Nogle gange er det svært at administrere en stor mængde data i en virksomhed, især med den eksponentielle stigning i dataanalyse og IoT-brug. Afhængigt af størrelsen kan denne mængde data påvirke ydeevnen af dine systemer, og du bliver sandsynligvis nødt til at skalere dine databaser eller finde en måde at løse dette på. Der er forskellige måder at skalere dine PostgreSQL-databaser på, og en af dem er Sharding. I denne blog vil vi se, hvad Sharding er, og hvordan man konfigurerer det i PostgreSQL ved hjælp af ClusterControl for at forenkle opgaven.
Hvad er Sharding?
Sharding er handlingen med at optimere en database ved at adskille data fra en stor tabel til flere små. Mindre borde er Shards (eller partitioner). Partitionering og Sharding er lignende begreber. Den største forskel er, at sharding indebærer, at dataene er spredt over flere computere, mens partitionering handler om at gruppere delmængder af data i en enkelt databaseinstans.
Der er to typer Sharding:
-
Horisontal deling:Hver ny tabel har det samme skema som den store tabel, men unikke rækker. Det er nyttigt, når forespørgsler har tendens til at returnere en delmængde af rækker, der ofte er grupperet sammen.
-
Lodret deling:Hver ny tabel har et skema, der er en delmængde af den oprindelige tabels skema. Det er nyttigt, når forespørgsler har tendens til kun at returnere et undersæt af kolonner af dataene.
Lad os se et eksempel:
Original tabel
| ID | Navn | Alder | Land |
|---|---|---|---|
| 1 | James Smith | 26 | USA |
| 2 | Mary Johnson | 31 | Tyskland |
| 3 | Robert Williams | 54 | Canada |
| 4 | Jennifer Brown | 47 | Frankrig |
Lodret sønderdeling
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Navn | Alder | ID | Land |
| 1 | James Smith | 26 | 1 | USA |
| 2 | Mary Johnson | 31 | 2 | Tyskland |
| 3 | Robert Williams | 54 | 3 | Canada |
| 4 | Jennifer Brown | 47 | 4 | Frankrig |
Horizontal Sharding
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Navn | Alder | Land | ID | Navn | Alder | Land |
| 1 | James Smith | 26 | USA | 3 | Robert Williams | 54 | Canada |
| 2 | Mary Johnson | 31 | Tyskland | 4 | Jennifer Brown | 47 | Frankrig |
Nu hvor vi har gennemgået nogle Sharding-koncepter, lad os fortsætte til næste trin.
Hvordan installeres en PostgreSQL-klynge?
Vi vil bruge ClusterControl til denne opgave. Hvis du ikke bruger ClusterControl endnu, kan du installere det og implementere eller importere din nuværende PostgreSQL-database ved at vælge "Importer"-indstillingen og følge trinene for at drage fordel af alle ClusterControl-funktionerne såsom sikkerhedskopier, automatisk failover, advarsler, overvågning og mere .
For at udføre en implementering fra ClusterControl skal du blot vælge "Deploy"-indstillingen og følge instruktionerne, der vises.
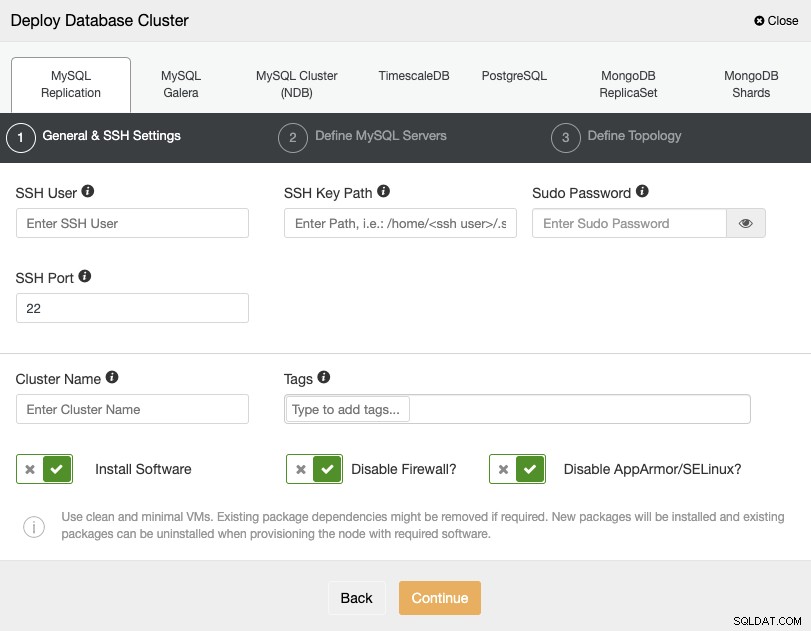
Når du vælger PostgreSQL, skal du angive din bruger, nøgle eller adgangskode og Port for at forbinde med SSH til dine servere. Du kan også tilføje et navn til din nye klynge, og hvis du vil, kan du også bruge ClusterControl til at installere den tilsvarende software og konfigurationer for dig.
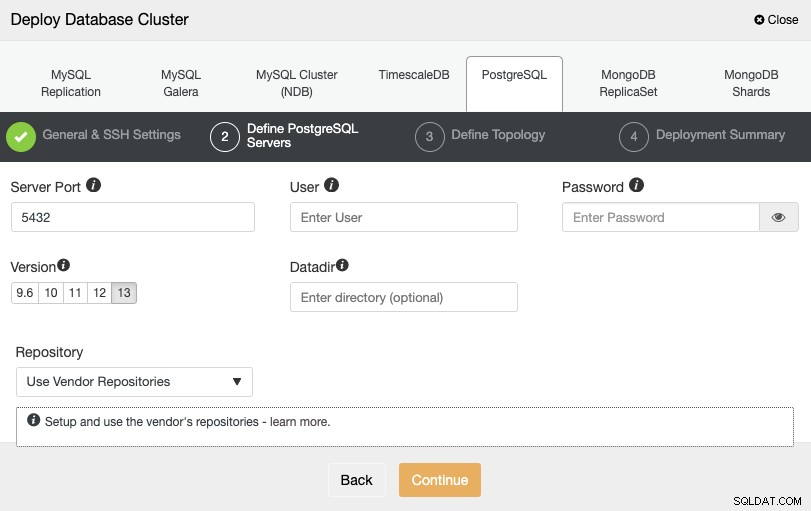
Efter opsætning af SSH-adgangsoplysningerne skal du definere databaselegitimationsoplysningerne , version og datadir (valgfrit). Du kan også angive, hvilket lager der skal bruges.
For det næste trin skal du tilføje dine servere til den klynge, som du vil oprette ved hjælp af IP-adressen eller værtsnavnet.
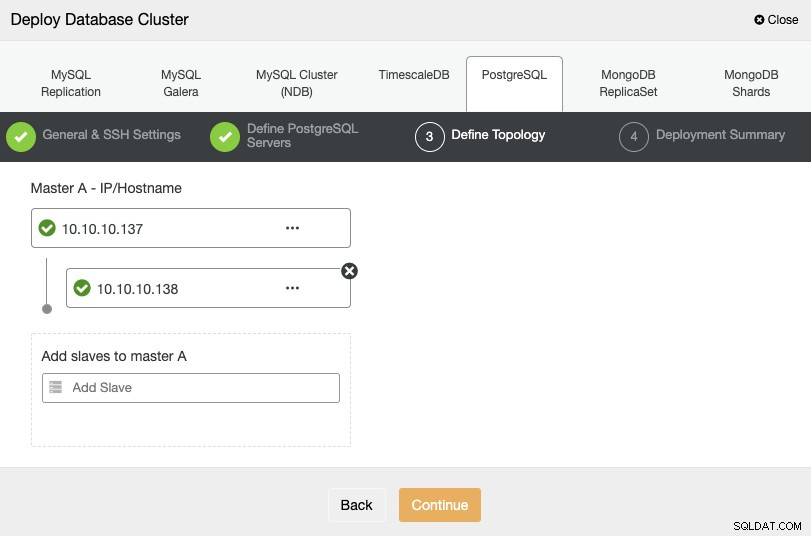
I det sidste trin kan du vælge, om din replikering skal være Synkron eller Asynkron, og tryk så bare på "Deploy".
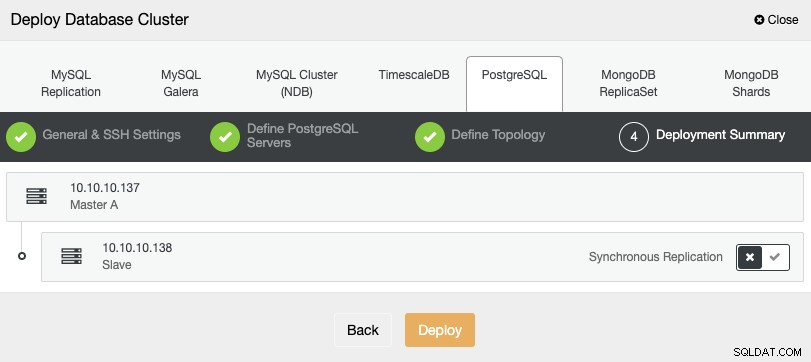
Når opgaven er færdig, vil du se din nye PostgreSQL-klynge i hovedskærmen ClusterControl.

Nu hvor du har oprettet din klynge, kan du udføre flere opgaver på den som at tilføje en load balancer (HAProxy), forbindelsespooler (pgBouncer) eller en ny replika.
Gentag processen for at have mindst to separate PostgreSQL-klynger til at konfigurere Sharding, hvilket er næste trin.
Hvordan konfigureres PostgreSQL Sharding?
Nu vil vi konfigurere Sharding ved hjælp af PostgreSQL-partitioner og Foreign Data Wrapper (FDW). Denne funktionalitet giver PostgreSQL adgang til data gemt på andre servere. Det er en udvidelse tilgængelig som standard i den almindelige PostgreSQL-installation.
Vi vil bruge følgende miljø:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersFor at aktivere FDW-udvidelsen skal du blot køre følgende kommando på din hovedserver, i dette tilfælde Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONLad os nu oprette bordet kunder opdelt efter registreret dato:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);Og følgende partitioner:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Disse partitioner er lokale. Lad os nu indsætte nogle testværdier og kontrollere dem:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Her kan du forespørge på hovedpartitionen for at se alle data:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Eller endda forespørg på den tilsvarende partition:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Som du kan se, blev data indsat i forskellige partitioner i henhold til den registrerede dato. Lad os nu, i fjernknuden, i dette tilfælde Shard2, oprette en anden tabel:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Du skal oprette denne Shard2-server i Shard1 på denne måde:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');Og brugeren til at få adgang til det:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Opret nu den UDENLANDSKE TABEL i Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;Og lad os indsætte data i denne nye fjerntabel fra Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Hvis alt gik fint, skulle du kunne få adgang til dataene fra både Shard1 og Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Det er det. Nu bruger du Sharding i din PostgreSQL-klynge.
Konklusion
Partitionering og Sharding i PostgreSQL er gode funktioner. Det hjælper dig i tilfælde af, at du har brug for at adskille data i en stor tabel for at forbedre ydeevnen, eller endda for at rense data på en nem måde, blandt andre situationer. Et vigtigt punkt, når du bruger Sharding, er at vælge en god shard-nøgle, der fordeler data mellem noderne på den bedste måde. Du kan også bruge ClusterControl til at forenkle PostgreSQL-implementeringen og til at drage fordel af nogle funktioner som overvågning, alarmering, automatisk failover, backup, punkt-i-tidsgendannelse og mere.