Vil du lære at designe et databasesystem og kortlægge en forretningsproces til en datamodel? Så er dette indlæg noget for dig.
I denne artikel kan du se, hvordan du designer et simpelt databaseskema til en rekrutteringsvirksomhed. Efter at have læst denne vejledning, vil du være i stand til at forstå, hvordan databaseskemaer er designet til applikationer i den virkelige verden.
Rekrutteringssystemets forretningsproces
Før du designer en database eller datamodel, er det bydende nødvendigt at forstå den grundlæggende forretningsproces for det pågældende system. Databaseskemaet, vi laver, er til et imaginært rekrutteringsfirma eller -team. Lad os først se de trin, der er involveret i at ansætte nye medarbejdere:
- Virksomheder kontakter rekrutteringsbureauer for at ansætte på deres vegne. I nogle tilfælde rekrutterer virksomheder medarbejdere direkte.
- Den person, der er ansvarlig for rekruttering, starter rekrutteringsprocessen. Denne proces kan have flere trin, såsom den indledende screening, en skriftlig test, den første samtale, den opfølgende samtale, den faktiske ansættelsesbeslutning osv.
- Når rekrutteringsmedarbejderne er blevet enige om en bestemt proces – og dette kan ændre sig afhængigt af kunden, virksomheden eller det pågældende job – opslås den ledige stilling på forskellige platforme.
- Ansøgere begynder at søge jobbet.
- Ansøgerne optages på listen og inviteres til en test eller indledende samtale.
- Ansøgerne møder op til testen/interviewet.
- Testerne bedømmes af rekrutteringsmedarbejderne. I nogle tilfælde videresendes prøver til specialister til karaktergivning.
- Ansøgers interviews bedømmes af en eller flere rekrutterere.
- Ansøgere vurderes på baggrund af tests og interviews.
- Beslutningen om ansættelse er truffet.
Et rekrutteringssystem-databaseskema
I lyset af den førnævnte proces er vores databaseskema opdelt i fem emneområder:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
Vi gennemgår hvert af disse områder i detaljer i den rækkefølge, de er anført. Nedenfor kan du se hele datamodellen.
Proces
Proceskategorien indeholder information relateret til rekrutteringsprocesserne. Den indeholder tre tabeller:process , step , og process_step . Vi vil se på hver enkelt.
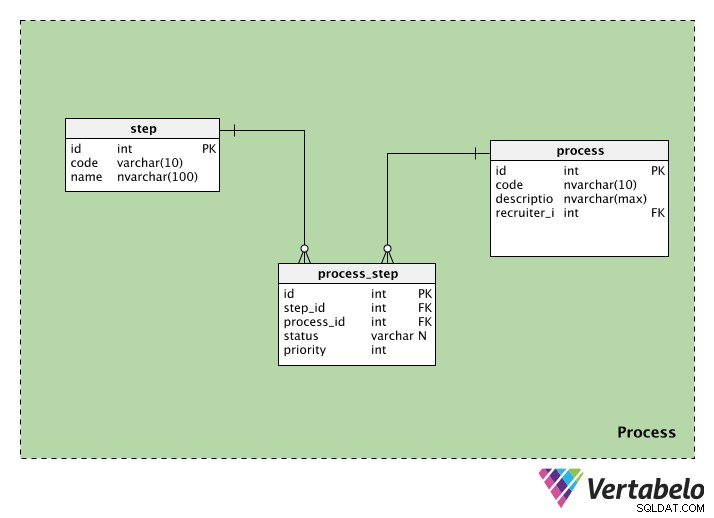
process tabel gemmer oplysninger om hver rekrutteringsproces. Hver proces vil have et specielt id, en kode og en description af den proces. Vi har også recruiter_id af den person, der sætter processen i gang.
step tabel indeholder oplysninger om de trin, der er fulgt i hele rekrutteringsprocessen. Hvert trin har et id og en code navn. Navnekolonnen kan have værdier som "indledende screening", "skriftlig test", "HR-samtale" osv.
Da en proces kan have flere trin, og et trin kan være en del af mange processer, har vi brug for en opslagstabel. process_step tabel indeholder oplysninger om hvert trin (i step_id ) og den proces, den tilhører (i process_id ). Vi har også en status, som fortæller os status for det trin i den proces; dette kan være NULL, hvis trinnet ikke er startet endnu. Endelig har vi en priority , som fortæller os, hvilken rækkefølge trinene skal udføres i. Trinene med den højeste priority værdi vil blive udført først.
Jobs
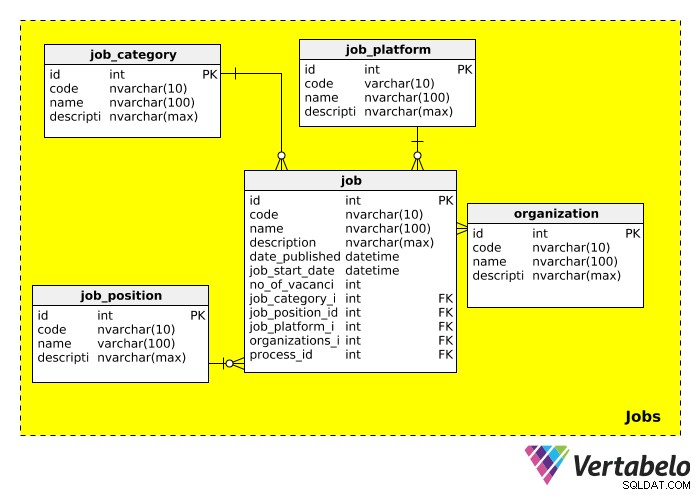
Dernæst har vi Jobs fagområde, som gemmer al information relateret til det eller de job, vi rekrutterer til. Skemaet for denne kategori ser således ud:
Lad os forklare hver af tabellerne i detaljer.
job_category tabel beskriver i store træk typen af job. Vi kunne forvente at se jobkategorier som "IT", "ledelse", "økonomi", "uddannelse" osv.
job_position tabel indeholder den faktiske stillingsbetegnelse. Da én titel kan annonceres for flere jobs (f.eks. "IT-chef", "salgschef"), har vi oprettet en separat tabel for jobstillinger. Vi kunne forvente at se værdier som "IT Team Lead", "Vice President" og "Manager" i denne tabel.
job_platform tabel refererer til det medie, der bruges til at annoncere jobåbningen. For eksempel kan et job slås op på Facebook, en online jobtavle eller i en lokal avis. Et link til det pågældende jobopslag kan tilføjes i description Mark.
organization tabel gemmer oplysninger om alle de virksomheder, der nogensinde har brugt denne database som en del af deres ansættelsesproces. Denne tabel er naturligvis vigtig, når der skal rekrutteres til en anden virksomhed.
Den sidste tabel i dette emneområde, job , indeholder den egentlige jobbeskrivelse. De fleste af egenskaberne er selvforklarende. Vi skal bemærke, at denne tabel har mange fremmednøgler, hvilket betyder, at den kan bruges til at slå op i kategorien, stillingen, platformen, ansættelsesorganisationen og rekrutteringsprocessen relateret til den pågældende jobåbning.
Ansøgning, ansøger og dokumenter
Den tredje del af skemaet består af tabellerne, der gemmer oplysninger om jobansøgere, deres ansøgninger og eventuelle dokumenter, der følger med ansøgningerne.
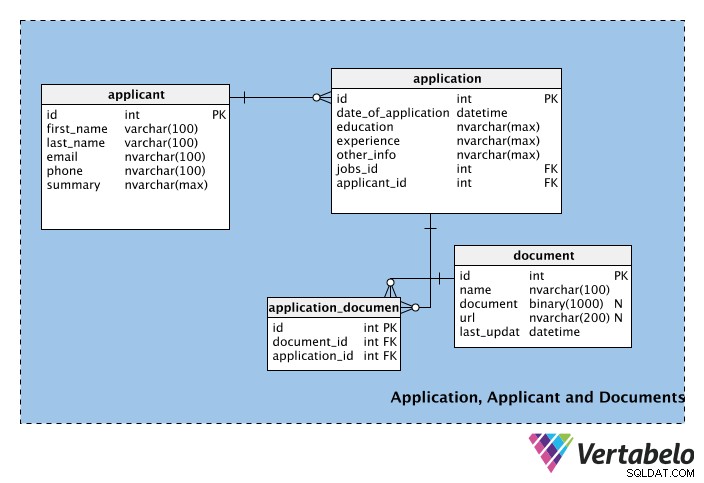
Den første tabel, applicant , gemmer ansøgeres personlige oplysninger, såsom deres fornavn, efternavn, e-mail, telefonnummer osv. Opsummeringsfeltet kan bruges til at gemme ansøgerens korte profil (dvs. et afsnit).
Den næste tabel indeholder oplysninger for hver application , inklusive dens dato. Tabellen indeholder også experience og education kolonner. Disse kolonner kan være en del af applicant tabel, men en ansøger ønsker måske eller måske ikke at vise en bestemt uddannelseskvalifikation eller joberfaring på hver ansøgning, de indsender. Derfor er disse kolonner en del af application bord. other_info kolonne gemmer alle andre applikationsrelaterede oplysninger. I application tabel, jobs_id og ansøger_id er fremmednøgler fra henholdsvis job- og ansøgertabellerne.
Da der kan være flere ansøgninger for hvert job, men hver ansøgning kun er for ét job, vil der være en en-til-mange-relation mellem jobs og applications tabeller. På samme måde kan én ansøger indsende flere ansøgninger (dvs. til forskellige job), men hver ansøgning er kun fra én deltager; vi har implementeret endnu et en-til-mange forhold mellem applicants og applications tabeller til at håndtere dette.
document tabel administrerer de støttedokumenter, som ansøgere kan vedlægge deres ansøgning. Disse kan være CV'er, CV'er, referencebreve, følgebreve osv. Bemærk, at denne tabel har en binær kolonne med navnet dokument, som vil gemme filen i binært format. Et link til dokumentet kan gemmes i url Mark; navnekolonnen gemmer navnet på dokumentet og last_update angiver den seneste version uploadet af ansøgeren. Bemærk, at både document og url er nullbare; ingen af dem er obligatoriske, og en ansøger kan vælge at bruge den ene eller begge metoder til at tilføje oplysninger til deres ansøgning.
Ikke alle ansøgninger vil have et dokument vedhæftet. Et dokument kan vedhæftes flere ansøgninger, og en ansøgning kan have flere støttedokumenter. Det betyder, at der er et mange-til-mange-forhold mellem application og document tabeller. For at administrere denne relation skal du bruge opslagstabellen application_document er blevet oprettet.
Tests og interviews
Nu går vi videre til tabellerne, der gemmer information om testene og interviewene i forbindelse med rekrutteringsprocessen.
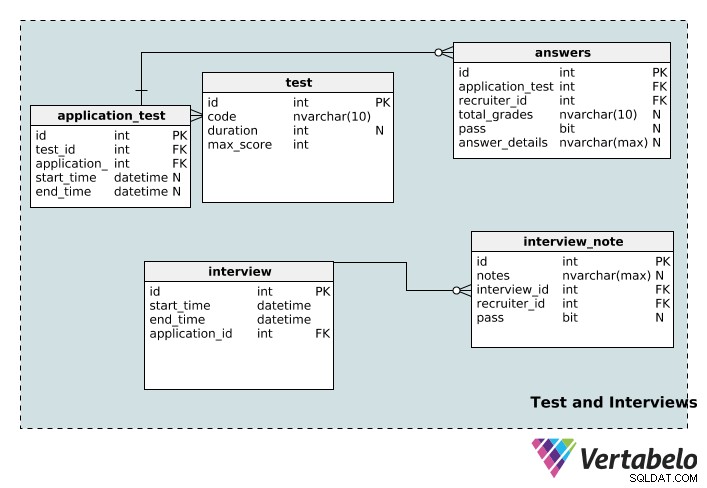
test tabel gemmer testdetaljer inklusive dens unikke id , code navn, dets duration i minutter, og maximum score muligt for den prøve.
En applikation kan tilknyttes flere tests, og en test kan associeres med flere applikationer. Endnu en gang har vi en opslagstabel til at implementere denne relation:application_test . start_time og end_time kolonner er nullbare, da en test muligvis ikke har nogen specifik varighed, starttidspunkt eller sluttidspunkt.
En test kan bedømmes af flere rekrutterere, og en rekrutterer kan bedømme flere tests. answers table er bordet, der gør dette muligt. total_grades kolonnen registrerer, hvor godt kandidaten klarede sig i testen, og bestået kolonne angiver blot, om denne person bestod eller ikke bestod. Specifikt for hver enkelt test er registreret i answer_details kolonne. Bemærk, at disse tre kolonner kan nulstilles; en ansøgningstest kan blive tildelt en rekrutterer, der endnu ikke har bedømt den. Desuden kan en rekrutterer få tildelt en test, før den rent faktisk tages.
interview tabel gemmer grundlæggende information (start_time , end_time , et unikt id , og den relevante application_id ) for hvert interview. Én samtale kan kun knyttes til én ansøgning. På den anden side kan en ansøgning have flere samtaler. Derfor eksisterer der et en-til-mange forhold mellem ansøgnings- og interviewtabellen.
Et interview kan udføres af flere anmeldere, og en anmelder kan tage flere interviews. Det er endnu et mange-til-mange forhold, så vi har oprettet opslagstabellen interview_note . Den gemmer information om interviewet (i interview_id ), rekruttereren (i recruiter_id ), og rekruttererens notater om interviewet. Rekrutterere kan også registrere, om ansøgeren har bestået interviewet i bestå-kolonnen, som er nul.
Rekrutterers ansøgningsevaluering og status
Den sidste del af vores rekrutteringsmodel gemmer oplysninger om rekrutterere, ansøgningsstatusser og ansøgningsevalueringer.
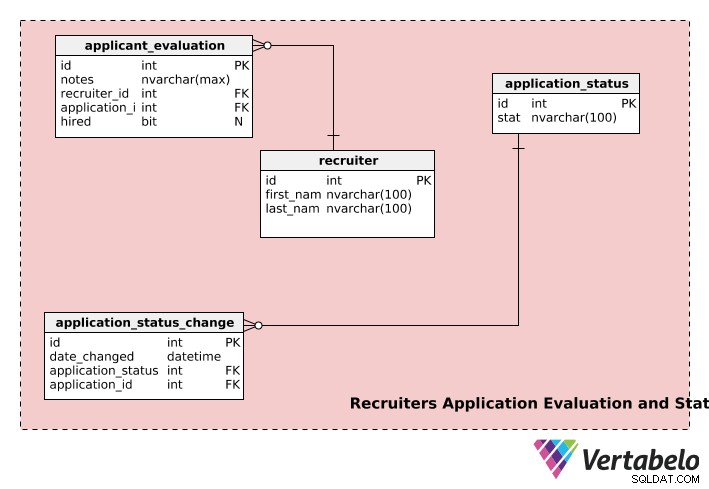
recruiters tabel gemmer hver rekrutters first_name , last_name , og unikt id nummer.
application_evaluation tabel indeholder oplysninger om ansøgningsevalueringer. Ud over application_id og recruiter_id , den indeholder recruiters feedback (i notes ) og den endelige ansættelsesbeslutning, hvis nogen, i hired . Én ansøgning kan evalueres af flere rekrutterere, og én rekrutterer kan evaluere flere ansøgninger, så både recruiter og application tabellen har en en-til-mange-relation med application_evaluation bord.
En ansøgning kan gennemgå flere faser under ansættelsesprocessen, f.eks. "ikke indsendt", "under gennemgang", "afventer afgørelse", "beslutning truffet" osv. En ansøgning vil have status som "ikke_indsendt", når brugeren har startet en ansøgning, men ikke har indsendt den, som rekrutteringsmedarbejderne kan gennemgå. Når ansøgningen er indsendt, ændres status til "under behandling" og så videre. application_status tabel bruges til at gemme sådanne oplysninger.
application_status_change tabel bruges til at vedligeholde statusændringer for alle indsendte ansøgninger. date_changed kolonne gemmer datoen for statusændringen. Denne tabel kan være praktisk, hvis du ønsker at analysere behandlingstiden for hvert trin af forskellige applikationer. Desuden kan status for en bestemt kolonne hentes ved hjælp af application_id kolonne fra application_status_change bord.
En simpel rekrutteringssag
Lad os se, hvordan vores database kan hjælpe rekrutteringsprocessen.
Antag, at en virksomhed har tildelt dig at ansætte en it-chef med programmeringserfaring. Vores database kan hjælpe os med at ansætte en sådan person ved at udføre følgende trin:
- Det første trin er at starte en ny ansættelsesproces. For at gøre det indtastes data i
processogsteptabeller. En rekrutterer kan tilføje så mange trin, som de har brug for. - Under ovenstående opgave kan rekruttereren oprette et nyt job og indtaste detaljerne i
job,job_category,job_positionogorganizationtabeller. Til sidst vil en stillingsannonce blive placeret på en af platformene, der er gemt ijob_platformtabel. - Derefter vil ansøgere oprette en profil ved at indsende deres data til
applicantbord. Derefter starter de en ny applikation ved at indtaste flere data iapplicationtabel. - Ansøgere kan også vedhæfte dokumenter til deres ansøgninger. Disse data vil blive gemt i
documentogapplication_documenttabeller. - Hvis en bruger ønsker at ansøge mere end ét job, gentager de trin 3 og 4.
- Når ansøgningen er indsendt, vil status for ansøgningen blive sat til "indsendt" (eller et andet statusnavn valgt af rekruttereren).
- Rekruttereren vil evaluere ansøgningen og indtaste deres feedback i
application_evaluationbord. På dette stadium vil den lejede kolonne ikke indeholde nogen information. - Når der er modtaget et tilstrækkeligt antal ansøgninger, vil rekruttereren udføre det næste trin vist i
process_steptabel. - Hvis næste trin er at administrere en form for test, vil rekruttereren oprette en test ved at tilføje data til
testtabel. - Testene, der blev oprettet i trin 9, vil blive tildelt en bestemt applikation. De oplysninger, der tildeler hver test til hver applikation, vil blive gemt i
application_testbord. Bemærk, at under hvert trin vil status for applikationen blive ved med at ændre sig. Dette vil blive registreret iapplication_status_changetabel. - Når ansøgeren har gennemført testen, vil karaktererne for hver ansøgningsprøve blive markeret af rekruttereren og indtastet i
answertabel. - Når testen er taget, er det næste trin fra
process_steptabel vil blive udført. Lad os sige, at næste trin er interviewet. - Interviewdataene vil blive indtastet i
interviewbord. Rekruttereren vil indtaste sine kommentarer og sige, om personen bestod interviewet eller ej. Dette vil blive gemt iinterview_notetabel. - Hvis
processtabel indeholder yderligere interview- og testtrin, de vil blive udført, indtil det sidste trin er nået. - Det sidste trin i
process_steptabellen er normalt ansættelsesbeslutningen. Hvis ansøgeren består deres tests og interviews, og virksomheden beslutter at ansætte dem, indtastes data i ansættelseskolonnen iapplication_evaluationbord og personen er ansat.
Hvad synes du om vores datamodel for rekrutteringssystem?
I denne artikel så vi, hvordan man laver et meget simpelt databaseskema til et rekrutteringssystem. Vi inddelte skemaet i fire kategorier og forklarede derefter hver af dem i detaljer. Til sidst kørte vi en use case for at vise, at vores skema faktisk kan hjælpe med at rekruttere en medarbejder.
Databasedesignjob blomstrer. Vil du tilføje færdigheder til din database? Uanset om du er en nybegynder, der ønsker at lære det grundlæggende i SQL, eller en erfaren professionel, der ønsker at forgrene sig til at oprette tabeller i SQL | Interaktivt kursus | Vertabelo Academy" target="_blank">databasedesign, tjek LearnSQL.coms kurser i eget tempo.