Dette er en del af en SQL Server Internals Problematic Operators-serie. Sørg for at læse Kalens første indlæg og andet indlæg om dette emne.
SQL Server har eksisteret i over 30 år, og jeg har arbejdet med SQL Server i næsten lige så lang tid. Jeg har set en masse ændringer gennem årene (og årtier!) og versioner af dette utrolige produkt. I disse indlæg vil jeg dele med dig, hvordan jeg ser på nogle af funktionerne eller aspekterne af SQL Server, nogle gange sammen med en smule historisk perspektiv.
Sidste gang talte jeg om hashing i en SQL Server-forespørgselsplan som en potentielt problematisk operatør i SQL-serverdiagnostik. Hashing bruges ofte til joinforbindelser og aggregering, når der ikke er noget nyttigt indeks. Og ligesom scanninger (som jeg talte om i det første indlæg i denne serie), er der tidspunkter, hvor hashing faktisk er et bedre valg end alternativerne. For hash joins er et af alternativerne LOOP JOIN, som jeg også fortalte dig om sidste gang.
I dette indlæg vil jeg fortælle dig om et andet alternativ til hashing. De fleste af alternativerne til hashing kræver, at dataene sorteres, så enten skal planen inkludere en SORT-operatør, eller også skal de nødvendige data allerede være sorteret på grund af eksisterende indekser.
Forskellige typer joinforbindelser til SQL Server Diagnostics
For JOIN-operationer er den mest almindelige og nyttige type JOIN en LOOP JOIN. Jeg beskrev algoritmen for en LOOP JOIN i det forrige indlæg. Selvom dataene i sig selv ikke behøver at blive sorteret for en LOOP JOIN, gør tilstedeværelsen af et indeks på den indre tabel sammenføjningen meget mere effektiv, og som du burde vide, indebærer tilstedeværelsen af et indeks en vis sortering. Mens et klynget indeks sorterer selve dataene, sorterer et ikke-klynget indeks indeksnøglekolonnerne. Faktisk vil SQL Servers optimizer i de fleste tilfælde uden indekset vælge at bruge HASH JOIN-algoritmen. Det så vi i eksemplet sidste gang, at uden indekser blev HASH JOIN valgt, og med indekser fik vi en LOOP JOIN.
Den tredje type join er en MERGE JOIN. Denne algoritme fungerer på to allerede sorterede datasæt. Hvis vi forsøger at kombinere (eller JOIN) to sæt data, der allerede er sorteret, tager det blot en enkelt passage gennem hvert sæt for at finde de matchende rækker. Her er pseudokoden for fusionsforbindelsesalgoritmen:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Selvom MERGE JOIN er en meget effektiv algoritme, kræver den, at begge input-datasæt sorteres efter join-nøglen, hvilket normalt betyder at have et klynget indeks på join-nøglen for begge tabeller. Da du kun får ét klynget indeks pr. tabel, er det måske ikke det bedste overordnede valg til klyngenøgle at vælge den klyngede nøglekolonne bare for at tillade MERGE JOINS at ske.
Så normalt anbefaler jeg ikke, at du forsøger at bygge indekser kun med henblik på MERGE JOINS, men hvis du ender med at få en MERGE JOIN på grund af allerede eksisterende indekser, er det normalt en god ting. Ud over at kræve, at begge input-datasæt skal sorteres, kræver MERGE JOIN også, at mindst ét af datasættene har unikke værdier for join-nøglen.
Lad os se på et eksempel. Først genskaber vi overskrifterne og Detaljer tabeller:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Se derefter på planen for en sammenføjning mellem disse tabeller:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Her er planen:

Bemærk, at selv med et klynget indeks på begge tabeller, får vi en HASH JOIN. Vi kan genopbygge et af indekserne til at være UNIK. I dette tilfælde skal det være indekset på Overskrifterne tabel, fordi det er den eneste, der har unikke værdier for SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Kør nu forespørgslen igen, og bemærk, at planen gør, hvordan en FLÉT JOIN.

Disse planer har gavn af at have dataene allerede sorteret i et indeks, da eksekveringsplanen kan drage fordel af sorteringen. Men nogle gange skal SQL Server udføre sortering som en del af sin forespørgselsudførelse. Du kan lejlighedsvis se en SORT-operatør dukke op i en plan, selvom du ikke beder om sorteret output. Hvis SQL Server mener, at en MERGE JOIN kan være en god mulighed, men en af tabellerne ikke har det passende clustered index, og den er lille nok til at gøre sorteringen meget billig, kunne en SORT udføres for at tillade MERGE JOIN at være brugt.
Men normalt dukker SORT-operatoren op i forespørgsler, hvor vi har bedt om sorterede data med ORDER BY, som i det følgende eksempel.
SELECT * FROM Details
ORDER BY ProductID;
GO

Det klyngede indeks scannes (hvilket er det samme som at scanne tabellen), og derefter sorteres rækkerne som anmodet.
Håndtering af allerede sorteret grupperet indeks
Men hvad nu, hvis dataene allerede er sorteret i et klynget indeks, og forespørgslen indeholder en ORDER BY i den klyngede nøglekolonne? I eksemplet ovenfor byggede vi et klynget indeks på SalesOrderID i tabellen Detaljer. Se på følgende to forespørgsler:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Hvis vi kører disse forespørgsler sammen, viser Quest Spotlight Tuning Pack Analysis Window, at de to planer har samme pris; hver er 50% af det samlede beløb. Så hvad er egentlig forskellen mellem dem?
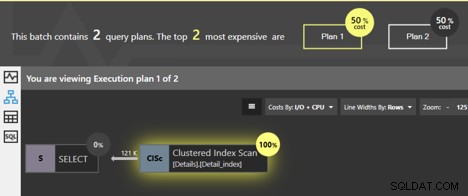
Begge forespørgsler scanner det klyngede indeks, og SQL Server ved, at hvis siderne på bladniveauet følges i rækkefølge, vil dataene komme tilbage i klynget nøglerækkefølge. Der skal ikke foretages yderligere sortering, så der tilføjes ingen SORT-operatør til planen. Men der ER en forskel. Vi kan klikke på Clustered Index Scan-operatøren og vil få nogle detaljerede oplysninger.
Se først på de detaljerede oplysninger for den første plan, for forespørgslen uden BESTIL EFTER.

Detaljerne fortæller os, at den "Bestilte" egenskab er falsk. Der er ikke her et krav om, at data skal returneres i sorteret rækkefølge. Det viser sig, at i de fleste tilfælde er den nemmeste måde at hente data på ved at følge siderne i det klyngede indeks, så dataene ender med at blive returneret i rækkefølge, men der er ingen garanti. Hvad egenskaben False betyder, er, at der ikke er noget krav om, at SQL Server følger de bestilte sider for at returnere resultatet. Der er faktisk andre måder, hvorpå SQL Server kan få alle rækkerne til tabellen, uden at følge det klyngede indeks. Hvis SQL Server under udførelsen vælger at bruge en anden metode til at hente rækkerne, vil vi ikke se ordnede resultater.
For den anden forespørgsel ser detaljerne således ud:
 Fordi forespørgslen indeholdt en ORDER BY, ER der et krav om, at dataene returneres i sorteret rækkefølge og SQL Server vil følge siderne i det klyngede indeks i rækkefølge.
Fordi forespørgslen indeholdt en ORDER BY, ER der et krav om, at dataene returneres i sorteret rækkefølge og SQL Server vil følge siderne i det klyngede indeks i rækkefølge.
Den vigtigste ting at huske her er, at INGEN garanti for sorterede data, hvis du ikke inkluderer ORDER BY i din forespørgsel. Bare fordi du har et klynget indeks, er der stadig ingen garanti! Selvom du hver eneste gang sidste år, hvor du kørte forespørgslen, fik dataene tilbage i orden uden BESTIL BY, er der ingen garanti for, at du vil fortsætte med at få dataene i orden igen. Brug af ORDER BY er den eneste måde at garantere den rækkefølge, som dine resultater returneres i.
Tips til brug af sorteringsoperationer
Så er en SORT en operation, der skal undgås i SQL-serverdiagnostik? Ligesom scanninger og hash-operationer er svaret selvfølgelig 'det afhænger'. Sortering kan være meget dyrt, især på store datasæt. Korrekt indeksering hjælper SQL Server med at undgå at udføre SORT-operationer, fordi et indeks grundlæggende betyder, at dine data er forudsorteret. Men indeksering kommer med en omkostning. Der er lageromkostninger, ud over vedligeholdelsesomkostninger, for hvert indeks. Hvis dine data er stærkt opdateret, skal du holde antallet af indekser på et minimum.
Hvis du opdager, at nogle af dine langsomt kørende forespørgsler viser SORT-operationer i deres planer, og hvis disse SORT'er er blandt de dyreste operatører i planen, kan du overveje at bygge indekser, der tillader SQL Server at undgå sorteringen. Men du bliver nødt til at udføre grundige tests for at sikre, at de ekstra indekser ikke bremser andre forespørgsler, der er afgørende for din overordnede applikationsydelse.