Jeg skrev et indlæg for nylig om DISTINCT og GROUP BY. Det var en sammenligning, der viste, at GROUP BY generelt er en bedre mulighed end DISTINCT. Det er på et andet websted, men sørg for at vende tilbage til sqlperformance.com lige efter...
En af de forespørgselssammenligninger, som jeg viste i det indlæg, var mellem en GROUP BY og DISTINCT for en underforespørgsel, hvilket viser, at DISTINCT er meget langsommere, fordi den skal hente produktnavnet for hver række i salgstabellen, snarere end blot for hvert andet produkt-id. Dette er ganske tydeligt fra forespørgselsplanerne, hvor du kan se, at i den første forespørgsel opererer Aggregate på data fra kun én tabel i stedet for på resultaterne af joinforbindelsen. Åh, og begge forespørgsler giver de samme 266 rækker.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

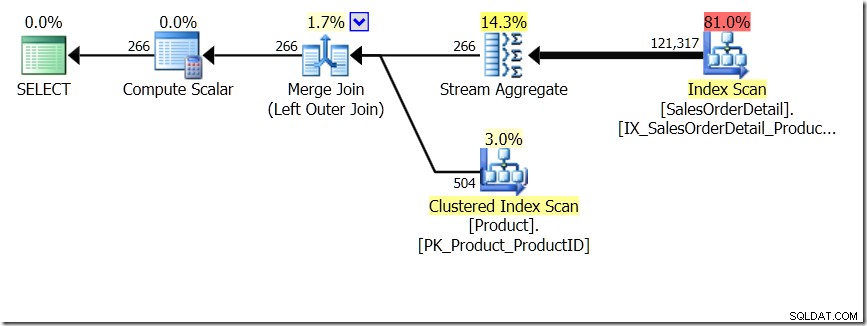
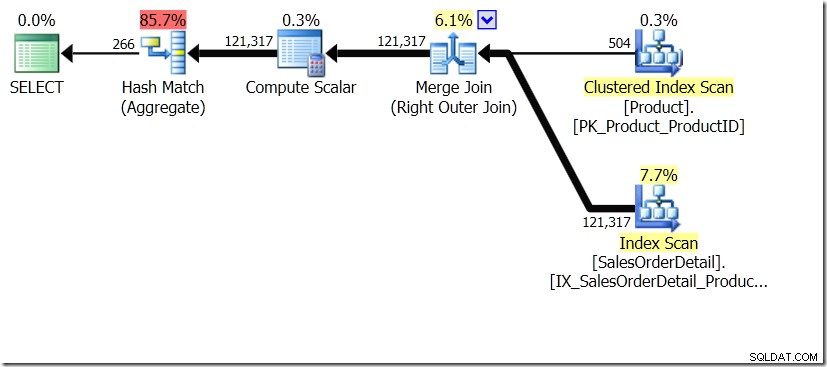
Nu er det blevet påpeget, herunder af Adam Machanic (@adammachanic) i et tweet, der refererer til Aarons indlæg om GROUP BY v DISTINCT, at de to forespørgsler er væsentligt forskellige, at man faktisk beder om sættet af distinkte kombinationer på resultaterne af underforespørgsel, i stedet for at køre underforespørgslen på tværs af de forskellige værdier, der sendes ind. Det er det, vi ser i planen, og er grunden til, at ydeevnen er så anderledes.
Sagen er, at vi alle ville antage, at resultaterne vil være identiske.
Men det er en antagelse, og den er ikke god.
Jeg vil et øjeblik forestille mig, at Query Optimizer har fundet på en anden plan. Jeg brugte tip til dette, men som du ved, kan Query Optimizer vælge at oprette planer i alle slags former af alle mulige årsager.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
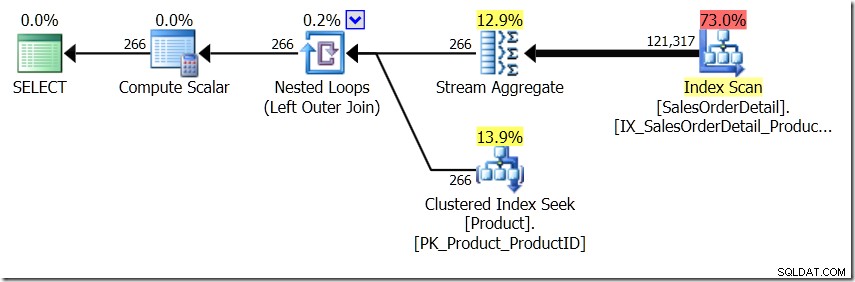
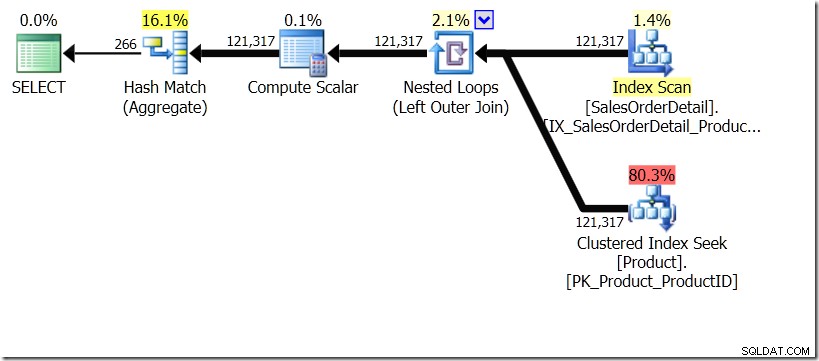
I denne situation laver vi enten 266 søgninger i produkttabellen, en for hvert andet produkt-id, som vi er interesseret i, eller 121.317 søgninger. Så hvis vi tænker på et bestemt produkt-ID, ved vi, at vi får et enkelt navn tilbage fra det første. Og vi antager, at vi får et enkelt navn tilbage for det produkt-id, selvom vi skal bede om det hundrede gange. Vi antager bare, at vi får de samme resultater tilbage.
Men hvad hvis vi ikke gør det?
Dette lyder som en ting med isolationsniveau, så lad os bruge NOLOCK, når vi rammer produkttabellen. Og lad os køre (i et andet vindue) et script for at ændre teksten i navnekolonnerne. Jeg vil gøre det igen og igen for at prøve at få nogle af ændringerne imellem min forespørgsel.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Nu er mine resultater anderledes. Planerne er de samme (bortset fra antallet af rækker, der kommer ud af Hash Aggregatet i den anden forespørgsel), men mine resultater er anderledes.
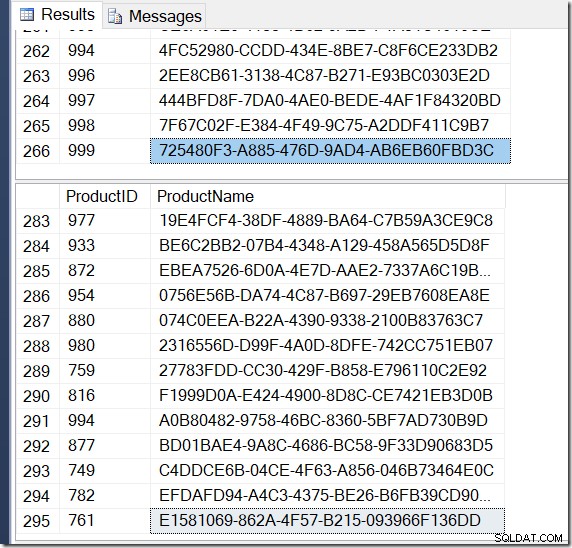
Sikkert nok har jeg flere rækker med DISTINCT, fordi den finder forskellige navneværdier for det samme produkt-ID. Og jeg har ikke nødvendigvis 295 rækker. En anden jeg kører det, får jeg måske 273 eller 300 eller muligvis 121.317.
Det er ikke svært at finde et eksempel på et produkt-id, der viser flere navneværdier, der bekræfter, hvad der foregår.

Det er klart, at for at sikre, at vi ikke kan se disse rækker i resultaterne, skal vi enten IKKE bruge DISTINCT eller også bruge et strengere isolationsniveau.
Sagen er, at selvom jeg nævnte at bruge NOLOCK til dette eksempel, behøvede jeg det ikke. Denne situation opstår selv med READ COMMITTED, som er standardisolationsniveauet på mange SQL Server-systemer.
Ser du, vi har brug for isolationsniveauet REPEATABLE READ for at undgå denne situation, for at holde låsene på hver række, når den er blevet læst. Ellers kan en separat tråd ændre dataene, som vi så.
Men... jeg kan ikke vise dig, at resultaterne er rettet, fordi jeg ikke kunne undgå en dødvande i forespørgslen.
Så lad os ændre betingelserne ved at sikre, at vores anden forespørgsel er et mindre problem. I stedet for at opdatere hele tabellen ad gangen (hvilket alligevel er langt mindre sandsynligt i den virkelige verden), lad os bare opdatere en enkelt række ad gangen.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Nu kan vi stadig demonstrere problemet under et mindre isolationsniveau, såsom READ COMMITTED eller READ UNCOMMITTED (selvom du muligvis skal køre forespørgslen flere gange, hvis du får 266 første gang, fordi chancen for at opdatere en række under forespørgslen er mindre), og nu kan vi demonstrere, at REPEATABLE READ løser det (uanset hvor mange gange vi kører forespørgslen).
GENTAGLIG LÆSning gør, hvad der står på dåsen. Når du har læst en række i en transaktion, er den låst for at sikre, at du kan gentage læsningen og få de samme resultater. De mindre isolationsniveauer fjerner ikke disse låse, før du prøver at ændre dataene. Hvis din forespørgselsplan aldrig behøver at gentage en læsning (som det er tilfældet med formen på vores GROUP BY-planer), så har du ikke brug for GENTAGLIG LÆSNING.
Vi burde uden tvivl altid bruge de højere isolationsniveauer, såsom REPEATABLE READ eller SERIALIZABLE, men det hele handler om at finde ud af, hvad vores systemer har brug for. Disse niveauer kan introducere uønsket låsning, og SNAPSHOT-isolationsniveauer kræver versionering, der også kommer med en pris. For mig synes jeg, det er en afvejning. Hvis jeg beder om en forespørgsel, der kan blive påvirket af ændring af data, skal jeg muligvis hæve isolationsniveauet i et stykke tid.
Ideelt set opdaterer du simpelthen ikke data, der lige er blevet læst, og som måske skal læses igen under forespørgslen, så du ikke behøver GENTAGLIG LÆSNING. Men det er bestemt værd at forstå, hvad der kan ske, og erkende, at dette er den slags scenarie, hvor DISTINCT og GROUP BY måske ikke er det samme.
@rob_farley