ROW_NUMBER vinduesfunktionen har adskillige praktiske anvendelser, langt ud over blot de åbenlyse rangeringsbehov. Det meste af tiden, når du beregner rækkenumre, skal du beregne dem ud fra en eller anden rækkefølge, og du angiver den ønskede bestillingsspecifikation i funktionens vinduesrækkefølge. Der er dog tilfælde, hvor du skal beregne rækkenumre i en bestemt rækkefølge; med andre ord baseret på ikke-deterministisk orden. Dette kan være på tværs af hele forespørgselsresultatet eller inden for partitioner. Eksempler omfatter tildeling af unikke værdier til resultatrækker, deduplikering af data og returnering af enhver række pr. gruppe.
Bemærk, at behovet for at tildele rækkenumre baseret på ikke-deterministisk rækkefølge er anderledes end at skulle tildele dem baseret på tilfældig rækkefølge. Med førstnævnte er du bare ligeglad med, i hvilken rækkefølge de er tildelt, og om gentagne udførelser af forespørgslen bliver ved med at tildele de samme rækkenumre til de samme rækker eller ej. Med sidstnævnte forventer du, at gentagne henrettelser bliver ved med at ændre, hvilke rækker der bliver tildelt hvilke rækkenumre. Denne artikel udforsker forskellige teknikker til at beregne rækkenumre med ikke-deterministisk rækkefølge. Håbet er at finde en teknik, der er både pålidelig og optimal.
Særlig tak til Paul White for tippet om konstant foldning, for runtime constant-teknikken og for altid at være en god kilde til information!
Når ordren er vigtig
Jeg starter med tilfælde, hvor rækkenummerets rækkefølge betyder noget.
Jeg vil bruge en tabel kaldet T1 i mine eksempler. Brug følgende kode til at oprette denne tabel og udfylde den med eksempeldata:
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.T1; GO CREATE TABLE dbo.T1 ( id INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY, grp VARCHAR(10) NOT NULL, datacol INT NOT NULL ); INSERT INTO dbo.T1(id, grp, datacol) VALUES (11, 'A', 50), ( 3, 'B', 20), ( 5, 'A', 40), ( 7, 'B', 10), ( 2, 'A', 50);
Overvej følgende forespørgsel (vi kalder den forespørgsel 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Her ønsker du, at rækkenumre skal tildeles inden for hver gruppe identificeret af kolonnen grp, sorteret efter kolonnens datakol. Da jeg kørte denne forespørgsel på mit system, fik jeg følgende output:
id grp datacol n --- ---- -------- --- 5 A 40 1 2 A 50 2 11 A 50 3 7 B 10 1 3 B 20 2
Rækkenumre tildeles her i en delvis deterministisk og delvist ikke-deterministisk rækkefølge. Hvad jeg mener med dette er, at du har en forsikring om, at inden for den samme partition vil en række med en større datacol-værdi få en større rækkenummerværdi. Men da datacol ikke er unik inden for grp-partitionen, er rækkefølgen af tildeling af rækkenumre blandt rækker med samme grp- og datacol-værdier ikke-deterministisk. Sådan er det med rækkerne med id-værdierne 2 og 11. Begge har grp-værdien A og datacol-værdien 50. Da jeg udførte denne forespørgsel på mit system for første gang, fik rækken med id 2 række nummer 2 og række med id 11 fik række nummer 3. Skidt med sandsynligheden for at dette sker i praksis i SQL Server; hvis jeg kører forespørgslen igen, teoretisk set, kunne rækken med id 2 tildeles række nummer 3 og rækken med id 11 kunne tildeles række nummer 2.
Hvis du har brug for at tildele rækkenumre baseret på en fuldstændig deterministisk rækkefølge, der garanterer gentagelige resultater på tværs af udførelsen af forespørgslen, så længe de underliggende data ikke ændres, skal du have, at kombinationen af elementer i vinduespartitionerings- og rækkefølgeklausulerne er unikke. Dette kunne opnås i vores tilfælde ved at tilføje kolonne-id'et til vinduesrækkefølgen som en tiebreaker. OVER-sætningen ville da være:
OVER (PARTITION BY grp ORDER BY datacol, id)
I hvert fald, når man beregner rækkenumre baseret på en meningsfuld bestillingsspecifikation som i forespørgsel 1, skal SQL Server behandle rækkerne ordnet efter kombinationen af vinduesopdeling og bestillingselementer. Dette kan opnås ved enten at trække de forudbestilte data fra et indeks eller ved at sortere dataene. I øjeblikket er der intet indeks på T1 til at understøtte ROW_NUMBER-beregningen i Query 1, så SQL Server skal vælge at sortere dataene. Dette kan ses i planen for forespørgsel 1 vist i figur 1.
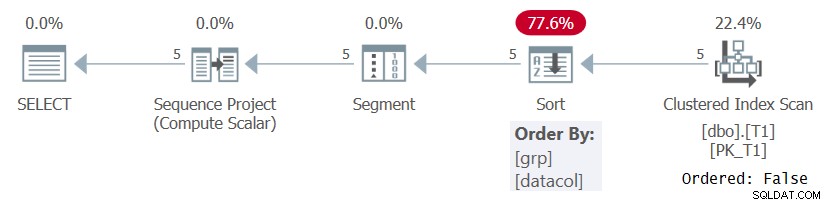 Figur 1:Plan for forespørgsel 1 uden et understøttende indeks
Figur 1:Plan for forespørgsel 1 uden et understøttende indeks
Bemærk, at planen scanner dataene fra det klyngede indeks med en Ordret:Falsk egenskab. Det betyder, at scanningen ikke behøver at returnere rækkerne, der er bestilt af indeksnøglen. Det er tilfældet, da det klyngede indeks bruges her, bare fordi det tilfældigvis dækker forespørgslen og ikke på grund af dets nøglerækkefølge. Planen anvender derefter en sortering, hvilket resulterer i ekstra omkostninger, N Log N-skalering og forsinket responstid. Segmentoperatoren producerer et flag, der angiver, om rækken er den første i partitionen eller ej. Til sidst tildeler sekvensprojektoperatøren rækkenumre, der starter med 1 i hver partition.
Hvis du vil undgå behovet for sortering, kan du udarbejde et dækkende indeks med en nøgleliste, der er baseret på opdelings- og bestillingselementerne, og en medtageliste, der er baseret på de dækkende elementer. Jeg kan godt lide at tænke på dette indeks som et POC-indeks (til partitionering , bestilling og dækning ). Her er definitionen af den POC, der understøtter vores forespørgsel:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Kør forespørgsel 1 igen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Planen for denne udførelse er vist i figur 2.
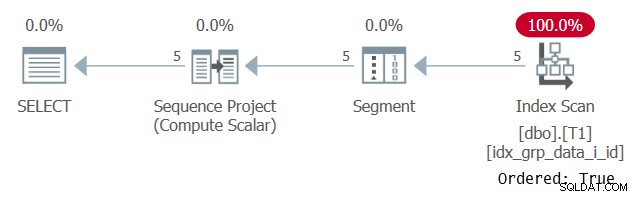 Figur 2:Plan for forespørgsel 1 med et POC-indeks
Figur 2:Plan for forespørgsel 1 med et POC-indeks
Bemærk, at denne gang scanner planen POC-indekset med en Ordret:Sand egenskab. Det betyder, at scanningen garanterer, at rækkerne returneres i indeksnøglerækkefølge. Da dataene trækkes forudbestilt fra indekset, som vinduesfunktionen har brug for, er der ikke behov for eksplicit sortering. Skaleringen af denne plan er lineær, og responstiden er god.
Når rækkefølgen ikke betyder noget
Tingene bliver lidt vanskelige, når du skal tildele rækkenumre med en fuldstændig ikke-deterministisk rækkefølge. Den naturlige ting at gøre i et sådant tilfælde er at bruge funktionen ROW_NUMBER uden at angive en vinduesrækkefølge. Lad os først tjekke, om SQL-standarden tillader dette. Her er den relevante del af standarden, der definerer syntaksreglerne for vinduesfunktioner:
Syntaksregler...
5) Lad WNS være
6) Hvis
a) Hvis
...
f) ROW_NUMBER() OVER WNS svarer til
...
Bemærk, at punkt 6 viser funktionerne
Så lad os prøve det og forsøge at beregne rækkenumre uden vinduesrækkefølge i SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Dette forsøg resulterer i følgende fejl:
Msg 4112, Level 15, State 1, Line 53Funktionen 'ROW_NUMBER' skal have en OVER-klausul med ORDER BY.
Faktisk, hvis du tjekker SQL Servers dokumentation af ROW_NUMBER-funktionen, vil du finde følgende tekst:
"order_by_clauseORDER BY-sætningen bestemmer rækkefølgen, hvori rækkerne tildeles deres unikke ROW_NUMBER inden for en specificeret partition. Det er påkrævet.”
Så tilsyneladende er vinduesrækkefølgen obligatorisk for ROW_NUMBER-funktionen i SQL Server. Det er i øvrigt også tilfældet i Oracle.
Jeg må sige, at jeg ikke er sikker på, at jeg forstår begrundelsen bag dette krav. Husk, at du tillader at definere rækkenumre baseret på en delvist ikke-deterministisk rækkefølge, som i forespørgsel 1. Så hvorfor ikke tillade ikke-determinisme hele vejen? Måske er der en eller anden grund, som jeg ikke tænker på. Hvis du kan komme i tanke om en sådan grund, så del venligst.
I hvert fald kan du argumentere for, at hvis du er ligeglad med ordren, da vinduesbestillingsklausulen er obligatorisk, kan du angive enhver ordre. Problemet med denne tilgang er, at hvis du bestiller efter en kolonne fra de forespurgte tabeller, kan dette medføre en unødvendig præstationsstraf. Når der ikke er noget understøttende indeks på plads, betaler du for eksplicit sortering. Når der er et understøttende indeks på plads, begrænser du lagermotoren til en indeksordrescanningsstrategi (efter den indekslinkede liste). Du tillader det ikke mere fleksibilitet, som det normalt har, når rækkefølgen ikke betyder noget ved valget mellem en indeksordrescanning og en allokeringsordrescanning (baseret på IAM-sider).
En idé, der er værd at prøve, er at angive en konstant, som 1, i vinduesrækkefølgen. Hvis det understøttes, vil du håbe, at optimeringsværktøjet er smart nok til at indse, at alle rækker har samme værdi, så der er ingen reel bestillingsrelevans og derfor ingen grund til at tvinge en sortering eller en indeksordrescanning. Her er en forespørgsel, der forsøger denne tilgang:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Desværre understøtter SQL Server ikke denne løsning. Det genererer følgende fejl:
Msg 5308, Level 16, State 1, Line 56Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke heltalsindekser som ORDER BY-udtryk.
Tilsyneladende antager SQL Server, at hvis du bruger en heltalskonstant i vinduesrækkefølgen, repræsenterer den en ordensposition for et element i SELECT-listen, som når du angiver et heltal i præsentationen ORDER BY-udtrykket. Hvis det er tilfældet, er en anden mulighed, der er værd at prøve at angive en ikke-heltalskonstant, som sådan:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No Order') AS n FROM dbo.T1;
Det viser sig, at denne løsning også ikke understøttes. SQL Server genererer følgende fejl:
Msg 5309, Level 16, State 1, Line 65Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke konstanter som ORDER BY-udtryk.
Tilsyneladende understøtter vinduesrækkefølgen ikke nogen form for konstant.
Indtil videre har vi lært følgende om ROW_NUMBER-funktionens vinduesbestillingsrelevans i SQL Server:
- BESTILLING AF er påkrævet.
- Kan ikke sorteres efter en heltalskonstant, da SQL Server mener, at du forsøger at angive en ordensposition i SELECT.
- Kan ikke sorteres efter nogen form for konstant.
Konklusionen er, at du skal sortere efter udtryk, der ikke er konstanter. Det er klart, at du kan bestille efter en kolonneliste fra den eller de forespurgte tabeller. Men vi er på jagt efter at finde en effektiv løsning, hvor optimeringsværktøjet kan indse, at der ikke er nogen ordrerelevans.
Konstant foldning
Konklusionen indtil videre er, at du ikke kan bruge konstanter i ROW_NUMBER's vinduesrækkefølge, men hvad med udtryk baseret på konstanter, såsom i følgende forespørgsel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Dette forsøg bliver dog offer for en proces kendt som konstant foldning, som normalt har en positiv præstationsindvirkning på forespørgsler. Ideen bag denne teknik er at forbedre forespørgselsydeevnen ved at folde nogle udtryk baseret på konstanter til deres resultatkonstanter på et tidligt stadium af forespørgselsbehandlingen. Du kan finde detaljer om, hvilke slags udtryk der konstant kan foldes her. Vores udtryk 1+0 foldes til 1, hvilket resulterer i den samme fejl, som du fik, da du specificerede konstanten 1 direkte:
Msg 5308, Level 16, State 1, Line 79Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke heltalsindekser som ORDER BY-udtryk.
Du vil stå over for en lignende situation, når du forsøger at sammenkæde to bogstaver i tegnstrengen, som f.eks.:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No' + ' Order') AS n FROM dbo.T1;
Du får den samme fejl, som du fik, da du specificerede den bogstavelige 'Ingen ordre' direkte:
Msg 5309, Level 16, State 1, Line 55Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke konstanter som ORDER BY-udtryk.
Bizarro world – fejl, der forhindrer fejl
Livet er fuld af overraskelser...
En ting, der forhindrer konstant foldning, er, når udtrykket normalt ville resultere i en fejl. For eksempel kan udtrykket 2147483646+1 være konstant foldet, da det resulterer i en gyldig INT-type værdi. Som følge heraf mislykkes et forsøg på at køre følgende forespørgsel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 109
Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke heltalsindekser som ORDER BY-udtryk.
Udtrykket 2147483647+1 kan dog ikke foldes konstant, fordi et sådant forsøg ville have resulteret i en INT-overløbsfejl. Implikationen på bestilling er ret interessant. Prøv følgende forespørgsel (vi kalder denne forespørgsel 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Mærkeligt nok kører denne forespørgsel med succes! Det der sker er, at SQL Server på den ene side undlader at anvende konstant foldning, og derfor er rækkefølgen baseret på et udtryk, der ikke er en enkelt konstant. På den anden side regner optimeringsværktøjet med, at bestillingsværdien er den samme for alle rækker, så den ignorerer bestillingsudtrykket helt. Dette bekræftes, når planen for denne forespørgsel undersøges som vist i figur 3.
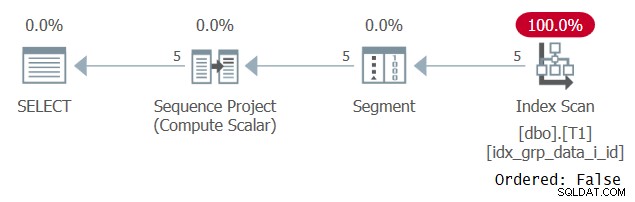 Figur 3:Plan for forespørgsel 2
Figur 3:Plan for forespørgsel 2
Bemærk, at planen scanner et dækkende indeks med en Ordret:Falsk egenskab. Dette var præcis vores præstationsmål.
På lignende måde involverer følgende forespørgsel et vellykket konstant foldningsforsøg og mislykkes derfor:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 123
Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke heltalsindekser som ORDER BY-udtryk.
Følgende forespørgsel involverer et mislykket konstant foldningsforsøg og lykkes derfor, og genererer planen vist tidligere i figur 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Følgende forespørgsel involverer et vellykket konstant foldningsforsøg (VARCHAR bogstavelige '1' bliver implicit konverteret til INT 1, og derefter foldes 1 + 1 til 2), og mislykkes derfor:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'1') AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 134
Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke heltalsindekser som ORDER BY-udtryk.
Følgende forespørgsel involverer et mislykket konstant foldningsforsøg (kan ikke konvertere 'A' til INT), og lykkes derfor, og genererer planen vist tidligere i figur 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'A') AS n FROM dbo.T1;
For at være ærlig, selvom denne bizarro teknik opnår vores oprindelige præstationsmål, kan jeg ikke sige, at jeg anser den for sikker, og derfor er jeg ikke så tryg ved at stole på den.
Køretidskonstanter baseret på funktioner
Hvis vi fortsætter søgningen efter en god løsning til at beregne rækkenumre med ikke-deterministisk rækkefølge, er der nogle få teknikker, der virker sikrere end den sidste finurlige løsning:Brug af runtime-konstanter baseret på funktioner, brug af en underforespørgsel baseret på en konstant, brug af en aliaseret kolonne baseret på en konstant og ved hjælp af en variabel.
Som jeg forklarer i T-SQL-fejl, faldgruber og bedste praksis – determinisme, evalueres de fleste funktioner i T-SQL kun én gang pr. reference i forespørgslen – ikke én gang pr. række. Dette er tilfældet selv med de fleste ikke-deterministiske funktioner som GETDATE og RAND. Der er meget få undtagelser fra denne regel, som funktionerne NEWID og CRYPT_GEN_RANDOM, som bliver evalueret én gang pr. række. De fleste funktioner, som GETDATE, @@SPID og mange andre, evalueres én gang i begyndelsen af forespørgslen, og deres værdier betragtes derefter som køretidskonstanter. En henvisning til sådanne funktioner bliver ikke konstant foldet. Disse karakteristika gør en køretidskonstant, der er baseret på en funktion, til et godt valg som vinduesbestillingselement, og det ser faktisk ud til, at T-SQL understøtter det. Samtidig indser optimeringsværktøjet, at der i praksis ikke er nogen ordrerelevans, hvilket undgår unødvendige præstationsstraffe.
Her er et eksempel, der bruger GETDATE-funktionen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Denne forespørgsel får den samme plan som vist tidligere i figur 3.
Her er et andet eksempel, der bruger @@SPID-funktionen (returnerer det aktuelle sessions-id):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Hvad med funktionen PI? Prøv følgende forespørgsel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Denne fejler med følgende fejl:
Msg 5309, Level 16, State 1, Line 153Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke konstanter som ORDER BY-udtryk.
Funktioner som GETDATE og @@SPID bliver revurderet én gang pr. udførelse af planen, så de kan ikke blive foldet konstant. PI repræsenterer altid den samme konstant og bliver derfor konstant foldet.
Som tidligere nævnt er der meget få funktioner, der bliver evalueret én gang pr. række, såsom NEWID og CRYPT_GEN_RANDOM. Dette gør dem til et dårligt valg som vinduesbestillingselement, hvis du har brug for ikke-deterministisk rækkefølge - ikke at forveksle med tilfældig rækkefølge. Hvorfor betale en unødvendig bøde?
Her er et eksempel, der bruger funktionen NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Planen for denne forespørgsel er vist i figur 4, hvilket bekræfter, at SQL Server tilføjede eksplicit sortering baseret på funktionens resultat.
 Figur 4:Plan for forespørgsel 3
Figur 4:Plan for forespørgsel 3
Hvis du ønsker, at rækkenumrene skal tildeles i tilfældig rækkefølge, er det i hvert fald den teknik, du vil bruge. Du skal blot være opmærksom på, at det medfører sorteringsomkostningerne.
Brug af en underforespørgsel
Du kan også bruge en underforespørgsel baseret på en konstant som vinduesbestillingsudtryk (f.eks. ORDER BY (SELECT 'No Order')). Også med denne løsning erkender SQL Servers optimizer, at der ikke er nogen ordrerelevans, og pålægger derfor ikke en unødvendig sortering eller begrænser lagermotorens valg til dem, der skal garantere orden. Prøv at køre følgende forespørgsel som et eksempel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'No Order')) AS n FROM dbo.T1;
Du får den samme plan som vist tidligere i figur 3.
En af de store fordele ved denne teknik er, at du kan tilføje dit eget personlige præg. Måske kan du virkelig godt lide NULLs:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Måske kan du virkelig godt lide et bestemt antal:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Måske vil du sende en besked til nogen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'Lilach, will you marry me?')) AS n FROM dbo.T1;
Du forstår pointen.
Gøreligt, men akavet
Der er et par teknikker, der virker, men som er lidt akavede. Den ene er at definere et kolonnealias for et udtryk baseret på en konstant og derefter bruge det kolonnealias som vinduesbestillingselementet. Du kan gøre dette enten ved hjælp af et tabeludtryk eller med CROSS APPLY-operatoren og en tabelværdikonstruktør. Her er et eksempel på sidstnævnte:
SELECT id, grp, datacol,
ROW_NUMBER() OVER(ORDER BY [I'm a bit ugly]) AS n
FROM dbo.T1 CROSS APPLY ( VALUES('No Order') ) AS A([I'm a bit ugly]); Du får den samme plan som vist tidligere i figur 3.
En anden mulighed er at bruge en variabel som vinduesbestillingselement:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Denne forespørgsel får også planen vist tidligere i figur 3.
Hvad hvis jeg bruger min egen UDF?
Du tror måske, at brug af din egen UDF, der returnerer en konstant, kunne være et godt valg som vinduesbestillingselement, når du ønsker en ikke-deterministisk rækkefølge, men det er det ikke. Overvej følgende UDF-definition som et eksempel:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis; GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INT AS BEGIN RETURN NULL END; GO
Prøv at bruge UDF'en som vinduesbestillingsklausulen, som sådan (vi kalder denne forespørgsel 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Før SQL Server 2019 (eller parallelt kompatibilitetsniveau <150) bliver brugerdefinerede funktioner evalueret pr. række. Selvom de returnerer en konstant, bliver de ikke indlejret. Følgelig kan du på den ene side bruge sådan en UDF som vinduesbestillingselementet, men på den anden side resulterer dette i en sorteringsstraf. Dette bekræftes ved at undersøge planen for denne forespørgsel, som vist i figur 5.
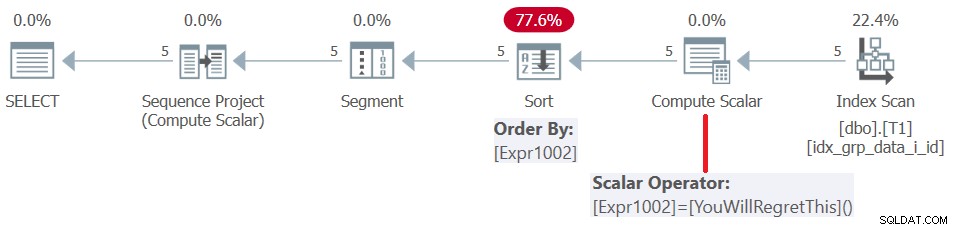 Figur 5:Plan for forespørgsel 4
Figur 5:Plan for forespørgsel 4
Startende med SQL Server 2019, under kompatibilitetsniveau>=150, bliver sådanne brugerdefinerede funktioner indlejret, hvilket for det meste er en fantastisk ting, men i vores tilfælde resulterer i en fejl:
Msg 5309, Level 16, State 1, Line 217Windowed-funktioner, aggregater og NEXT VALUE FOR-funktioner understøtter ikke konstanter som ORDER BY-udtryk.
Så brug af en UDF baseret på en konstant som vinduesbestillingselement fremtvinger enten en sortering eller en fejl afhængigt af den version af SQL Server, du bruger, og dit databasekompatibilitetsniveau. Kort sagt, lad være med at gøre dette.
Opdelte rækkenumre med ikke-deterministisk rækkefølge
Et almindeligt tilfælde for opdelte rækkenumre baseret på ikke-deterministisk rækkefølge er at returnere enhver række pr. gruppe. Da der per definition eksisterer et partitioneringselement i dette scenarie, ville du tro, at en sikker teknik i et sådant tilfælde ville være at bruge vinduespartitioneringselementet også som vinduesbestillingselementet. Som et første trin beregner du rækkenumre som sådan:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Planen for denne forespørgsel er vist i figur 6.
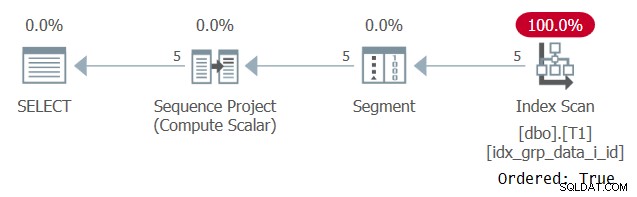 Figur 6:Plan for forespørgsel 5
Figur 6:Plan for forespørgsel 5
Grunden til, at vores understøttende indeks scannes med en Ordered:True-egenskab, er fordi SQL Server skal behandle hver partitions rækker som en enkelt enhed. Det er tilfældet før filtrering. Hvis du kun filtrerer én række pr. partition, har du både ordrebaserede og hash-baserede algoritmer som muligheder.
Det andet trin er at placere forespørgslen med rækkenummerberegningen i et tabeludtryk, og i den ydre forespørgsel filtrere rækken med rækkenummer 1 i hver partition, sådan:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Teoretisk set formodes denne teknik at være sikker, men Paul White fandt en fejl, der viser, at du ved at bruge denne metode kan få attributter fra forskellige kilderækker i den returnerede resultatrække pr. partition. Brug af en runtime-konstant baseret på en funktion eller en underforespørgsel baseret på en konstant, da bestillingselementet ser ud til at være sikkert selv med dette scenarie, så sørg for at bruge en løsning som f.eks. følgende i stedet:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY (SELECT 'No Order')) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Ingen må passere denne vej uden min tilladelse
At forsøge at beregne rækkenumre baseret på ikke-deterministisk rækkefølge er et almindeligt behov. Det ville have været rart, hvis T-SQL blot gjorde vinduesrækkefølgen valgfri for ROW_NUMBER-funktionen, men det gør den ikke. Hvis ikke, ville det have været rart, hvis det i det mindste tillod at bruge en konstant som bestillingselement, men det er heller ikke en understøttet mulighed. Men hvis du spørger pænt, i form af en underforespørgsel baseret på en konstant eller en runtime konstant baseret på en funktion, vil SQL Server tillade det. Det er de to muligheder, som jeg er mest tryg ved. Jeg føler mig ikke rigtig godt tilpas med de skæve fejlagtige udtryk, der ser ud til at virke, så jeg kan ikke anbefale denne mulighed.