Et af nøgleaspekterne ved høj tilgængelighed er evnen til hurtigt at reagere på fejl. Det er ikke ualmindeligt at administrere databaser manuelt og have overvågningssoftware til at holde øje med databasens sundhed. I tilfælde af fejl sender overvågningssoftwaren en advarsel til vagtpersonalet. Det betyder, at nogen potentielt har brug for at vågne op, komme til en computer og logge ind på systemer og se på logs - det vil sige, at der er en del leveringstid, før udbedring kan starte. Ideelt set bør hele processen automatiseres.
I denne blog vil vi se på, hvordan man implementerer et fuldt automatiseret system, der registrerer, når den primære database fejler, og starter failover-procedurer ved at promovere en sekundær database. Vi vil bruge ClusterControl til at udføre automatisk failover af Moodle PostgreSQL-databasen.
Fordel ved automatisk failover
- Mindre tid til at gendanne databasetjenesten
- Højere systemoppetid
- Mindre afhængighed af DBA'en eller administratoren, der konfigurerer høj tilgængelighed for databasen
Arkitektur
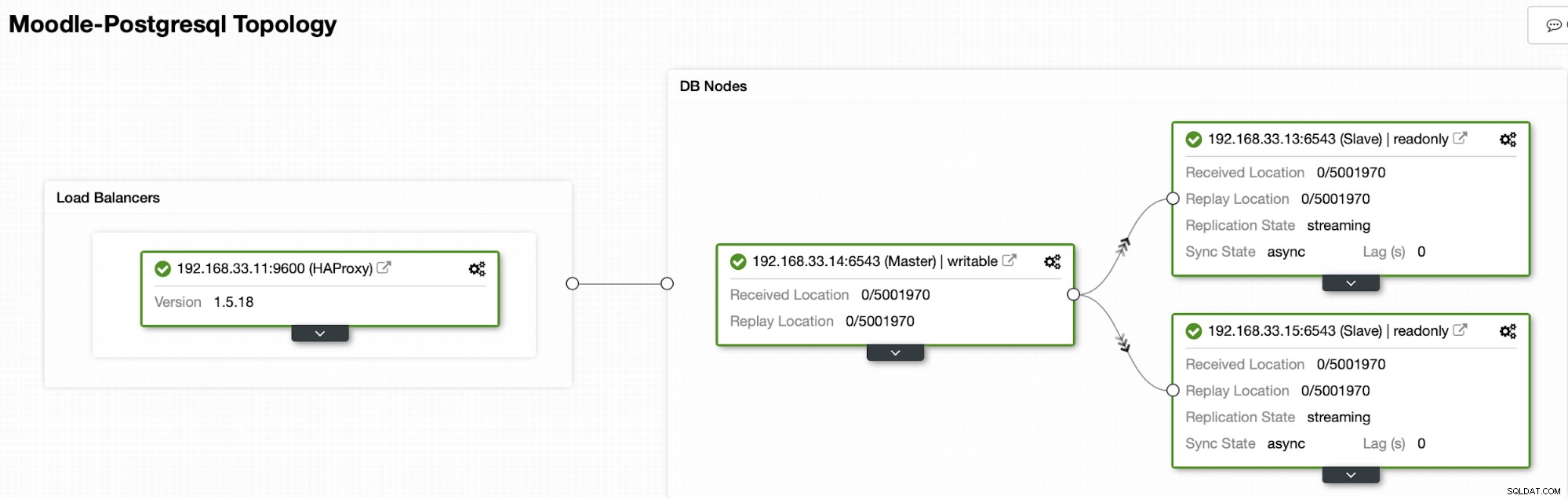
I øjeblikket har vi en Postgres primær server og to sekundære servere under HAProxy load balancer der sender Moodle-trafikken til den primære PostgreSQL-knude. Cluster recovery og node auto recovery i ClusterControl er de vigtige indstillinger for at udføre den automatiske failover-proces.

Kontrol af hvilken server der skal failover til
ClusterControl tilbyder whitelisting og blacklisting af et sæt servere, som du ønsker at deltage i failover eller udelukke som kandidat.
Der er to variabler, du kan indstille i cmon-konfigurationen,
- replication_failover_whitelist :den indeholder en liste over IP'er eller værtsnavne på sekundære servere, som bør bruges som potentielle primære kandidater. Hvis denne variabel er indstillet, vil kun disse værter blive taget i betragtning.
- replication_failover_blacklist :den indeholder en liste over værter, som aldrig vil blive betragtet som en primær kandidat. Du kan bruge det til at liste sekundære servere, der bruges til sikkerhedskopier eller analytiske forespørgsler. Hvis hardwaren varierer mellem sekundære servere, kan du her placere de servere, der bruger langsommere hardware.
Automatisk failover-proces
Trin 1
Vi har startet dataindlæsningen på den primære server (192.168.33.14) ved hjælp af sysbench-værktøjet.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Trin 2
Vi vil stoppe Postgres primære server (192.168.33.14). I ClusterControl er parameteren (enable_cluster_autorecovery) aktiveret, så den vil fremme den næste passende primære.
# service postgresql-12 stopTrin 3
ClusterControl registrerer fejl i den primære og fremmer en sekundær med de mest aktuelle data som en ny primær. Det virker også på resten af de sekundære servere for at få dem til at replikere fra den nye primære.

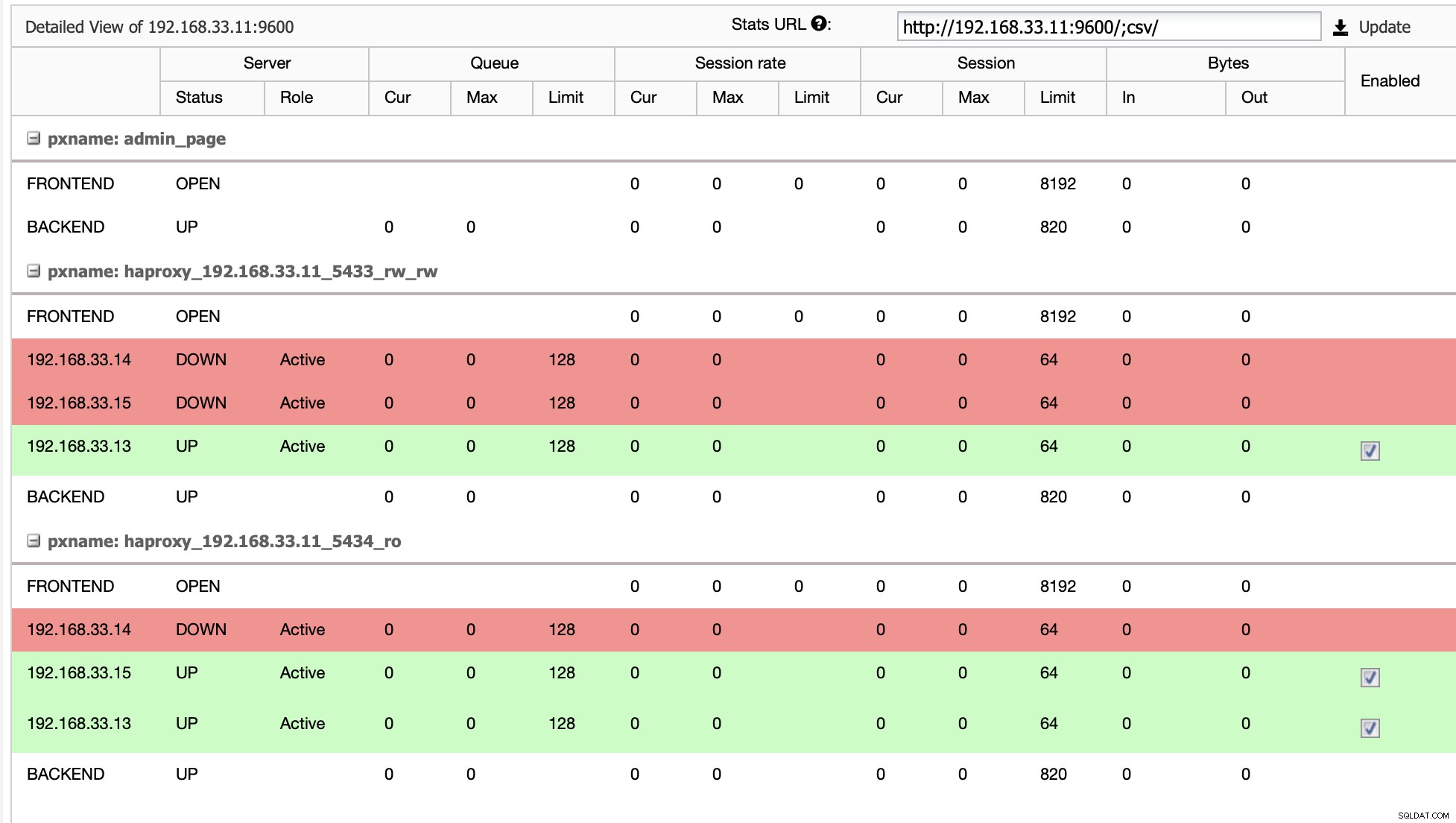
I vores tilfælde er (192.168.33.13) en ny primær server og sekundære servere replikeres nu fra denne nye primære server. Nu dirigerer HAProxy databasetrafikken fra Moodle-serverne til den seneste primære server.
Fra (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Fra (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Aktuel topologi
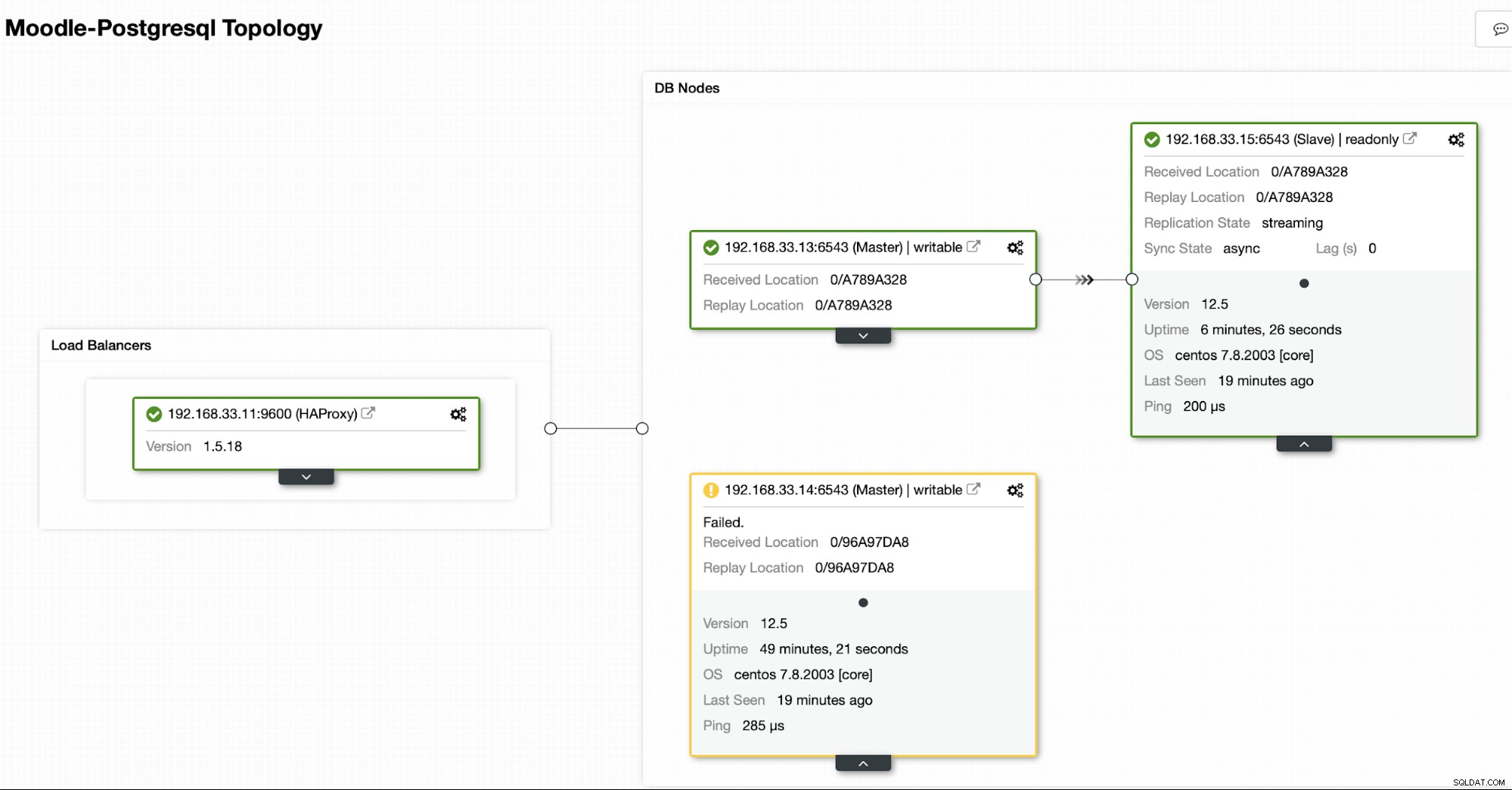
Når HAProxy registrerer, at en af vores noder, enten primær eller replika, er ikke tilgængelig, markerer den automatisk som offline. HAProxy sender ikke nogen trafik fra Moodle-applikationen til den. Denne kontrol udføres af sundhedstjekscripts, der er konfigureret af ClusterControl på tidspunktet for implementeringen.
Når ClusterControl promoverer en replikaserver til primær, markerer vores HAProxy den gamle primære som offline og sætter den promoverede node online.
Når den gamle primære er online igen, synkroniseres den ikke automatisk til den nye primære server. Vi skal lukke det tilbage i topologien, og det kan gøres via ClusterControl-grænsefladen. Dette vil undgå muligheden for tab af data eller inkonsistens, hvis vi ønsker at undersøge, hvorfor denne server fejlede i første omgang.
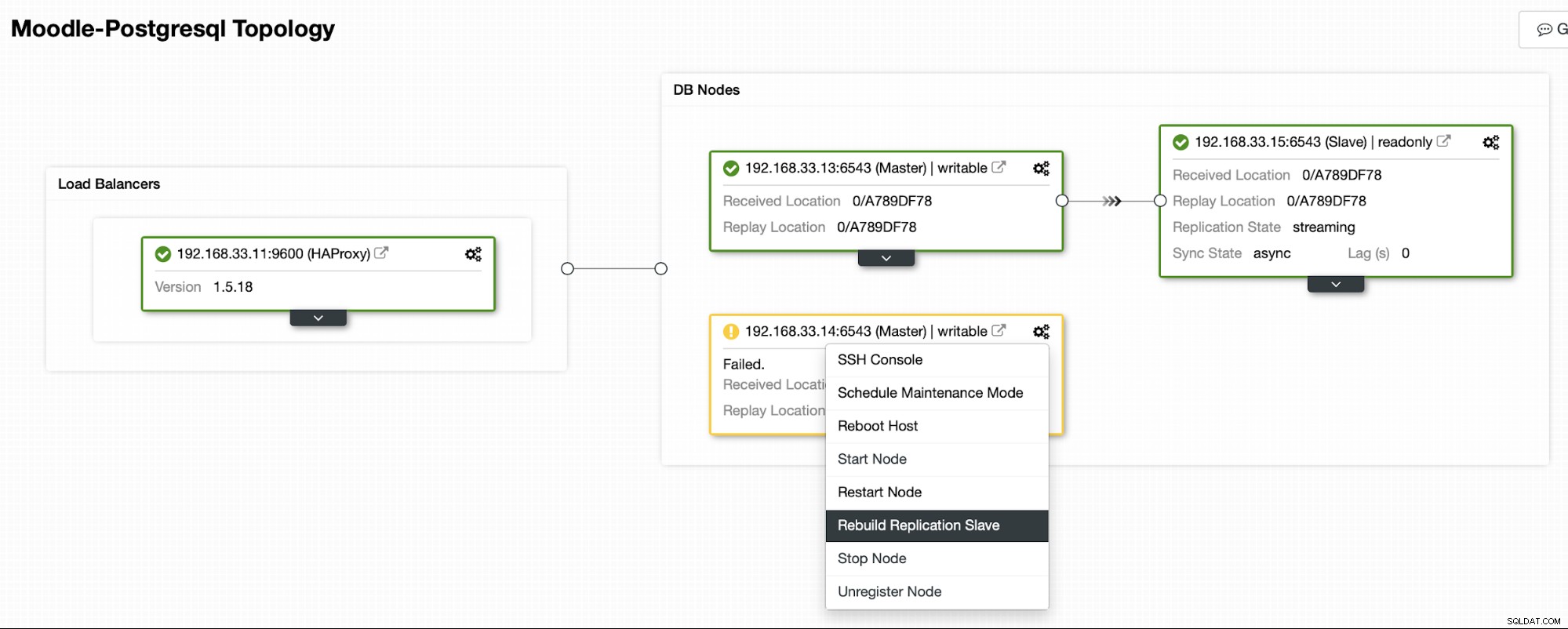
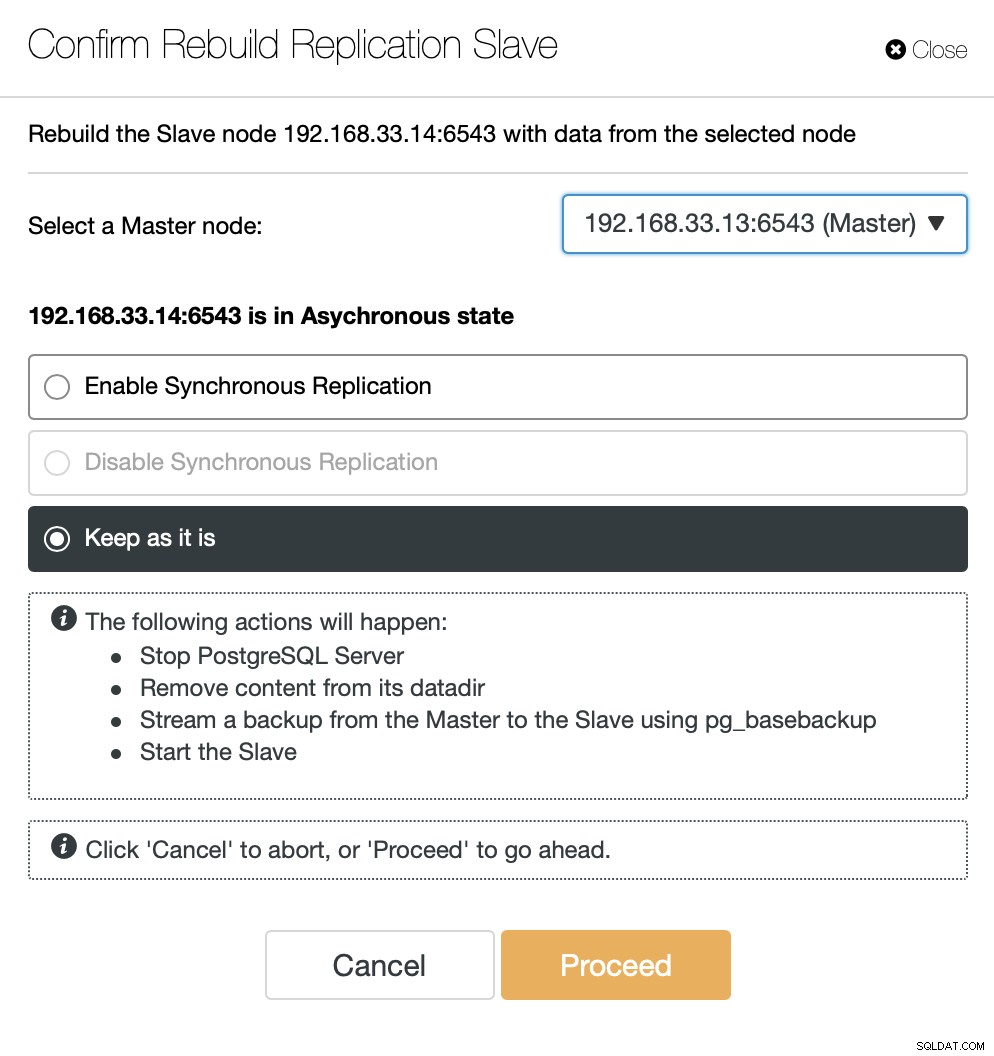
ClusterControl vil streame backup fra den nye primære server og konfigurere replikeringen.
Konklusion
Auto failover er en vigtig del af enhver Moodle produktionsdatabase. Det kan reducere nedetiden, når en server går ned, men også ved udførelse af almindelige vedligeholdelsesopgaver eller migreringer. Det er vigtigt at få det rigtigt, da det er vigtigt for failover-softwaren at tage de rigtige beslutninger.