Hvad gør indeksering?
Indeksering er måden at få en uordnet tabel i en rækkefølge, der vil maksimere forespørgslens effektivitet under søgning.
Når en tabel er uindekseret, vil rækkefølgen af rækkerne sandsynligvis ikke kunne skelnes af forespørgslen som optimeret på nogen måde, og din forespørgsel bliver derfor nødt til at søge gennem rækkerne lineært. Med andre ord, forespørgslerne skal søge gennem hver række for at finde de rækker, der matcher betingelserne. Som du kan forestille dig, kan dette tage lang tid. At kigge igennem hver enkelt række er ikke særlig effektivt.
For eksempel repræsenterer tabellen nedenfor en tabel i en fiktiv datakilde, som er fuldstændig uordnet.
| virksomheds-id | enhed | enhedspris |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Hvis vi skulle køre følgende forespørgsel:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
Databasen skulle søge gennem alle 17 rækker i den rækkefølge, de vises i tabellen, fra top til bund, én ad gangen. Så for at søge efter alle de potentielle forekomster af company_id nummer 18, skal databasen se gennem hele tabellen for alle optrædener af 18 i company_id kolonne.
Dette vil kun blive mere og mere tidskrævende, efterhånden som bordets størrelse øges. Efterhånden som dataenes sofistikerede stiger, er det, der i sidste ende kunne ske, at en tabel med en milliard rækker forbindes med en anden tabel med en milliard rækker; forespørgslen skal nu søge gennem det dobbelte antal rækker, der koster det dobbelte af tiden.
Du kan se, hvordan dette bliver problematisk i vores altid datamættede verden. Tabeller øges i størrelse og søgning øges i eksekveringstid.
At forespørge på en uindekseret tabel, hvis den præsenteres visuelt, ville se sådan ud:
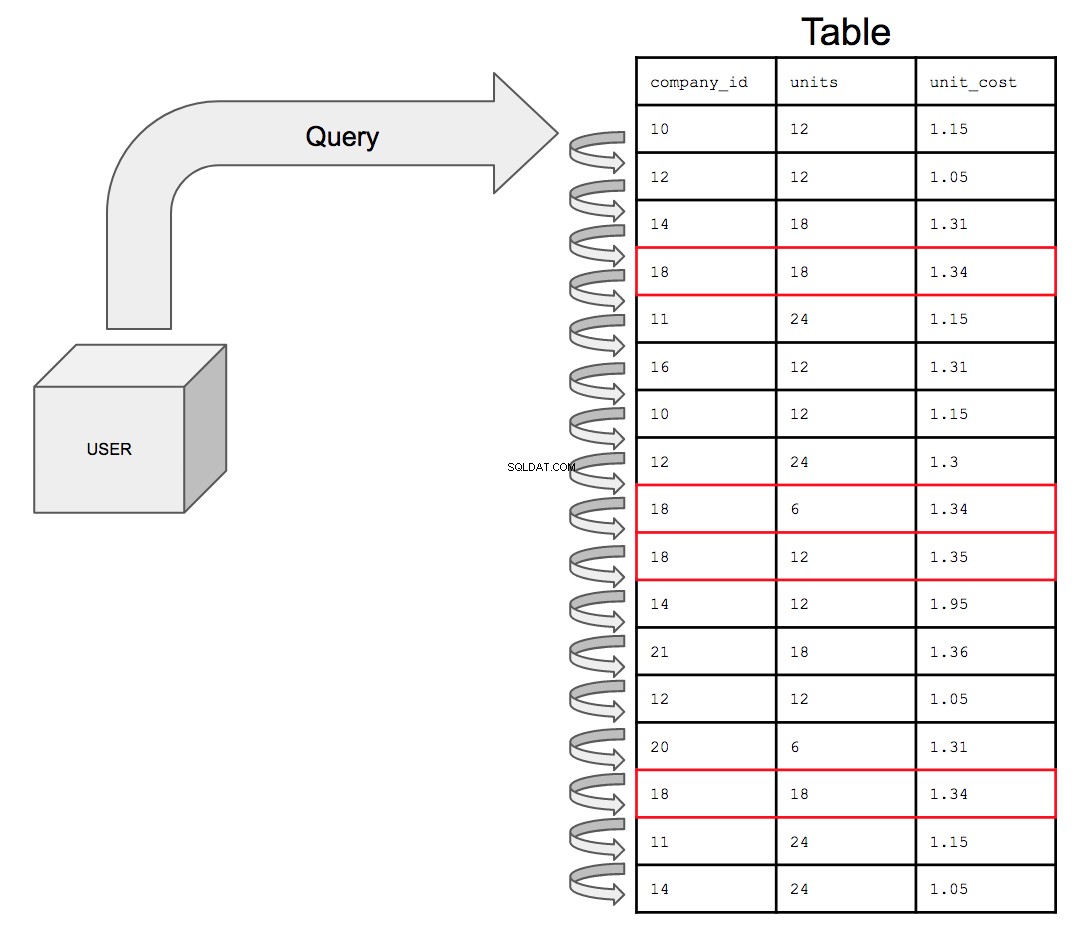
Hvad indeksering gør, er at opsætte den kolonne, du er søgebetingelser på, i en sorteret rækkefølge for at hjælpe med at optimere forespørgselsydeevne.
Med et indeks på company_id kolonne, ville tabellen i det væsentlige "se" sådan her:
| virksomheds-id | enhed | enhedspris |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Nu kan databasen søge efter company_id nummer 18 og returner alle de anmodede kolonner for den række og gå derefter videre til næste række. Hvis den næste række er comapny_id nummeret er også 18, så returnerer det alle de kolonner, der er anmodet om i forespørgslen. Hvis den næste rækkes company_id er 20, ved forespørgslen at stoppe med at søge, og forespørgslen afsluttes.
Hvordan fungerer indeksering?
I virkeligheden omorganiserer databasetabellen ikke sig selv hver gang forespørgselsbetingelserne ændres for at optimere forespørgselsydeevnen:det ville være urealistisk. I virkeligheden er det, der sker, at indekset får databasen til at skabe en datastruktur. Datastrukturtypen er meget sandsynligt et B-træ. Mens fordelene ved B-Tree er talrige, er den største fordel for vores formål, at det er sorterbart. Når datastrukturen er sorteret i rækkefølge, gør det vores søgning mere effektiv af de åbenlyse årsager, som vi har nævnt ovenfor.
Når indekset opretter en datastruktur på en specifik kolonne, er det vigtigt at bemærke, at ingen anden kolonne er gemt i datastrukturen. Vores datastruktur for tabellen ovenfor vil kun indeholde company_id tal. Enheder og unit_cost vil ikke blive holdt i datastrukturen.
Hvordan ved databasen, hvilke andre felter i tabellen der skal returneres?
Databaseindekser vil også gemme pointere, som blot er referenceinformation for placeringen af den yderligere information i hukommelsen. Grundlæggende indeholder indekset company_id og den pågældende rækkes hjemmeadresse på hukommelsesdisken. Indekset vil faktisk se sådan her ud:
| virksomheds-id | pointer |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
Med det indeks kan forespørgslen kun søge efter rækkerne i company_id kolonne, der har 18 og derefter ved hjælp af markøren kan gå ind i tabellen for at finde den specifikke række, hvor markøren bor. Forespørgslen kan derefter gå ind i tabellen for at hente felterne for de kolonner, der er anmodet om for de rækker, der opfylder betingelserne.
Hvis søgningen blev præsenteret visuelt, ville den se sådan ud:
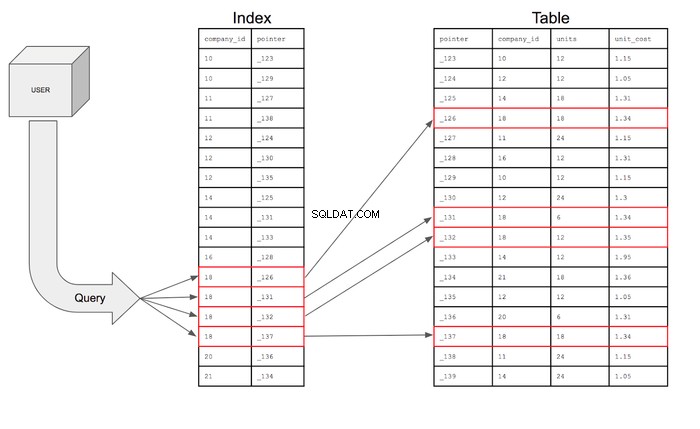
Recap
- Indeksering tilføjer en datastruktur med kolonner til søgebetingelserne og en markør
- Markøren er adressen på hukommelsesdisken i rækken med resten af informationen
- Indeksdatastrukturen er sorteret for at optimere forespørgselseffektiviteten
- Forespørgslen leder efter den specifikke række i indekset; indekset henviser til den markør, som finder resten af informationen.
- Indekset reducerer antallet af rækker, som forespørgslen skal søge igennem, fra 17 til 4.