[ Del 1 | Del 2 | Del 3 ]
I del 1 af denne serie prøvede jeg et par måder at komprimere et 1TB bord på. Mens jeg fik anstændige resultater i mit første forsøg, ville jeg se, om jeg kunne forbedre ydeevnen i del 2. Der skitserede jeg et par af de ting, jeg troede kunne være præstationsproblemer, og lagde ud, hvordan jeg bedre kunne partitionere destinationstabellen for optimal kolonnelagerkomprimering. Jeg har allerede:
- opdelte tabellen i 8 partitioner (én pr. kerne);
- sæt hver partitions datafil i sin egen filgruppe; og,
- indstil arkivkomprimering på alle undtagen den "aktive" partition.
Jeg mangler stadig at gøre det, så hver planlægger udelukkende skriver til sin egen partition.
Først skal jeg foretage ændringer i den batch-tabel, jeg oprettede. Jeg har brug for en kolonne til at gemme antallet af tilføjede rækker pr. batch (en slags selvrevisionskontrol) og start-/sluttider for at måle fremskridt.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Dernæst skal jeg oprette en tabel for at give affinitet – vi vil aldrig have mere end én proces, der kører på en planlægger, selvom det betyder, at man mister noget tid til at prøve logik igen. Så vi har brug for en tabel, der holder styr på enhver session på en specifik skemalægger og forhindrer stabling:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Ideen er, at jeg vil have otte forekomster af en applikation (SQLQueryStress), der hver vil køre på en dedikeret planlægger, der kun håndterer de data, der er bestemt til en specifik partition/filgruppe/datafil, ~100 millioner rækker ad gangen (klik for at forstørre) :
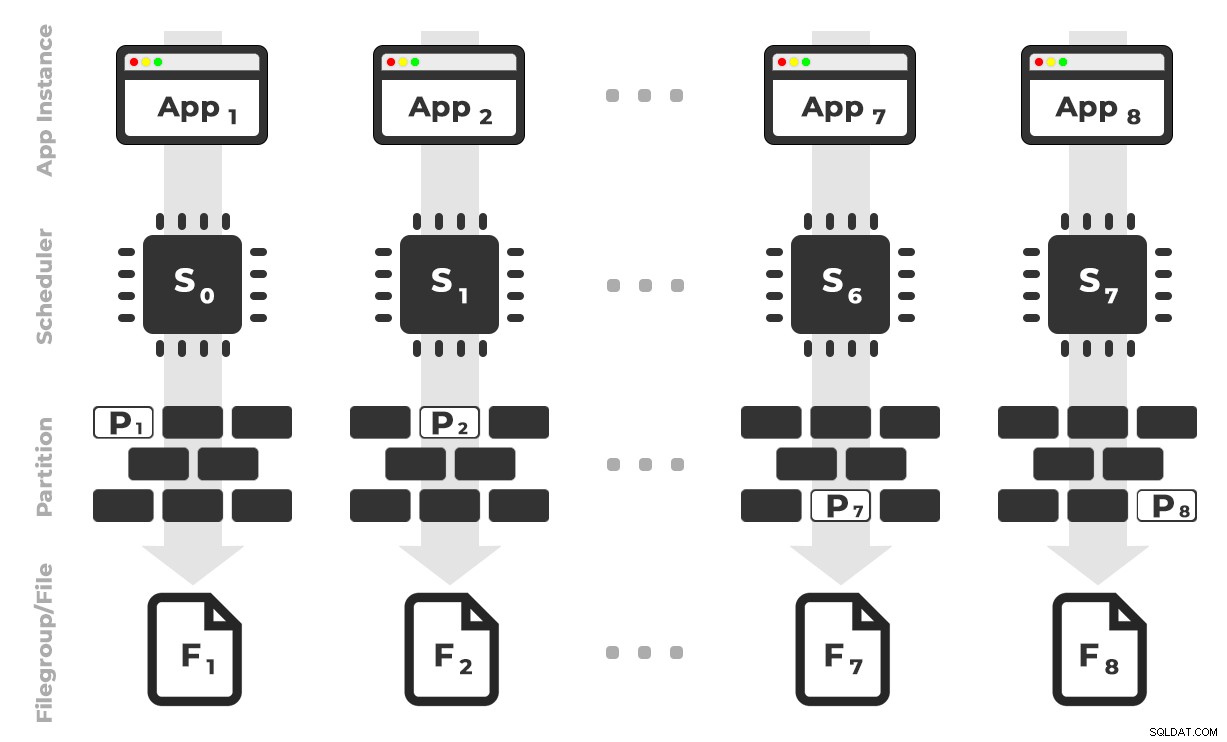 App 1 får skemalægger 0 og skriver til partition 1 på filgruppe 1, og så videre …
App 1 får skemalægger 0 og skriver til partition 1 på filgruppe 1, og så videre …
Dernæst har vi brug for en lagret procedure, der gør det muligt for hver instans af applikationen at reservere tid på en enkelt skemalægger. Som jeg nævnte i et tidligere indlæg, er dette ikke min oprindelige idé (og jeg ville aldrig have fundet det i den guide, hvis ikke for Joe Obbish). Her er den procedure, jeg oprettede i Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Simpelt, ikke? Start 8 forekomster af SQLQueryStress, og sæt denne batch i hver:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
 Fattig mands parallelitet
Fattig mands parallelitet
Bortset fra, at det ikke er så enkelt, da planlægningsopgave er lidt som en æske chokolade. Det tog mange forsøg at få hver forekomst af appen på den forventede planlægger; Jeg ville inspicere undtagelserne på en given forekomst af appen og ændre PartitionID at matche. Det er derfor, jeg brugte mere end én iteration (men jeg ville stadig kun have én tråd pr. instans). Som et eksempel forventede denne forekomst af appen at være på skemalægger 3, men den fik skemalægger 4:
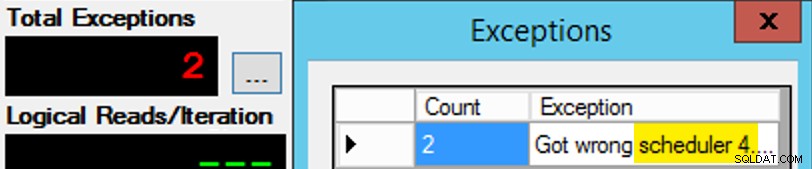 Hvis du først ikke lykkes...
Hvis du først ikke lykkes...
Jeg ændrede 3'erne i forespørgselsvinduet til 4'er og prøvede igen. Hvis jeg var hurtig, var planlægningsopgaven "klæbende" nok til at den ville tage den op og begynde at tude væk. Men jeg var ikke altid hurtig nok, så det var lidt som en muldvarp at komme afsted. Jeg kunne nok have udtænkt en bedre genforsøg/sløjfe-rutine for at gøre arbejdet mindre manuelt her, og forkorte forsinkelsen, så jeg vidste med det samme, om det virkede eller ej, men dette var godt nok til mine behov. Det sørgede også for en utilsigtet forveksling af starttider for hver proces, endnu et råd fra hr. Obbish.
Overvågning
Mens den affiniterede kopi kører, kan jeg få et tip om den aktuelle status med følgende to forespørgsler:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Hvis jeg gjorde alt rigtigt, ville begge forespørgsler returnere 8 rækker og vise stigende logiske læsninger og varighed. Ventetyper vil vende rundt mellem PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , og lejlighedsvis RESERVED_MEMORY_ALLOCATION_EXT. Når en batch var færdig (jeg kunne gennemgå disse ved at fjerne kommentarer til -- AND EndTime IS NULL , vil jeg bekræfte, at RowsAdded = RowsInRange .
Når alle 8 forekomster af SQLQueryStress var gennemført, kunne jeg bare udføre en SELECT INTO <newtable> FROM dbo.BatchQueue for at logge de endelige resultater til senere analyse.
Anden test
Ud over at kopiere dataene til det partitionerede clustered columnstore-indeks, der allerede eksisterede, ved at bruge affinitet, ville jeg også prøve et par andre ting:
- Kopiering af data til den nye tabel uden at forsøge at kontrollere affinitet. Jeg tog affinitetslogikken ud af proceduren og overlod bare hele "håber-du-får-den-rigtige-planlægger"-ting til tilfældighederne. Dette tog længere tid, fordi planlægningsstabling gjorde det forekomme. For eksempel, på dette specifikke tidspunkt kørte skemalægger 3 to processer, mens skemalægger 0 holdt frokostpause:
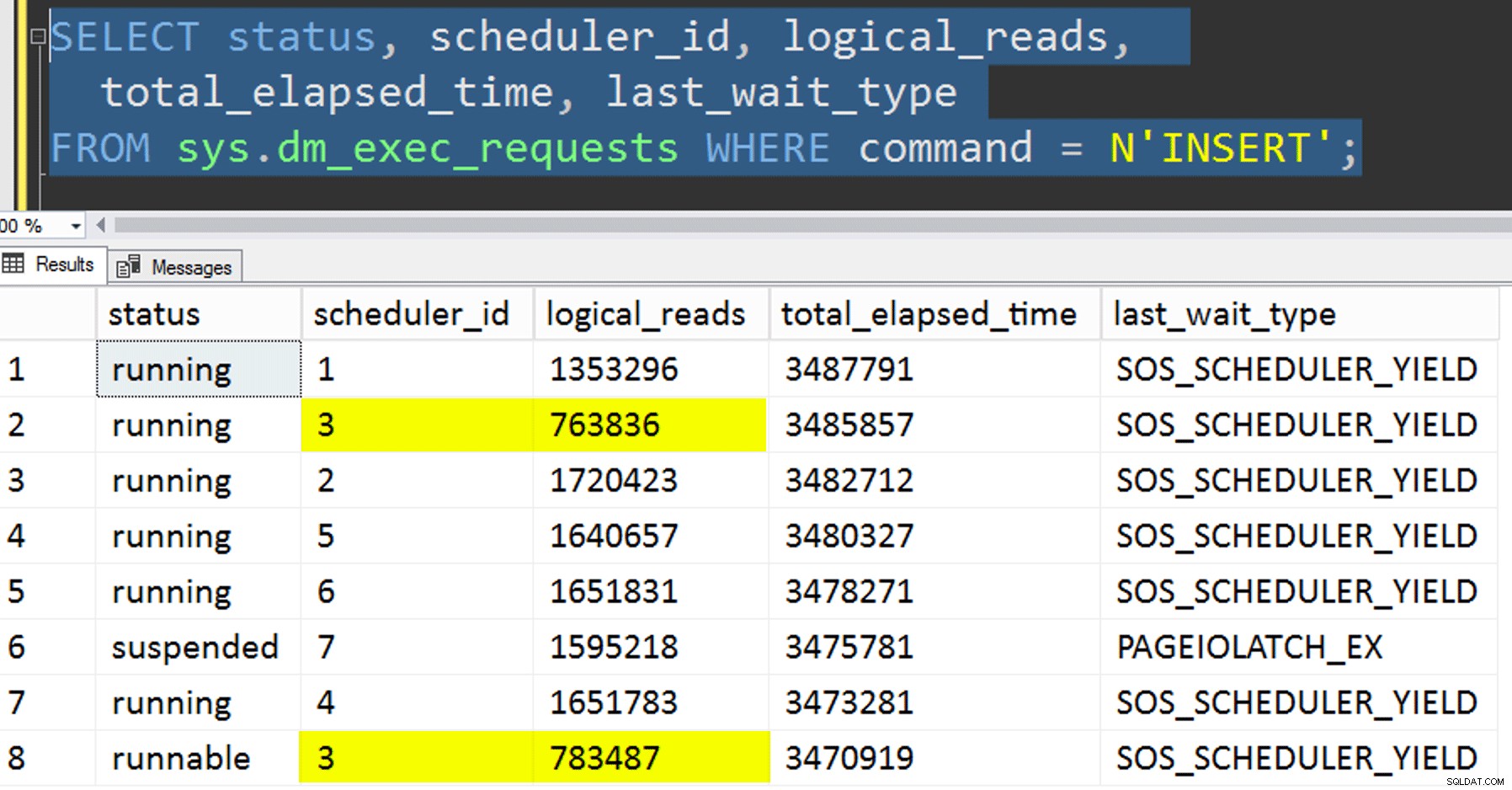 Hvor er du, skemalægger nummer 0?
Hvor er du, skemalægger nummer 0? - Anvender side eller række komprimering (både online/offline) til kilden før den affiniterede kopi (offline), for at se, om komprimering af dataene først kunne fremskynde destinationen. Bemærk, at kopien også kunne laves online, men ligesom Andy Mallons
inttilbigintomstilling, kræver det noget gymnastik. Bemærk, at vi i dette tilfælde ikke kan drage fordel af CPU-affinitet (selvom vi kunne, hvis kildetabellen allerede var partitioneret). Jeg var smart og tog en sikkerhedskopi af den originale kilde og lavede en procedure for at vende databasen tilbage til dens oprindelige tilstand. Meget hurtigere og nemmere end at forsøge at vende tilbage til en bestemt tilstand manuelt.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- Og til sidst skal du først genopbygge det klyngede indeks på partitionsskemaet, og derefter bygge det klyngede kolonnelagerindeks ovenpå. Ulempen ved sidstnævnte er, at du i SQL Server 2017 ikke kan køre dette online... men du vil være i stand til det i 2019.
Her skal vi først droppe PK-begrænsningen; du kan ikke bruge
Meddelelse 1907, niveau 16, tilstand 1DROP_EXISTING, da den oprindelige unikke begrænsning ikke kan håndhæves af det klyngede kolonnelagerindeks, og du kan ikke erstatte et unikt klynget indeks med et ikke-entydigt klynget indeks.
Kan ikke genskabe indeks 'pk_tblOriginal'. Den nye indeksdefinition matcher ikke den begrænsning, der håndhæves af det eksisterende indeks.Alle disse detaljer gør dette til en tre-trins proces, kun det andet trin online. Det første trin testede jeg kun udtrykkeligt
OFFLINE; der kørte på tre minutter, mensONLINEJeg stoppede efter 15 minutter. En af de ting, der måske ikke burde være en datastørrelsesoperation i begge tilfælde, men det lader jeg stå til en anden dag.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Resultater
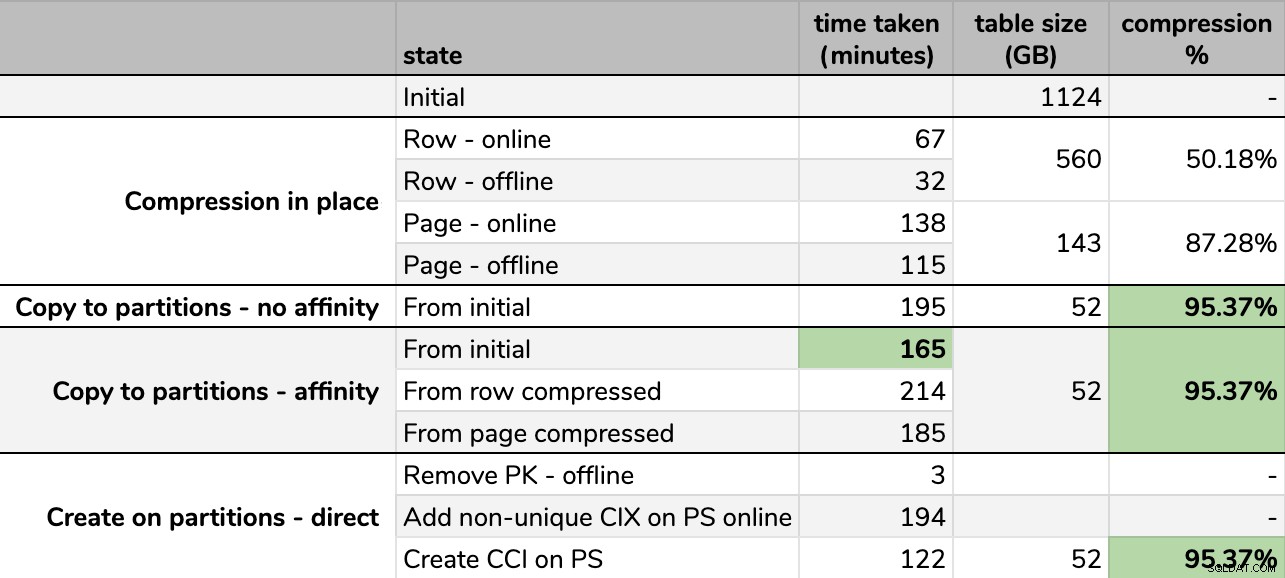
Timings og kompressionshastigheder:
 Nogle muligheder er bedre end andre
Nogle muligheder er bedre end andre
Bemærk, at jeg rundede af til GB, fordi der ville være mindre forskelle i den endelige størrelse efter hvert løb, selv ved at bruge den samme teknik. Timingerne for affinitetsmetoderne var også baseret på gennemsnittet individuel skemalægger/batch runtime, da nogle skemalæggere blev færdige hurtigere end andre.
Det er svært at forestille sig et nøjagtigt billede fra regnearket som vist, fordi nogle opgaver har afhængigheder, så jeg vil forsøge at vise informationen som en tidslinje og vise, hvor meget komprimering du får i forhold til den brugte tid:
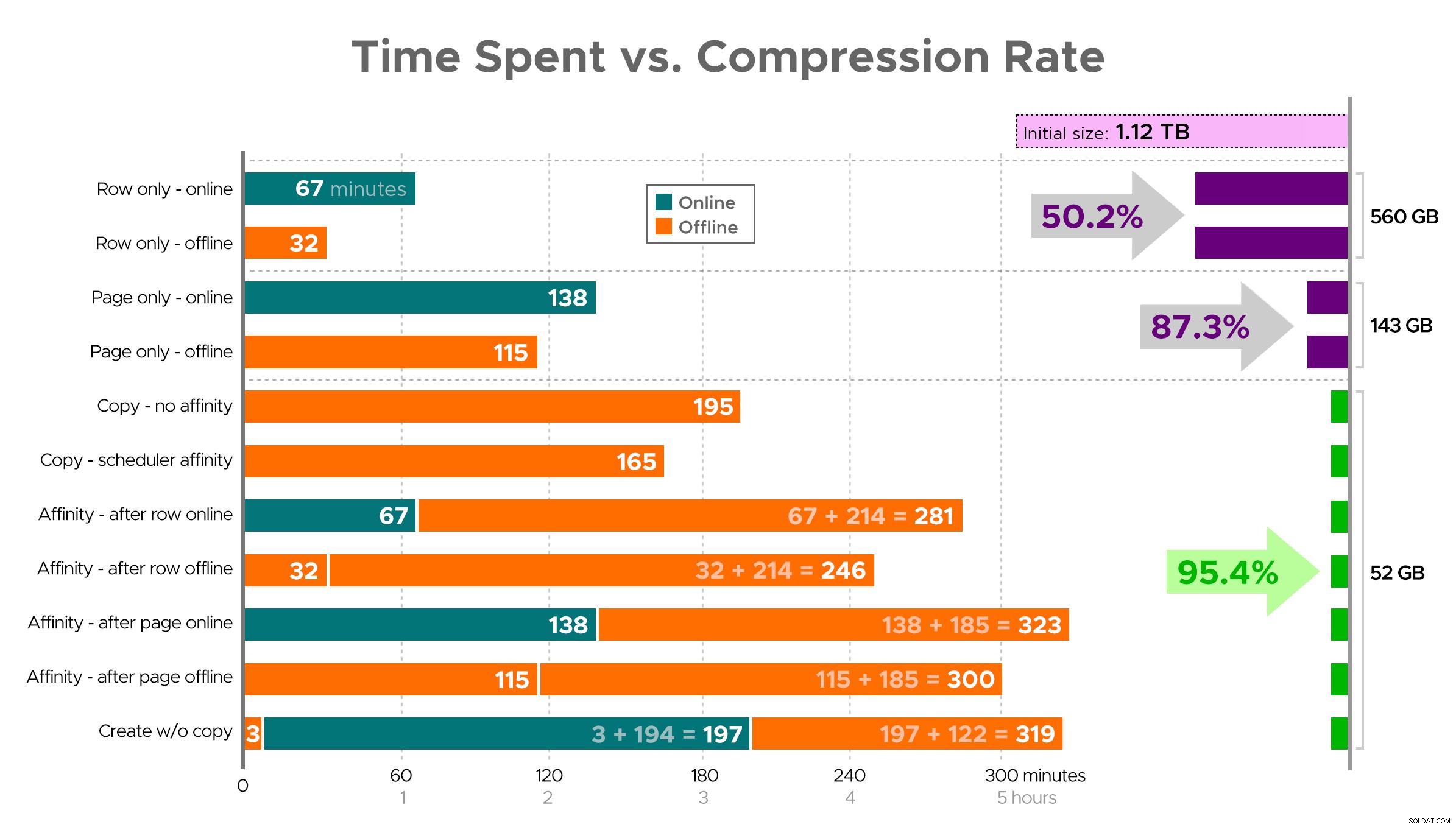 Tidsforbrug (minutter) vs. kompressionshastighed
Tidsforbrug (minutter) vs. kompressionshastighed
Et par observationer fra resultaterne, med det forbehold, at dine data kan komprimere anderledes (og at online operationer kun gælder for dig, hvis du bruger Enterprise Edition):
- Hvis din prioritet er at spare lidt plads så hurtigt som muligt , er dit bedste bud at anvende rækkekompression på plads. Hvis du vil minimere forstyrrelser, så brug online; hvis du vil optimere hastigheden, skal du bruge offline.
- Hvis du vil maksimere komprimeringen uden afbrydelse , kan du nærme dig 90 % lagerreduktion uden nogen afbrydelse overhovedet ved at bruge sidekomprimering online.
- Hvis du vil maksimere komprimering og afbrydelse er okay , kopier dataene til en ny, opdelt version af tabellen med et klynget kolonnelagerindeks, og brug affinitetsprocessen beskrevet ovenfor til at migrere dataene. (Og igen, du kan eliminere denne forstyrrelse, hvis du er en bedre planlægger end mig.)
Den sidste mulighed fungerede bedst for mit scenarie, selvom vi stadig bliver nødt til at sparke dækkene på arbejdsbelastningen (ja, flertal). Bemærk også, at i SQL Server 2019 virker denne teknik muligvis ikke så godt, men du kan bygge klyngede kolonnelagerindekser online der, så det betyder måske ikke så meget.
Nogle af disse tilgange kan være mere eller mindre acceptable for dig, fordi du måske foretrækker "at forblive tilgængelig" frem for "færdiggøre så hurtigt som muligt" eller "minimere diskforbrug" frem for "at forblive tilgængelig" eller bare balancere læseydelse og skriveoverhead .
Hvis du vil have flere detaljer om et eller andet aspekt af dette, så spørg bare. Jeg trimmede noget af fedtet for at balancere detaljer med fordøjelighed, og jeg har før taget fejl af den balance. En afskedstanke er, at jeg er nysgerrig efter, hvor lineært dette er – vi har et andet bord med en lignende struktur, der er over 25 TB, og jeg er spændt på, om vi kan få en lignende effekt der. Indtil da, glad komprimering!
[ Del 1 | Del 2 | Del 3 ]