Tabelværdiparametre har eksisteret siden SQL Server 2008 og giver en nyttig mekanisme til at sende flere rækker af data til SQL Server, samlet som et enkelt parameteriseret kald. Alle rækker er så tilgængelige i en tabelvariabel, som derefter kan bruges i standard T-SQL-kodning, hvilket eliminerer behovet for at skrive specialiseret behandlingslogik for at nedbryde dataene igen. Ifølge deres selve definition er tabelværdisatte parametre stærkt skrevet til en brugerdefineret tabeltype, der skal eksistere i databasen, hvor opkaldet foretages. Stærkt skrevet er dog ikke rigtig strengt "stærkt skrevet", som du ville forvente, som denne artikel vil demonstrere, og ydeevnen kan blive påvirket som et resultat.
For at demonstrere de potentielle ydeevnepåvirkninger af forkert indtastede tabelværdiparametre med SQL Server, vil vi oprette et eksempel på en brugerdefineret tabeltype med følgende struktur:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Så skal vi bruge en .NET-applikation, der skal bruge denne brugerdefinerede tabeltype som inputparameter til at overføre data til SQL Server. For at bruge en tabelværdiparameter fra vores applikation, udfyldes et DataTable-objekt typisk og sendes derefter som værdien for parameteren med en type SqlDbType.Structured. Datatabellen kan oprettes på flere måder i .NET-koden, men en almindelig måde at oprette tabellen på er noget i stil med følgende:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); Du kan også oprette datatabellen ved at bruge den inline-definition som følger:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; En af disse definitioner af DataTable-objektet i .NET kan bruges som en tabelværdiparameter for den brugerdefinerede datatype, der blev oprettet, men vær opmærksom på type(streng)definitionen for de forskellige strengkolonner; disse kan alle være "korrekt" skrevet, men de er faktisk ikke stærkt skrevet til de datatyper, der er implementeret i den brugerdefinerede datatype. Vi kan udfylde tabellen med tilfældige data og videregive den til SQL Server som en parameter til en meget simpel SELECT-sætning, der vil returnere nøjagtig de samme rækker som tabellen, som vi sendte i, som følger:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
} Vi kan derefter bruge en fejlretningspause, så vi kan inspicere definitionen af DefaultTable under udførelsen, som vist nedenfor:
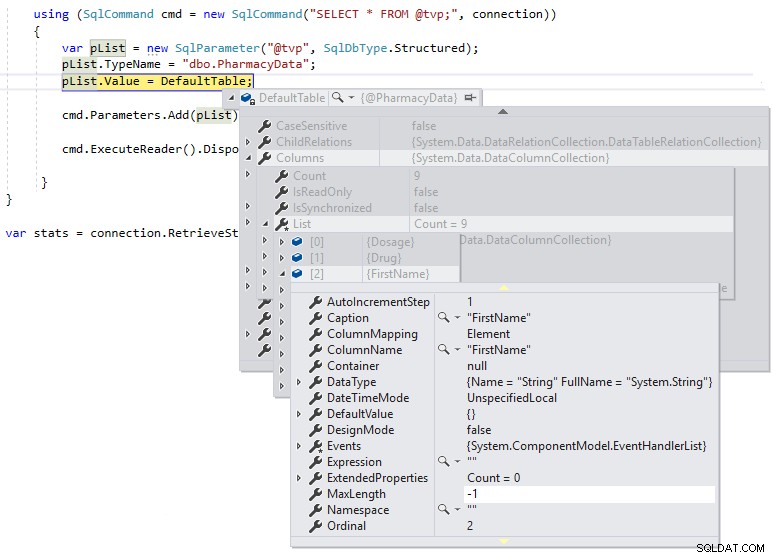
Vi kan se, at MaxLength for strengkolonnerne er sat til -1, hvilket betyder, at de overføres til TDS til SQL Server som LOB'er (store objekter) eller i det væsentlige som MAX datatypede kolonner, og dette kan påvirke ydeevnen på en negativ måde. Hvis vi ændrer .NET DataTable-definitionen til at være stærkt indskrevet til skemadefinitionen af den brugerdefinerede tabeltype som følger og ser på MaxLength af samme kolonne ved hjælp af et fejlretningsbrud:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};
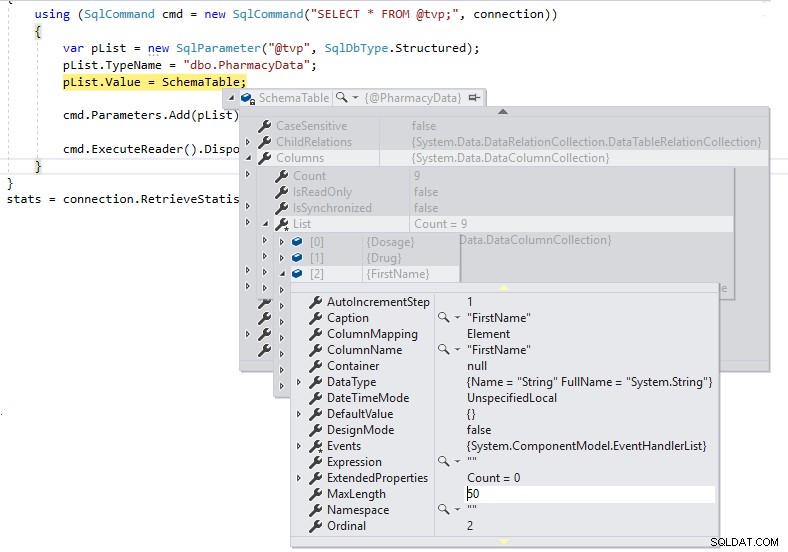
Vi har nu korrekte længder for kolonnedefinitionerne, og vi vil ikke videregive dem som LOB'er over TDS til SQL Server.
Hvordan påvirker dette ydeevnen, undrer du dig måske? Det påvirker antallet af TDS-buffere, der sendes på tværs af netværket til SQL Server, og det påvirker også den samlede behandlingstid for kommandoerne.
Ved at bruge nøjagtigt det samme datasæt for de to datatabeller og udnytte RetrieveStatistics-metoden på SqlConnection-objektet kan vi få ExecutionTime og BuffersSent-statistikmetrikkene for opkaldene til den samme SELECT-kommando og blot bruge de to forskellige DataTable-definitioner som parametre og ved at kalde SqlConnection-objektets ResetStatistics-metode kan udførelsesstatistikken ryddes mellem testene.
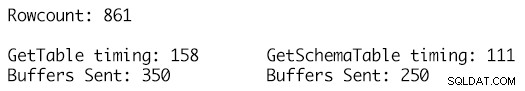
GetSchemaTable-definitionen specificerer MaxLength for hver af strengkolonnerne korrekt, hvor GetTable blot tilføjer kolonner af typen streng, der har en MaxLength-værdi sat til -1, hvilket resulterer i, at 100 yderligere TDS-buffere sendes for 861 rækker af data i tabellen og en kørselstid på 158 millisekunder sammenlignet med, at der kun sendes 250 buffere til den stærkt indtastede DataTable-definition og en køretid på 111 millisekunder. Selvom dette måske ikke ser ud til at være meget i den store sammenhæng, er dette et enkelt opkald, enkelt henrettelse, og den akkumulerede effekt over tid for mange tusinde eller millioner af sådanne henrettelser er, hvor fordelene begynder at lægge sig sammen og har en mærkbar effekt på arbejdsbyrdes ydeevne og gennemløb.
Hvor dette virkelig kan gøre en forskel, er i cloud-implementeringer, hvor du betaler for mere end blot computer- og lagerressourcer. Ud over at have de faste omkostninger til hardwareressourcer til Azure VM, SQL Database eller AWS EC2 eller RDS, er der en ekstra omkostning for netværkstrafik til og fra skyen, som er knyttet til faktureringen for hver måned. Reduktion af bufferne, der går på tværs af ledningen, vil sænke TCO for løsningen over tid, og de kodeændringer, der kræves for at implementere disse besparelser, er relativt enkle.