Fjernelse og forebyggelse af indeksfragmentering har længe været en del af normal databasevedligeholdelse, ikke kun i SQL Server, men på tværs af mange platforme. Indeksfragmentering påvirker ydeevnen af mange årsager, og de fleste mennesker taler om virkningerne af tilfældige små I/O-blokke, der fysisk kan ske på diskbaseret lager, som noget, der skal undgås. Den generelle bekymring omkring indeksfragmentering er, at den påvirker ydeevnen af scanninger ved at begrænse størrelsen af read-ahead I/O'er. Det er baseret på denne begrænsede forståelse af de problemer, som indeksfragmentering forårsager, at nogle mennesker er begyndt at cirkulere ideen om, at indeksfragmentering ikke betyder noget med Solid State Storage-enheder (SSD'er), og at du bare kan ignorere indeksfragmentering fremover.
Det er dog ikke tilfældet af flere årsager. Denne artikel vil forklare og demonstrere en af disse grunde:at indeksfragmentering kan have en negativ indvirkning på valg af eksekveringsplan for forespørgsler. Dette sker, fordi indeksfragmentering generelt fører til, at et indeks har flere sider (disse ekstra sider kommer fra sideopdeling operationer, som beskrevet i dette indlæg på dette websted), og derfor anses brugen af dette indeks for at have en højere omkostning af SQL Servers forespørgselsoptimering.
Lad os se på et eksempel.
Den første ting, vi skal gøre, er at bygge en passende testdatabase og et datasæt, der skal bruges til at undersøge, hvordan indeksfragmentering kan påvirke valg af forespørgselsplan i SQL Server. Følgende script vil skabe en database med to tabeller med identiske data, en stærkt fragmenteret og en minimalt fragmenteret.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Efter genopbygning af indekset kan vi se på fragmenteringsniveauerne med følgende forespørgsel:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Resultater:

Her kan vi se, at vores GuidHighFragmentation tabellen er 99 % fragmenteret og bruger 31 % mere sideplads end GuidLowFragmentation tabel i databasen, på trods af at de har de samme 7.000.000 rækker data. Hvis vi udfører en grundlæggende aggregeringsforespørgsel mod hver af tabellerne og sammenligner eksekveringsplanerne på en standardinstallation (med standardkonfigurationsmuligheder og -værdier) af SQL Server ved hjælp af SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


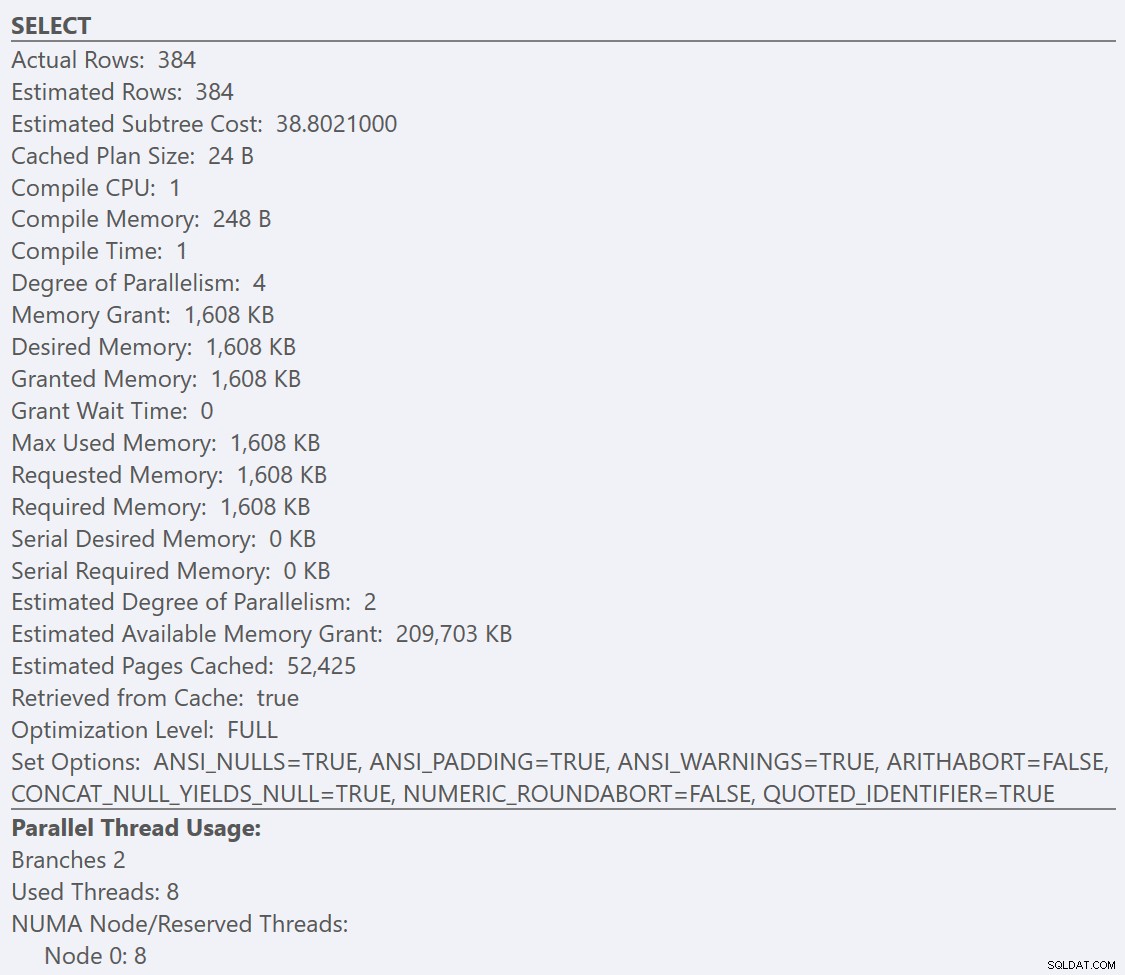

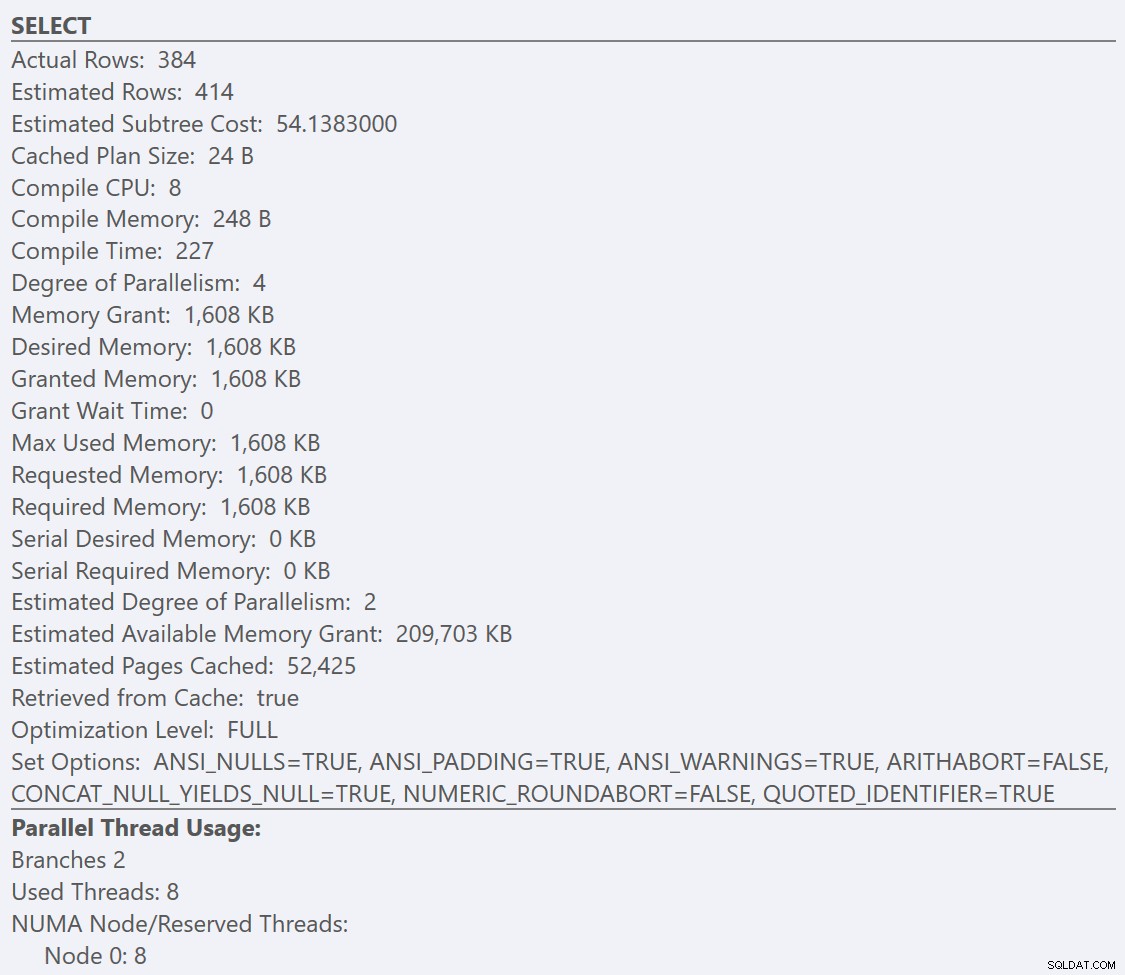
Hvis vi ser på værktøjstip fra SELECT operatør for hver plan, planen for GuidLowFragmentation tabellen har en forespørgselsomkostning på 38,80 (den tredje linje nede fra toppen af værktøjstip) versus en forespørgselspris på 54,14 for planen for GuidHighFragmentation-planen.
Under en standardkonfiguration for SQL Server ender begge disse forespørgsler med at generere en parallel eksekveringsplan, da de estimerede forespørgselsomkostninger er højere end "omkostningstærsklen for parallelisme" sp_configure option standard på 5. Dette skyldes, at forespørgselsoptimeringsværktøjet først producerer en seriel. plan (der kun kan udføres af en enkelt tråd), når planen for en forespørgsel kompileres. Hvis de estimerede omkostninger for den serielle plan overstiger den konfigurerede "omkostningstærskel for parallelisme", genereres en parallel plan i stedet for at cachelagres.
Men hvad nu hvis 'omkostningstærsklen for parallelisme' sp_configure-indstillingen ikke er sat til standarden 5 og er sat højere? Det er en bedste praksis (og en korrekt) at øge denne mulighed fra den lave standard på 5 til et hvilket som helst sted fra 25 til 50 (eller endda meget højere) for at forhindre små forespørgsler i at pådrage sig den ekstra overhead ved at gå parallelt.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Efter at have fulgt retningslinjerne for bedste praksis og øget 'omkostningstærsklen for parallelitet' til 50, resulterer genkørsel af forespørgslerne i den samme eksekveringsplan for GuidHighFragmentation tabellen, men GuidLowFragmentation forespørgselsserieomkostninger, 44,68, er nu under 'omkostningstærsklen for parallelisme'-værdien (husk, at dens anslåede parallelle omkostninger var 38,80), så vi får en seriel eksekveringsplan:
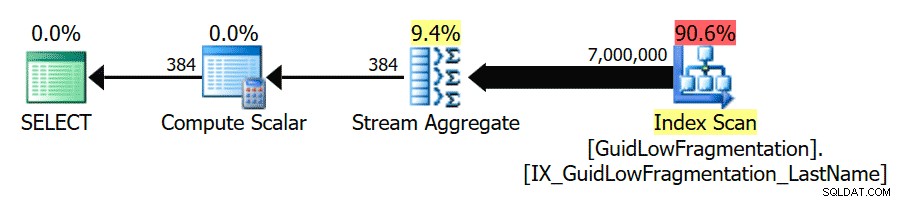
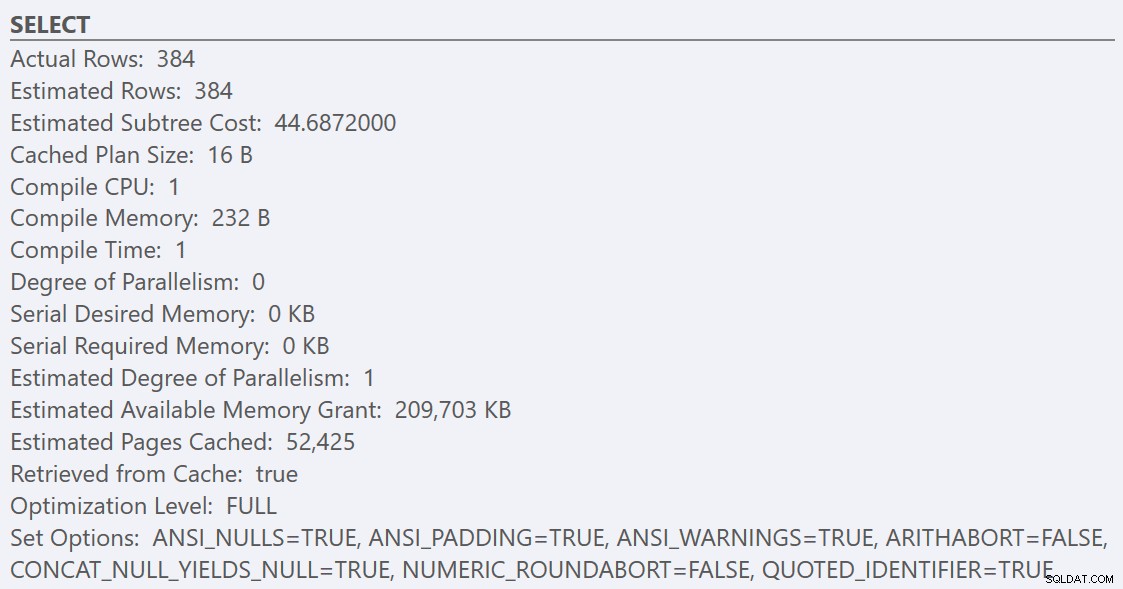
Den ekstra sideplads i GuidHighFragmentation clustered index holdt prisen over best-practice-indstillingen for 'omkostningstærskel for parallelisme' og resulterede i en parallel plan.
Forestil dig nu, at dette var et system, hvor du fulgte best-practice-vejledningen og oprindeligt konfigurerede 'omkostningstærskel for parallelitet' til en værdi på 50. Så fulgte du senere det forkerte råd om bare at ignorere indeksfragmentering helt.
I stedet for at dette er en grundlæggende forespørgsel, er det mere komplekst, men hvis det også bliver udført meget ofte på dit system, og som et resultat af indeksfragmentering, tipper sidetallet omkostningerne over til en parallel plan, vil den bruge mere CPU og påvirke den samlede arbejdsbyrdeydelse som et resultat.
Hvad laver du? Øger du 'omkostningstærsklen for parallelitet', så forespørgslen opretholder en seriel eksekveringsplan? Antyder du forespørgslen med OPTION(MAXDOP 1) og tvinger den bare til en seriel eksekveringsplan?
Husk, at indeksfragmentering sandsynligvis ikke kun påvirker én tabel i din database, nu hvor du ignorerer den fuldstændigt; det er sandsynligt, at mange klyngede og ikke-klyngede indekser er fragmenterede og har et højere antal sider end nødvendigt, så omkostningerne ved mange I/O-operationer stiger som følge af den udbredte indeksfragmentering, hvilket fører til potentielt mange ineffektive forespørgsler planer.
Oversigt
Du kan ikke bare ignorere indeksfragmentering fuldstændigt, som nogle måske vil have dig til at tro. Blandt andre ulemper ved at gøre dette vil de akkumulerede omkostninger ved udførelse af forespørgsler indhente dig, med forespørgselsplanskift, fordi forespørgselsoptimeringsværktøjet er en omkostningsbaseret optimerer og derfor med rette anser disse fragmenterede indekser som dyrere at bruge.
Forespørgslerne og scenariet her er naturligvis konstruerede, men vi har set ændringer i eksekveringsplanen forårsaget af fragmentering i det virkelige liv på klientsystemer.
Du skal sikre dig, at du adresserer indeksfragmentering for de indekser, hvor fragmentering forårsager problemer med arbejdsbelastningens ydeevne, uanset hvilken hardware du bruger.