Der er flere metoder til at se på dårligt ydende forespørgsler i SQL Server, især Query Store, Extended Events og dynamiske administrationsvisninger (DMV'er). Hver mulighed har fordele og ulemper. Extended Events giver data om den individuelle udførelse af forespørgsler, mens Query Store og DMV'erne samler ydeevnedata. For at bruge Query Store og Extended Events skal du konfigurere dem på forhånd – enten aktivere Query Store for din(e) database(r), eller konfigurere en XE-session og starte den. DMV-data er altid tilgængelige, så meget ofte er det den nemmeste metode til at få et hurtigt første kig på forespørgselsydeevne. Det er her, Glenns DMV-forespørgsler kommer til nytte - i hans script har han flere forespørgsler, som du kan bruge til at finde de øverste forespørgsler for instansen baseret på CPU, logisk I/O og varighed. At målrette mod de mest ressourcekrævende forespørgsler er ofte en god start ved fejlfinding, men vi kan ikke glemme scenariet "død med tusinde snit" - forespørgslen eller sættet af forespørgsler, der kører MEGET ofte - måske hundredvis eller tusindvis af gange pr. minut. Glenn har en forespørgsel i sit sæt, der viser topforespørgsler til en database baseret på antal eksekveringer, men efter min erfaring giver det dig ikke et komplet billede af din arbejdsbyrde.
Den vigtigste DMV, der bruges til at se på forespørgselsydeevnemålinger, er sys.dm_exec_query_stats. Yderligere data, der er specifikke for lagrede procedurer (sys.dm_exec_procedure_stats), funktioner (sys.dm_exec_function_stats) og triggere (sys.dm_exec_trigger_stats) er også tilgængelige, men overvej en arbejdsbyrde, der ikke udelukkende er lagrede procedurer, funktioner og triggere. Overvej en blandet arbejdsbyrde, der har nogle ad hoc-forespørgsler, eller måske er helt ad hoc.
Eksempelscenarie
Når vi låner og tilpasser kode fra et tidligere indlæg, Undersøgelse af ydeevnepåvirkningen af en adhoc-arbejdsbelastning, vil vi først oprette to lagrede procedurer. Den første, dbo.RandomSelects, genererer og udfører en ad hoc-sætning, og den anden, dbo.SPRandomSelects, genererer og udfører en parametriseret forespørgsel.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Nu vil vi udføre begge lagrede procedurer 1000 gange ved at bruge den samme metode som beskrevet i mit tidligere indlæg med .cmd-filer, der kalder .sql-filer med følgende udsagn:
Adhoc.sql-filindhold:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Parameterized.sql filindhold:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Eksempel på syntaks i .cmd-fil, der kalder .sql-filen:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Hvis vi bruger en variant af Glenns Top Worker Time-forespørgsel til at se på de mest populære forespørgsler baseret på worker time (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
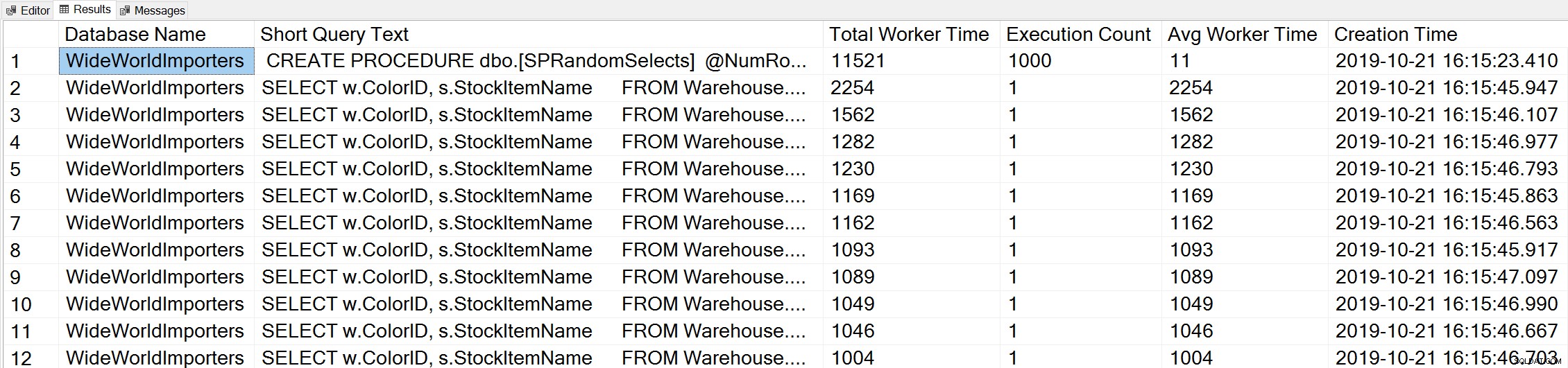
Vi ser erklæringen fra vores lagrede procedure som den forespørgsel, der udføres med den højeste mængde kumulativ CPU.
Hvis vi kører en variant af Glenns Query Execution Counts-forespørgsel mod WideWorldImporters-databasen:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
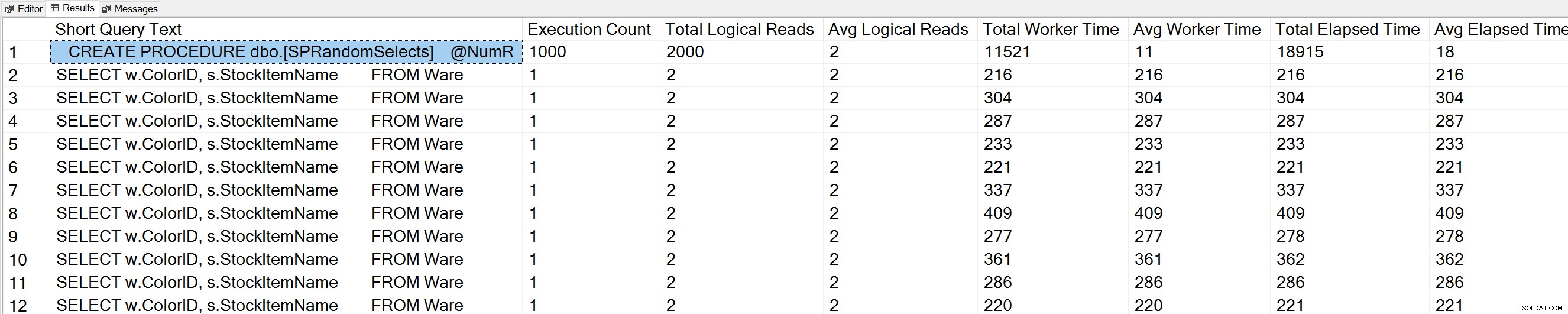
Vi ser også vores erklæring om lagrede procedurer øverst på listen.
Men den ad hoc-forespørgsel, som vi udførte, selvom den har forskellige bogstavelige værdier, var i det væsentlige den samme sætning udført gentagne gange, som vi kan se ved at se på query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
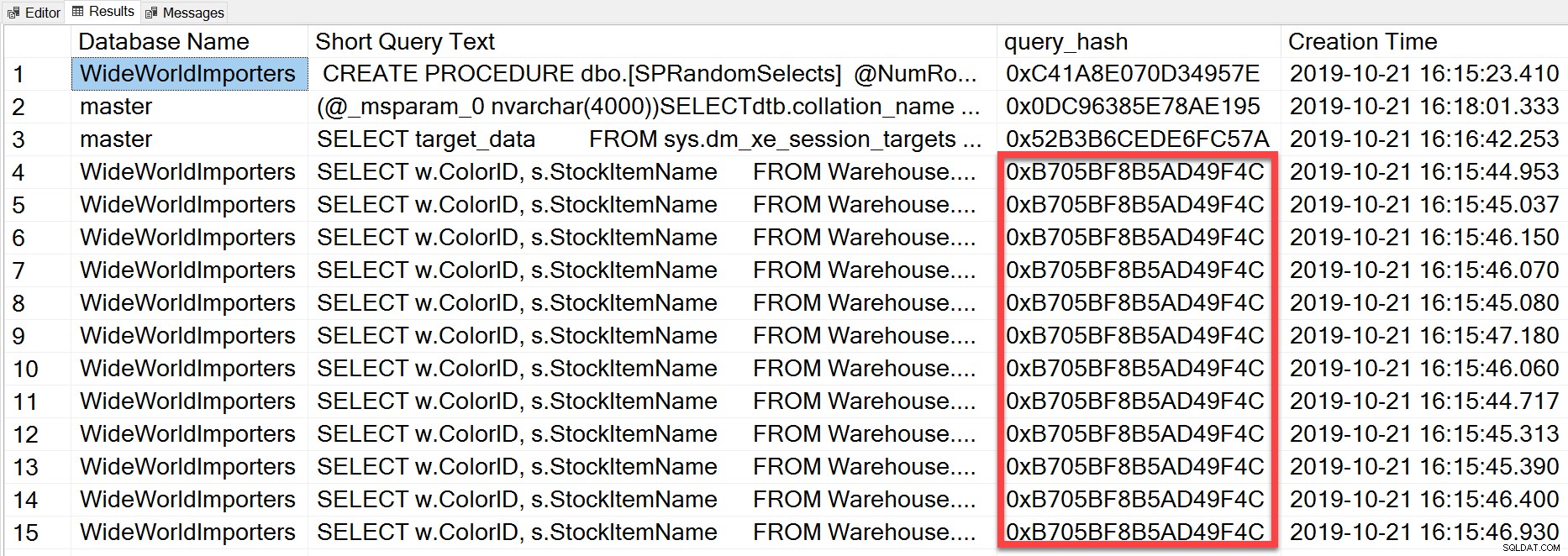
Query_hash blev tilføjet i SQL Server 2008 og er baseret på træet af de logiske operatorer genereret af Query Optimizer for sætningsteksten. Forespørgsler, der har en lignende sætningstekst, som genererer det samme træ af logiske operatorer, vil have den samme query_hash, selvom de bogstavelige værdier i forespørgselsprædikatet er forskellige. Selvom de bogstavelige værdier kan være forskellige, skal objekterne og deres aliaser være de samme, såvel som forespørgselstip og potentielt indstillingerne SET. RandomSelects lagrede procedure genererer forespørgsler med forskellige bogstavelige værdier:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Men hver udførelse har nøjagtig samme værdi for query_hash, 0xB705BF8B5AD49F4C. For at forstå, hvor ofte en ad hoc-forespørgsel – og dem, der er ens med hensyn til query_hash – udføres, er vi nødt til at gruppere efter query_hash-rækkefølgen på det antal, i stedet for at se på execution_count i sys.dm_exec_query_stats (som ofte viser en værdi på 1).
Hvis vi ændrer kontekst til WideWorldImporters-databasen og leder efter topforespørgsler baseret på eksekveringsantal, hvor vi grupperer på query_hash, kan vi nu se både den lagrede procedure og vores ad hoc-forespørgsel:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Bemærk:sys.dm_exec_function_stats DMV blev tilføjet i SQL Server 2016. Kørsel af denne forespørgsel på SQL Server 2014 og tidligere kræver fjernelse af reference til denne DMV.
Dette output giver en meget mere omfattende forståelse af, hvilke forespørgsler der virkelig udføres oftest, da det aggregeres baseret på query_hash, ikke ved blot at se på execution_count i sys.dm_exec_query_stats, som kan have flere indgange for den samme query_hash, når forskellige bogstavelige værdier er Brugt. Forespørgselsoutputtet inkluderer også query_plan_hash, som kan være anderledes for forespørgsler med den samme query_hash. Disse yderligere oplysninger er nyttige ved evaluering af planens ydeevne for en forespørgsel. I eksemplet ovenfor har hver forespørgsel den samme query_plan_hash, 0x299275DD475C4B17, hvilket viser, at selv med forskellige inputværdier genererer Query Optimizer den samme plan – den er stabil. Når der findes flere query_plan_hash-værdier for den samme query_hash, eksisterer planvariabiliteten. I et scenarie, hvor den samme forespørgsel, baseret på query_hash, udføres tusindvis af gange, er en generel anbefaling at parametrere forespørgslen. Hvis du kan verificere, at der ikke eksisterer nogen planvariabilitet, fjerner parametrisering af forespørgslen optimerings- og kompileringstiden for hver udførelse og kan reducere den samlede CPU. I nogle scenarier kan parametrering af fem til 10 ad hoc-forespørgsler forbedre systemets ydeevne som helhed.
Oversigt
For ethvert miljø er det vigtigt at forstå, hvilke forespørgsler der er dyrest med hensyn til ressourceforbrug, og hvilke forespørgsler der kører oftest. Det samme sæt forespørgsler kan dukke op for begge typer analyser, når du bruger Glenns DMV-script, hvilket kan være vildledende. Som sådan er det vigtigt at fastslå, om arbejdsbyrden for det meste er proceduremæssig, for det meste ad hoc eller en blanding. Selvom der er meget dokumenteret om fordelene ved lagrede procedurer, finder jeg, at blandede eller meget ad hoc-arbejdsbelastninger er meget almindelige, især med løsninger, der bruger objektrelationelle kortlæggere (ORM'er) såsom Entity Framework, NHibernate og LINQ til SQL. Hvis du ikke er klar over typen af arbejdsbyrde for en server, er det en god start at køre ovenstående forespørgsel for at se på de mest udførte forespørgsler baseret på en query_hash. Efterhånden som du begynder at forstå arbejdsbyrden og hvad der eksisterer for både de tunge personer og dødsfaldsforespørgslerne, kan du gå videre til virkelig at forstå ressourceanvendelse og den indvirkning, disse forespørgsler har på systemets ydeevne, og målrette din indsats for tuning.