Denne artikel viser, hvordan SQL Server kombinerer tæthedsoplysninger fra flere enkeltkolonnestatistikker for at producere et kardinalitetsestimat for en aggregering over flere kolonner. Detaljerne er forhåbentlig interessante i sig selv. De giver også et indblik i nogle af de generelle tilgange og algoritmer, der bruges af kardinalitetsestimatoren.
Overvej følgende AdventureWorks-eksempeldatabaseforespørgsel, som viser antallet af produktbeholdningsartikler i hver beholder på hver hylde i lageret:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Den estimerede udførelsesplan viser 1.069 rækker, der læses fra tabellen, sorteret i Shelf og Bin rækkefølge, derefter aggregeret ved hjælp af en Stream Aggregate-operator:
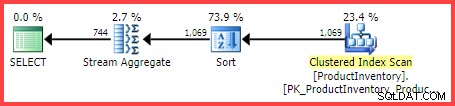
Estimeret udførelsesplan
Spørgsmålet er, hvordan nåede SQL Server-forespørgselsoptimeringsværktøjet frem til det endelige estimat på 744 rækker?
Tilgængelig statistik
Når forespørgslen ovenfor kompileres, vil forespørgselsoptimeringsværktøjet oprette enkeltkolonnestatistik på Shelf og Bin kolonner, hvis der ikke allerede findes passende statistik. Disse statistikker giver blandt andet information om antallet af distinkte kolonneværdier (i tæthedsvektoren):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Resultaterne er opsummeret i tabellen nedenfor (den tredje kolonne er beregnet ud fra tætheden):
| Kolonne | Tæthed | 1 / Tæthed |
|---|---|---|
| hylde | 0,04761905 | 21 |
| Bin | 0,01612903 | 62 |
Vektoroplysninger om hylde- og beholdertæthed
Som dokumentationen bemærker, er den gensidige af tætheden antallet af distinkte værdier i kolonnen. Fra de statistiske oplysninger vist ovenfor ved SQL Server, at der var 21 forskellige Shelf værdier og 62 forskellige Bin værdier i tabellen, hvornår statistikken blev indsamlet.
Opgaven med at estimere antallet af rækker produceret af en GROUP BY klausul er triviel, når kun en enkelt kolonne er involveret (forudsat ingen andre prædikater). For eksempel er det nemt at se, at GROUP BY Shelf vil producere 21 rækker; GROUP BY Bin vil producere 62.
Det er dog ikke umiddelbart klart, hvordan SQL Server kan estimere antallet af distinkte (Shelf, Bin) kombinationer for vores GROUP BY Shelf, Bin forespørgsel. For at stille spørgsmålet på en lidt anden måde:Givet 21 hylder og 62 skraldespande, hvor mange unikke kombinationer af hylde og skraldespande vil der være? Ser man bort fra fysiske aspekter og anden menneskelig viden om problemdomænet, kan svaret være alt fra max(21, 62) =62 til (21 * 62) =1.302. Uden mere information er der ingen indlysende måde at vide, hvor man skal pitche et estimat i det interval.
Men for vores eksempelforespørgsel estimerer SQL Server 744.312 rækker (afrundet til 744 i Plan Explorer-visningen), men på hvilket grundlag?
Kardinalitetsvurdering udvidet hændelse
Den dokumenterede måde at se på kardinalitetsestimeringsprocessen på er at bruge den udvidede hændelse query_optimizer_estimate_cardinality (på trods af at det er i "debug"-kanalen). Mens en session, der indsamler denne hændelse, kører, får eksekveringsplanoperatører en ekstra egenskab StatsCollectionId der knytter individuelle operatørestimater til de beregninger, der har produceret dem. For vores eksempelforespørgsel er statistikindsamlings-id 2 knyttet til kardinalitetsestimatet for gruppen efter aggregeret operatør.
Det relevante output fra den udvidede begivenhed for vores testforespørgsel er:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Der er helt sikkert nogle nyttige oplysninger der.
Vi kan se, at regnemaskineklassen for planblads distinkte værdier (CDVCPlanLeaf ) blev brugt ved at bruge enkelt kolonne statistik på Shelf og Bin som input. Statistikindsamlingselementet matcher dette fragment med id'et (2) vist i udførelsesplanen, som viser kardinalitetsestimatet på 744.31 , og mere information om de anvendte statistiske objekt-id'er.
Desværre er der intet i begivenhedens output, der siger præcis, hvordan lommeregneren nåede frem til det endelige tal, hvilket er det, vi virkelig er interesserede i.
Kombinering af forskellige tæller
Går vi en mindre dokumenteret rute, kan vi anmode om en estimeret plan for forespørgslen med sporingsflag 2363 og 3604 aktiveret:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Dette returnerer fejlfindingsoplysninger til fanen Meddelelser i SQL Server Management Studio. Den interessante del er gengivet nedenfor:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Dette viser stort set den samme information, som den udvidede begivenhed gjorde i et (formentlig) lettere at forbruge format:
- Input relationsoperatoren til at beregne et kardinalitetsestimat for (
LogOp_GbAgg– logisk gruppe efter aggregat) - Den anvendte lommeregner (
CDVCPlanLeaf) og inputstatistik - De resulterende statistikindsamlingsdetaljer
Den interessante nye information er den del, der handler om at bruge omgivende kardinalitet til at kombinere forskellige tal .
Dette viser tydeligt, at værdierne 21, 62 og 1069 blev brugt, men (frustrerende nok) stadig ikke nøjagtigt, hvilke beregninger der blev udført for at nå frem til 744.312 resultat.
Til Debugger!
Ved at vedhæfte en debugger og bruge offentlige symboler kan vi i detaljer udforske den kodesti, som følges under kompileringen af eksempelforespørgslen.
Snapshottet nedenfor viser den øverste del af opkaldsstakken på et repræsentativt punkt i processen:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Der er et par interessante detaljer her. Når vi arbejder nedefra og op, ser vi, at kardinalitet udledes ved hjælp af den opdaterede CE (CCardFrameworkSQL12 ) tilgængelig i SQL Server 2014 og senere (den originale CE er CCardFrameworkSQL7 ), for gruppen efter aggregeret logisk operator (CLogOp_GbAgg ).
At beregne den distinkte kardinalitet involverer at kombinere (munging) flere input, ved at bruge sampling uden erstatning.
Referencen til H og en (naturlig) logaritme i den anden metode fra toppen viser brugen af Shannon Entropy i beregningen:
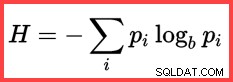
Shannon-entropi
Entropi kan bruges til at estimere informationskorrelationen (gensidig information) mellem to statistikker:
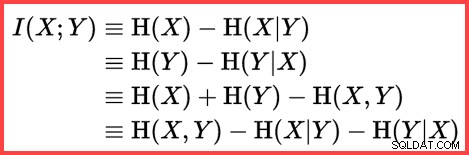
Gensidig information
Ved at sætte alt dette sammen kan vi konstruere et T-SQL-beregningsscript, der matcher den måde, SQL Server bruger sampling uden erstatning, Shannon Entropy og gensidig information at producere det endelige kardinalitetsestimat.
Vi starter med inputtallene (omgivende kardinalitet og antallet af distinkte værdier i hver kolonne):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; frekvensen af hver kolonne er det gennemsnitlige antal rækker pr. særskilt værdi:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Sampling uden erstatning (SWR) er et simpelt spørgsmål om at trække det gennemsnitlige antal rækker pr. distinkt værdi (frekvens) fra det samlede antal rækker:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Beregn entropierne (N log N) og gensidig information:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Nu har vi estimeret, hvor korrelerede de to sæt statistikker er, vi kan beregne det endelige estimat:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Resultatet af beregningen er 744.311823994677, hvilket er 744.312 afrundet til tre decimaler.
For nemheds skyld er her hele koden i én blok:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Sidste tanker
Det endelige estimat er ufuldkomment i dette tilfælde – eksempelforespørgslen returnerer faktisk 441 rækker.
For at opnå et forbedret estimat kunne vi give optimeringsværktøjet bedre oplysninger om tætheden af Bin og Shelf kolonner ved hjælp af en multikolonnestatistik. For eksempel:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Med denne statistik på plads (enten som givet, eller som en bivirkning af at tilføje et lignende multikolonneindeks), er kardinalitetsestimatet for eksempelforespørgslen nøjagtigt korrekt. Det er dog sjældent at beregne en så simpel aggregering. Med yderligere prædikater kan multikolonnestatistikken være mindre effektiv. Ikke desto mindre er det vigtigt at huske, at de yderligere tæthedsoplysninger, der leveres af multikolonnestatistikker, kan være nyttige til aggregeringer (såvel som lighedssammenligninger).
Uden en multikolonnestatistik kan en samlet forespørgsel med yderligere prædikater muligvis stadig bruge den væsentlige logik, der er vist i denne artikel. For eksempel, i stedet for at anvende formlen på tabellens kardinalitet, kan den anvendes til at indtaste histogrammer trin for trin.
Relateret indhold:Kardinalitetsvurdering for et prædikat på et COUNT-udtryk