Som konsulent, der arbejder med SQL Server, bliver jeg mange gange bedt om at se på en server, der ser ud til at have problemer med ydeevnen. Mens jeg udfører triage på serveren, stiller jeg visse spørgsmål, såsom:hvad er din normale CPU-udnyttelse, hvad er dine gennemsnitlige diskforsinkelser, hvad er din normale hukommelsesudnyttelse og så videre. Svaret er normalt, "vi ved det ikke" eller "vi fanger ikke disse oplysninger regelmæssigt." Ikke at have en nylig baseline gør det meget svært at vide, hvordan unormal adfærd ser ud. Hvis du ikke ved, hvad normal adfærd er, hvordan ved du så med sikkerhed, om tingene er bedre eller værre? Jeg bruger ofte udtrykkene, "hvis du ikke overvåger det, kan du ikke måle det," og "hvis du ikke måler det, kan du ikke styre det."
Fra et overvågningsperspektiv bør organisationer som minimum overvåge for mislykkede opgaver såsom sikkerhedskopiering, indeksvedligeholdelse, DBCC CHECKDB og alle andre vigtige opgaver. Det er nemt at opsætte fejlmeddelelser for disse; men du skal også have en proces på plads for at sikre, at jobs kører som forventet. Jeg har set job, der bliver hængende og aldrig fuldføres. En fejlmeddelelse vil ikke udløse en alarm, da jobbet aldrig lykkes eller mislykkes.
Fra en præstationsbaseline er der adskillige nøglemålinger, der bør fanges. Jeg har oprettet en proces, som jeg bruger med klienter, der opfanger nøglemålinger på regelmæssig basis og gemmer disse værdier i en brugerdatabase. Min proces er enkel:en dedikeret database med lagrede procedurer, der bruger almindelige scripts, der indsætter resultatsættene i tabeller. Jeg har SQL Agent-job til at køre de lagrede procedurer med regelmæssige intervaller og et oprydningsscript til at rense data, der er ældre end X dage. De metrics, jeg altid fanger, omfatter:
Forventet sidelevetid :PLE er sandsynligvis en af de bedste måder at måle, om dit system er under internt hukommelsestryk. De fleste systemer har PLE-værdier, der svinger under normale arbejdsbelastninger. Jeg kan godt lide at trende disse værdier for at vide, hvad minimums-, gennemsnits- og maksimumværdierne er. Jeg kan godt lide at prøve at forstå, hvad der fik PLE til at falde på bestemte tidspunkter af dagen for at se, om disse processer kan justeres. Mange gange laver nogen en bordscanning og skyller bufferpuljen. At være i stand til at indeksere disse forespørgsler korrekt kan hjælpe. Bare sørg for, at du overvåger den rigtige PLE-tæller – se her .
CPU-udnyttelse :At have en basislinje for CPU-udnyttelse giver dig besked, hvis dit system pludselig er under CPU-tryk. Ofte, når en bruger klager over ydeevneproblemer, vil de observere, at CPU ser høj ud. For eksempel, hvis CPU'en svæver omkring 80%, kan de finde det bekymrende, men hvis CPU'en også var 80% på samme tid de foregående uger, hvor der ikke blev rapporteret nogen problemer, er sandsynligheden for, at CPU er problemet, meget lav. Trending CPU er ikke kun til at fange, når CPU'en stiger og forbliver på en konstant høj værdi. Jeg har adskillige historier om, da jeg blev bragt ind i en alvorlig konferencebro, fordi der var et problem med en ansøgning. Som DBA bar jeg hatten med "Default Blame Acceptor." Da applikationsteamet sagde, at der var et problem med databasen, var det op til mig at bevise, at det ikke var det, databaseserveren var skyldig, indtil det var bevist uskyldigt. Jeg husker tydeligt en hændelse, hvor applikationsteamet var overbevist om, at databaseserveren havde problemer, fordi brugerne ikke kunne oprette forbindelse. De havde læst på internettet, at SQL Server kunne lide af "thread pool" sult, hvis den nægtede forbindelser. Jeg hoppede på serveren og begyndte at se på ressourcer, og hvilke processer der kørte i øjeblikket. Inden for et par minutter rapporterede jeg tilbage, at den pågældende server kedede sig meget. Baseret på vores baseline-metrics var CPU typisk 60 %, og den var inaktiv omkring 20 %, sidelevetiden var mærkbart højere end normalt, og der skete ingen låsning eller blokering, I/O så godt ud, ingen fejl i nogen logfiler, og sessionstællingerne var omkring 1/3 af deres normale antal. Jeg lavede så kommentaren:"Det ser ud til, at brugerne ikke engang når databaseserveren." Det fik netværksfolkenes opmærksomhed, og de indså, at en ændring, de lavede på belastningsbalanceren, ikke fungerede korrekt, og de fandt ud af, at over 50 % af forbindelserne blev dirigeret forkert og ikke nåede databaseserveren. Havde jeg ikke vidst, hvad udgangspunktet var, ville det have taget os meget længere tid at nå frem til løsningen.
Disk I/O :Det er meget vigtigt at fange diskmetrics. DMV sys.dm_io_virtual_file_stats er kumulativ siden sidste servergenstart. Indfangning af dine I/O-forsinkelser over et tidsinterval vil give dig en basislinje for, hvad der er normalt i det pågældende tidsrum. At stole på den kumulative værdi kan give dig skæve data fra aktiviteter efter arbejdstid eller lange perioder, hvor systemet var inaktivt. Paul diskuterede det her .
Databasefilstørrelser :At have en fortegnelse over dine databaser, der inkluderer filstørrelse, brugt størrelse, ledig plads og mere, kan hjælpe dig med at forudsige databasevækst. Ofte bliver jeg bedt om at forudsige, hvor meget lagerplads der vil være nødvendig for en databaseserver i løbet af det kommende år. Uden at kende den ugentlige eller månedlige væksttrend, har jeg ingen mulighed for intelligent at komme med et tal. Når jeg er begyndt at spore disse værdier, kan jeg trende dette ordentligt. Udover trending kunne jeg også finde, hvornår der var uventet databasevækst. Når jeg ser uventet vækst og undersøger det, opdager jeg normalt, at nogen enten har duplikeret en tabel for at lave nogle test (ja, i produktion!) eller lavede en anden engangsproces. At spore denne type data og være i stand til at reagere, når der opstår uregelmæssigheder, hjælper med at vise, at du er proaktiv og holder øje med dine systemer.
Ventestatistik :Overvågning af ventestatistikker kan hjælpe dig med at finde ud af årsagen til visse ydeevneproblemer. Mange nye DBA'er bliver bekymrede, når de først begynder at undersøge ventestatistikker og ikke indser, at ventetider altid forekommer, og det er bare den måde, SQL Servers planlægningssystem fungerer. Der er også en masse ventetider, der kan betragtes som godartede, eller for det meste harmløse. Paul Randal udelukker disse for det meste harmløse ventetider i sit populære ventestatistikscript. Paul har også bygget et stort bibliotek af de forskellige ventetyper og låseklasser med beskrivelser og anden information om fejlfinding af ventetider og låse.
Jeg har dokumenteret min dataindsamlingsproces, og du kan finde koden på min blog . Afhængigt af situationen og typen af problemer, en klient måtte have, vil jeg måske også indfange yderligere metrics. Glenn Berry bloggede om en proces, han sammensatte, og som fanger det gennemsnitlige antal opgaver, det gennemsnitlige antal opgaver, der kan køres, det gennemsnitlige antal afventende I/O-tal, CPU-udnyttelsen af SQL Server-processen og den gennemsnitlige forventede sidelevetid på tværs af alle NUMA-noder. En hurtig internetsøgning vil vise adskillige andre dataindsamlingsprocesser, som folk har delt, selv SQL Server Tiger-teamet har en proces, der bruger T-SQL og PowerShell.
Brug af en tilpasset database og opbygning af din egen dataindsamlingspakke er en gyldig løsning til at indfange en baseline, men de fleste af os er ikke i gang med at bygge komplette SQL Server-overvågningsløsninger. Der er meget mere, der ville være nyttigt at fange, ting som langvarige forespørgsler, topforespørgsler og lagrede procedurer baseret på hukommelse, I/O og CPU, deadlocks, indeksfragmentering, transaktioner pr. sekund og meget mere. Til det anbefaler jeg altid, at kunder køber et tredjepartsovervågningsværktøj. Disse leverandører har specialiseret sig i at holde sig opdateret på de nyeste trends og funktioner i SQL Server, så du kan fokusere din tid på at sikre, at SQL Server er så stabil og hurtig som muligt.
Løsninger som SQL Sentry (til SQL Server) og DB Sentry (til Azure SQL Database) fanger alle disse metrics for dig og giver dig mulighed for nemt at oprette forskellige basislinjer. Du kan have en normal basislinje, månedsafslutning, kvartalsudgang og mere. Du kan derefter anvende basislinjen og se visuelt, hvordan tingene er anderledes. Endnu vigtigere er det, at du kan konfigurere et hvilket som helst antal advarsler for forskellige forhold og få besked, når metrics overskrider dine tærskler.
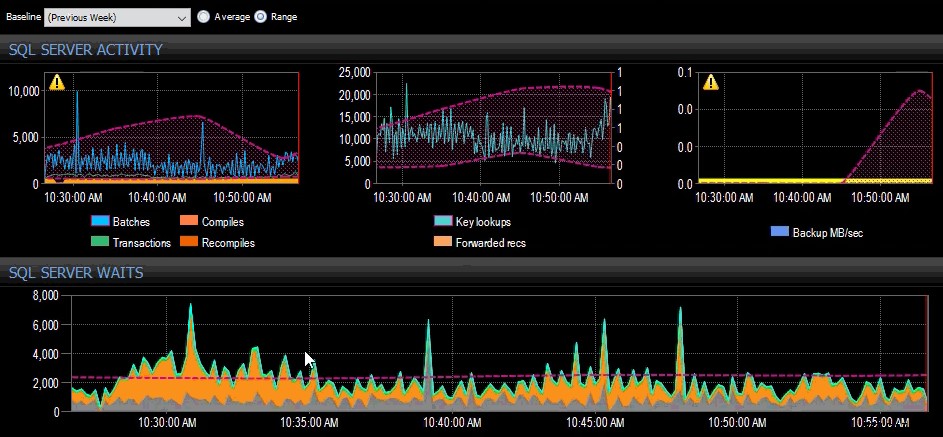 Sidste uges basislinje blev anvendt på adskillige SQL Server-metrics på SQL Sentry-dashboardet.
Sidste uges basislinje blev anvendt på adskillige SQL Server-metrics på SQL Sentry-dashboardet.
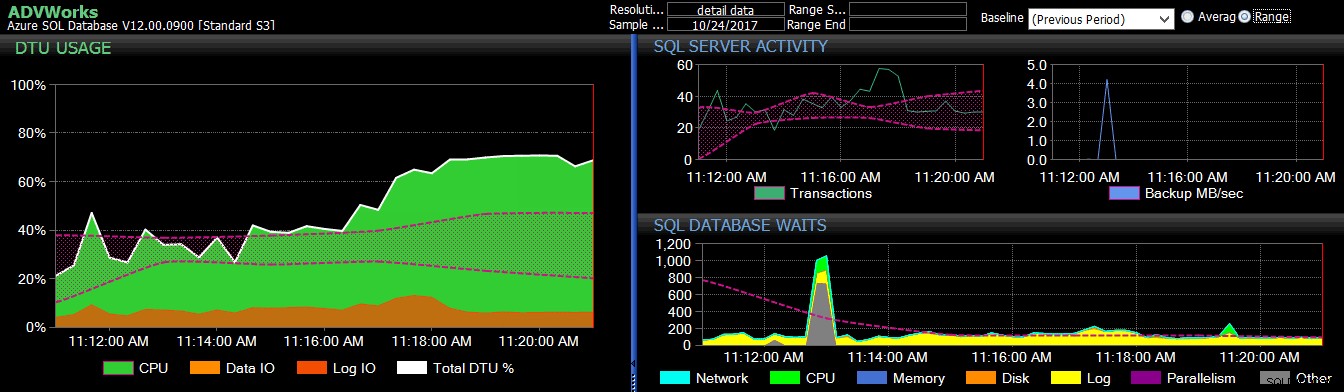 Den forrige periodes basislinje blev anvendt på flere Azure SQL Database-metrics på DB Sentry-dashboardet.
Den forrige periodes basislinje blev anvendt på flere Azure SQL Database-metrics på DB Sentry-dashboardet.
For mere information om basislinjer i SentryOne, se disse indlæg over på deres teamblog eller denne 2-minutters tirsdagsvideo . Interesseret i at downloade en prøveversion? Der har de også dækket dig .