Store CPU-venter på én server 227 % af den samlede CPU-tid på tværs af alle forespørgsler uden nogen parallelitet, hvilket ikke burde være muligt.
- Bruger Vent ogtomgang – Disse kategorier består udelukkende af timer- og køventer og blev udelukket af samme grund, som man altid bør udelukke disse typer – de er ufarlige og skaber kun støj.
Som en sidebemærkning talte jeg for nylig med faderen til Query Store, Conor Cunningham, om sandsynligheden for fremtidige ændringer af Query Store-ventetyper og -kategorier, og han indikerede, at det bestemt var muligt... så vi bliver nødt til at holde øje med det.
Analyseresultater TL;DR
Efter omfattende analyser har jeg bekræftet, at resultaterne observeret på kundesystemet ikke er unormale, men temmelig almindelige. Dette betyder, at hvis du er afhængig af et vente-fokuseret værktøj til at overvåge og justere dine arbejdsmængder, er der stor sandsynlighed for, at du fokuserer på de forkerte forespørgsler og savner dem, der er ansvarlige for de fleste af forespørgselsvarigheden og ressourceforbrug på et system. Da CPU- og IO-forbrug oversættes direkte til serverhardware og skyudgifter, er dette væsentligt.
De fleste forespørgsler venter ikke
En interessant og vigtig konstatering, som jeg vil dække først, er, at de fleste forespørgsler overhovedet ikke genererer ventetider. Ud af 56.438 samlede forespørgsler på tværs af alle servere havde kun 9.781 (17%) nogen ventetid, og kun 8.092 (14%) havde ventetid fra signifikante typer. Hvis du bruger ventetider alene til at bestemme, hvilke forespørgsler der skal optimeres, vil du gå glip af de fleste forespørgsler i arbejdsbyrden.
Korrelerende ventetider og ressourcer
Jeg analyserede, hvordan ventetider relaterer til ressourceforbrug ved at rangere alle forespørgsler på hvert system efter ventetider og ressourcer og bruge rækkerne til at beregne en Spearmans korrelation. Det, vi i sidste ende forsøger at afgøre, er, om toptjenerne har en tendens til at være topforbrugerne. Det viser sig, at de ikke gør det.
Tabel 1 viser de farveskalerede korrelationskoefficienter for gennemsnitlig ventetid på forespørgsel tid til andre mål – en værdi på 1,00 (mørkeblå) repræsenterer data, der er perfekt korreleret. Som du kan se, er korrelationen med ventetider og andre mål på tværs af de fleste af serverne ikke stærk, og for én server er der en negativ sammenhæng med de fleste målinger.
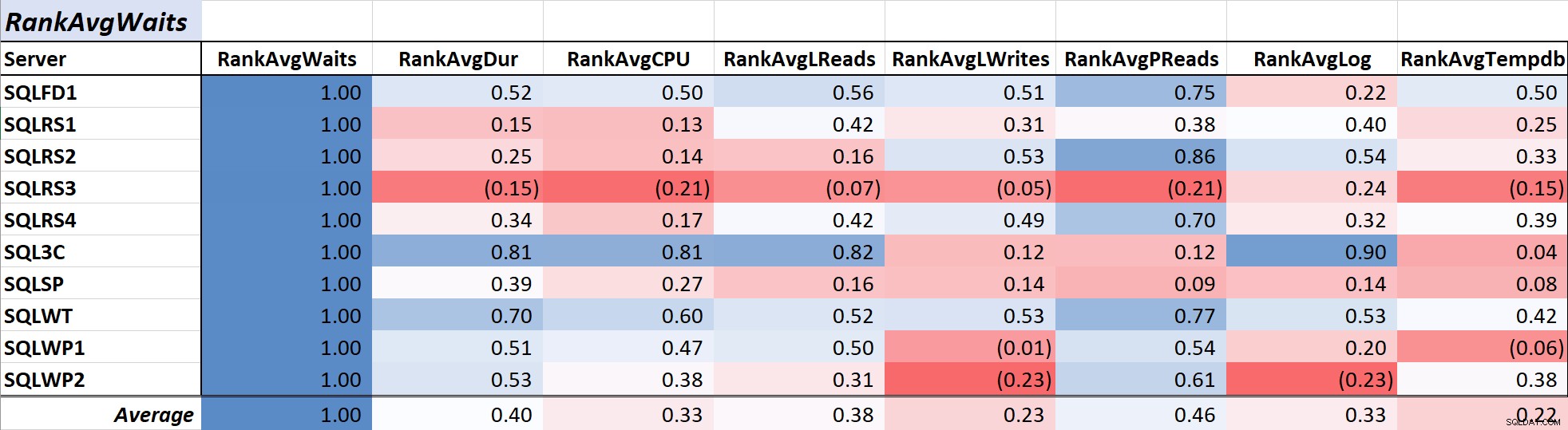 Tabel 1:Korrelation med gennemsnitlig ventetid for forespørgsler (ms)
Tabel 1:Korrelation med gennemsnitlig ventetid for forespørgsler (ms)
Forespørgselsvarighed er ofte et primært problem for DBA'er og udviklere, da det oversættes direkte til brugeroplevelsen og Tabel 2 viser sammenhængen mellem gennemsnitlig forespørgselsvarighed og de øvrige foranstaltninger. Korrelationen med varighed og de to primære ressourcemål, CPU og logiske læsninger, er ret stærk ved henholdsvis 0,97 og 0,75.
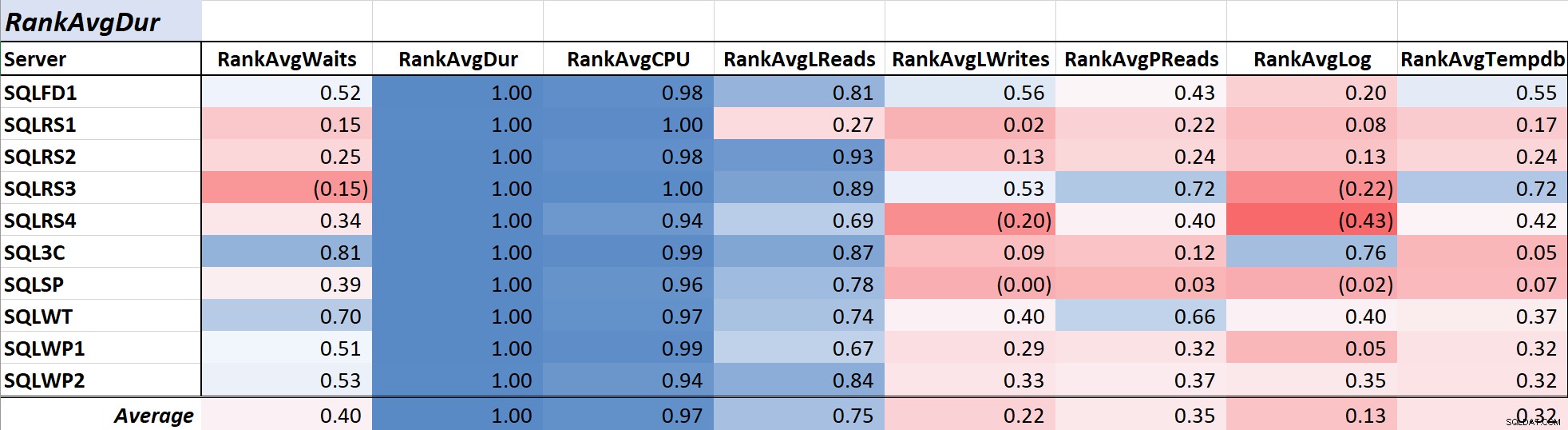 Tabel 2:Korrelation med gennemsnitlig forespørgselsvarighed (ms)
Tabel 2:Korrelation med gennemsnitlig forespørgselsvarighed (ms)
Da logiske læsninger altid bruger CPU, og ligesom varighed, CPU måles i millisekunder, er dette forhold ikke overraskende. Resultaterne er i overensstemmelse med ideen om, at hvis du vil have dine databaseapplikationer til at køre så hurtigt som muligt, vil fokus på at reducere forespørgsels-CPU og logiske læsninger være mere effektivt til at reducere varigheden end at bruge ventetider alene. Heldigvis er det normalt et mere ligetil forslag at gøre det via bedre forespørgselsdesign, indeksering osv. end at reducere forespørgselsventetiden direkte. Kollega Aaron Bertrand præsenterer effektivt nogle af forbeholdene, når man tuner med ventetider her.
% af den samlede ventetid
Dernæst så jeg på, om de forespørgsler med den højeste ventetid har en tendens til at stå for det mest ressourceforbrug. Vi ønsker at afgøre, om det, vi så på kundesystemet, er atypisk, hvor de øverste 2 ventende forespørgsler repræsenterede en relativt lille procentdel af det samlede ressourceforbrug.
Diagram 1 nedenfor viser % af den samlede CPU og logiske læsninger for hver server, der står for forespørgslerne, der repræsenterer 75 % af den samlede ventetid. Kun én server havde en ressource på mere end 75 % – læser på SQLRS3. For resten brugte de forespørgsler, der stod for 75 % af ventetiden, mindre end 75 % af ressourcerne – ofte langt mindre. Dette afspejler, hvad vi så på kundesystemet og stemmer overens med korrelationsanalysen.
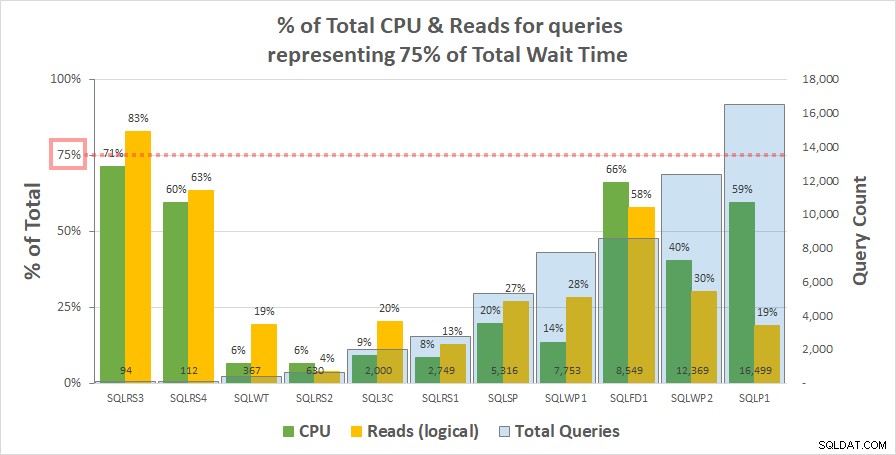 diagram 1
diagram 1
Bemærk, at der ser ud til at være en sammenhæng med det samlede antal forespørgsler i arbejdsmængden. Dette er repræsenteret af den lyseblå kolonneserie på den sekundære y-akse, og diagrammet er sorteret stigende efter denne serie. De to servere med de højeste ressourcemål på 75 % af ventetiden havde også de færreste forespørgsler (SQLRS3 og SQLRS4). Jo mindre arbejdsbyrden er indstillet, jo større er den potentielle indflydelse af et lille antal forespørgsler, og ganske rigtigt, på begge servere tegnede kun to forespørgsler sig for det meste af ventetiden og ressourcerne. En måde at se dette på er, at ventetider hjælper mest med at identificere dine tungeste forespørgsler, når du mindst har brug for det.
Ventetid og forespørgselsvarighed
Til sidst vurderede jeg % af den samlede ventetid til den samlede forespørgselsvarighed på hvert system. Tabel 3 har kolonner for:
- Samlet forespørgselsvarighed i ms
- Samlet ventetid ms – rå
- Samlet ventetid ms – uden parallelisme, inaktiv og brugerventer (Rev1)
- Samlet ventetid ms – uden Parallelisme, Inaktiv, Brugerventer og CPU (Rev2)
- Procentdelen af varigheden for de 3 ventetidskolonner med databjælker
- Samlet antal unikke forespørgsler med databjælker
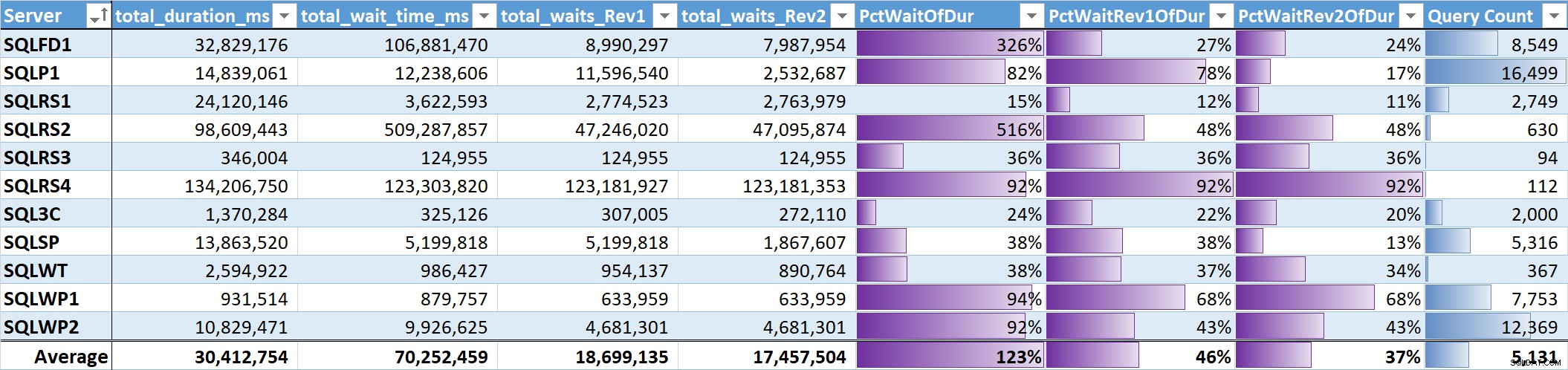 Tabel 3
Tabel 3
Det uvægtede gennemsnit for de meningsfulde ventetider (Rev2) på tværs af alle systemer er 37 % af den samlede forespørgselsvarighed. På fem af systemerne var den under 25 %, og på kun to systemer var den over 50 %. På systemet med 92 % ventetid (SQLRS4), en med færrest forespørgsler, tegnede to forespørgsler sig for 99 % af ventetiden, 97 % af varigheden, 84 % af CPU’en og 86 % af læsningerne.
Selvom ventetid kan repræsentere en betydelig del af forespørgselskørselstid på visse systemer, og det virker intuitivt, at hvis du reducerer ventetiden, vil forespørgselsvarigheden også falde, har vi set, at ventetid og varighed er svagt korreleret. Det er usandsynligt, at det er så enkelt, og min egen erfaring bekræfter dette. Der er brug for mere forskning her.
Omfattende justering med Plan Explorer og SQL Sentry
Som denne fremragende SQLskills whitepaper ofte antyder, er roden til høje ventetider ofte uoptimerede forespørgsler og indekser. Den gratis SentryOne Plan Explorer er specialbygget til at reducere ressourceforbruget via effektiv forespørgselsindstilling ved hjælp af dets Index Analysis-modul og mange andre innovative funktioner. SQL Sentry integrerer Plan Explorer direkte i Top SQL-, Blocking- og Deadlocks-modulerne, så du automatisk kan fange og tune problematiske forespørgsler ét sted. Du kan nemt vælge en række interesser på SQL Sentry-dashboardets historiske vente-, CPU- eller IO-diagrammer og springe til Top SQL-visningen for at finde de mest ressourcekrævende forespørgsler i det tidsrum. Så med et enkelt klik kan du åbne en forespørgsel i Plan Explorer og få detaljerede ventetider på forespørgselsniveau og ressourcer efter behov, når det er nødvendigt. Jeg tror ikke, der er en bedre udformning af den fulde Waits and Queue-indstillingsmetode end dette.
 SQL Sentry Dashboard “Waits”-diagram
SQL Sentry Dashboard “Waits”-diagram
 Den gratis SentryOne Plan Explorer, der viser ventetider over tid sammen med driftsniveau omkostninger og ressourcer
Den gratis SentryOne Plan Explorer, der viser ventetider over tid sammen med driftsniveau omkostninger og ressourcer
Konklusion
Tuning med ventetider og køer er lige så relevant for SQL Server-ydeevne i dag, som det var tilbage i 2006. Men at fokusere på ventetider til udelukkelse af ressourcer er en farlig forretning, da det tydeligt fremgår af dataene, at det vil føre til generelt uoptimeret og omkostningsineffektive systemer. Når det kommer til hardwareressourcer og cloud-forbrug, betaler du i sidste ende for computer- og IO-ressourcer, ikke ventetid, så det er hensigtsmæssigt at optimere direkte til forbrug. Det er min erfaring, at efterhånden som ressourceforbruget og relaterede påstande sænkes, vil der naturligvis følge en reduceret ventetid.
Anerkendelse
Jeg vil gerne takke Fred Frost, Lead Data Scientist hos SentryOne, for hans værdifulde input og kritiske gennemgang af denne analyse.