Service Pack 2 til SQL Server 2014 blev udgivet i sidste måned (læs udgivelsesbemærkningerne her) og inkluderer en ny DBCC-sætning:DBCC CLONEDATABASE . Jeg var ret spændt på at se denne kommando introduceret, da den giver en meget nem måde at kopiere et databaseskema på, inklusive statistik , som kan bruges til at teste forespørgselsydeevne uden at kræve al den nødvendige plads til dataene i databasen. Jeg fik endelig tid til at teste DBCC CLONEDATABASE og forstå begrænsningerne, og jeg må sige, at det var ret sjovt.
Det grundlæggende
Jeg startede med at oprette en klon af AdventureWorks2014-databasen og køre en forespørgsel mod kildedatabasen og derefter klondatabasen:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
Hvis jeg ser på I/O- og TIME-outputtet, kan jeg se, at forespørgslen mod kildedatabasen tog længere tid og genererede meget mere I/O, som begge forventes, da klondatabasen ikke har nogen data i sig:
/* SOURCE database */
SQL Server-udførelsestider:
CPU-tid =0 ms, forløbet tid =0 ms.
SQL Server-parse og kompileringstid:
CPU-tid =0 ms, forløbet tid =4 ms.
(121317 række(r) påvirket)
Tabel 'SalesOrderHeader'. Scanningsantal 0, logisk læser 371567, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'SalgOrdredetalje'. Scanning tæller 5, logisk læser 1361, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
(1 række(r) påvirket)
SQL Server-udførelsestider:
CPU-tid =686 ms, forløbet tid =2548 ms.
/* CLONE database */
SQL Server-udførelsestider:
CPU-tid =0 ms, forløbet tid =0 ms.
SQL Server-parse og kompileringstid:
CPU-tid =12 ms, forløbet tid =12 ms.
(0 række(r) påvirket)
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'SalesOrderHeader'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'SalgOrdredetalje'. Scanningsantal 5, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
(1 række(r) påvirket)
SQL Server-udførelsestider:
CPU-tid =0 ms, forløbet tid =83 ms.
Hvis jeg ser på udførelsesplanerne, er de ens for begge databaser bortset fra de faktiske værdier (mængden af data, der rent faktisk flyttede gennem planen):
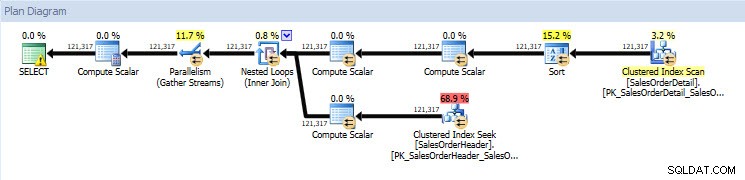 Forespørgselsplan for AdventureWorks2014-databasen
Forespørgselsplan for AdventureWorks2014-databasen
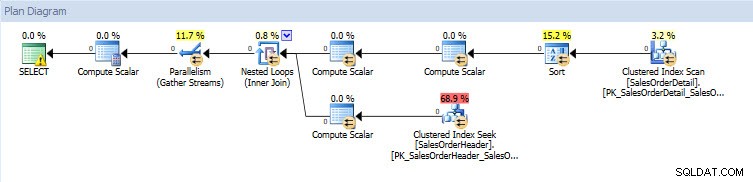 Forespørgselsplan for AdventureWorks2014_CLONE-database
Forespørgselsplan for AdventureWorks2014_CLONE-database
Det er her værdien af DBCC CLONEDATABASE er tilsyneladende – jeg kan få en tom kopi af en database til enhver (Microsoft Product Support, min kollega DBA osv.) og få dem til at genskabe og undersøge et problem, og de behøver ikke potentielt hundredvis af GB diskplads for at gøre det. det. Melissas juli T-SQL tirsdag-indlæg har detaljerede oplysninger om, hvad der sker under klonprocessen, så jeg anbefaler at læse det for mere information.
Er det det?
Men... kan jeg gøre mere med DBCC CLONEDATABASE ? Jeg mener, det er fantastisk, men jeg tror, der er mange andre ting, jeg kan gøre med en tom kopi af databasen. Hvis du læser dokumentationen til DBCC CLONEDATABASE , vil du se denne linje:
Min første tanke var, "forespørgselsoptimering - hmm... kan jeg bruge dette som en mulighed for at teste opgraderinger ?”
Nå, den klonede database er skrivebeskyttet, men jeg tænkte, at jeg alligevel ville prøve at ændre nogle muligheder. For eksempel, hvis jeg kunne ændre kompatibilitetstilstanden, ville det være rigtig fedt, da jeg så kunne teste CE-ændringer i både SQL Server 2014 og SQL Server 2016.
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
Jeg får en fejlmeddelelse:
Meddelelse 3906, niveau 16, tilstand 1Kunnede ikke opdatere databasen "AdventureWorks2014_CLONE", fordi databasen er skrivebeskyttet.
Besked 5069, niveau 16, tilstand 1
ALTER DATABASE-sætning mislykkedes.
Hm. Kan jeg ændre gendannelsesmodellen?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
Jeg kan. Det virker ikke rimeligt. Nå, det er skrivebeskyttet, kan jeg ændre det?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
JA! Inden du bliver for ophidset, så lad mig efterlade denne note fra dokumentationen lige her:
Bemærk Den nyligt genererede database, der er genereret fra DBCC CLONEDATABASE, understøttes ikke til brug som en produktionsdatabase og er primært beregnet til fejlfinding og diagnostiske formål. Vi anbefaler at frakoble den klonede database, efter databasen er oprettet.Jeg har tænkt mig at gentage denne linje fra dokumentationen og fed den og sætte den rød som en venlig men ekstremt vigtig påmindelse:
Den nygenererede database, der er genereret fra DBCC CLONEDATABASE, understøttes ikke til brug som en produktionsdatabase og er primært beregnet til fejlfinding og diagnostiske formål.Nå det er fint med mig, jeg ville bestemt ikke bruge dette til produktion, men nu kan jeg bruge det til at teste! NU kan jeg ændre kompatibilitetstilstanden, og NU kan jeg sikkerhedskopiere den og gendanne den på en anden instans til test!
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
DET ER STORT.
I mit sidste indlæg talte jeg om sporingsflag 2389 og testning med den nye Cardinality Estimator, fordi venner, du bruger at teste med den nye CE, før du opgraderer. Hvis du ikke tester, og hvis du ændrer kompatibilitetstilstanden til 120 (SQL Server 2014) eller 130 (SQL Server 2016) som en del af din opgradering, risikerer du at arbejde i en brandslukningstilstand, hvis du løber ind i regressioner med det nye CE. Nu kan du have det helt fint, og ydeevnen kan være endnu bedre, efter du har opgraderet. Men... vil du ikke gerne være sikker?
Meget ofte, når jeg nævner test før en opgradering, får jeg at vide, at der ikke er noget miljø, hvor man kan udføre testen. Jeg ved, at nogle af jer har et testmiljø. Nogle af jer har Test, Dev, QA, UAT og hvem ved hvad ellers. Du er heldig.
Til de af jer, der siger, at I slet ikke har noget testmiljø at teste i, giver jeg jer DBCC CLONEDATABASE . Med denne kommando har du ingen undskyldning for ikke at køre de hyppigst udførte forespørgsler og heavy-hitters mod en klon af din database. Selvom du ikke har et testmiljø, har du din egen maskine. Sikkerhedskopier klondatabasen fra produktionen, slip klonen, gendan sikkerhedskopien til din lokale instans, og test derefter. Klondatabasen fylder meget lidt på disken, og du vil ikke pådrage dig hukommelse eller I/O-stridigheder, da der ikke er nogen data. Du vil være i stand til at validere forespørgselsplaner fra klonen mod dem fra din produktionsdatabase. Yderligere, hvis du gendanner på SQL Server 2016, kan du inkorporere Query Store i din test! Aktiver Query Store, kør gennem din test i den originale kompatibilitetstilstand, opgrader derefter kompatibilitetstilstanden og test igen. Du kan bruge Query Store til at sammenligne forespørgsler side om side! (Kan du se, at jeg danser i min stol lige nu?)
Overvejelser
Igen, dette burde ikke være noget, du ville bruge i produktionen, og jeg ved, du ikke ville gøre det, men det tåler at blive gentaget, for i sin nuværende tilstand, DBCC CLONEDATABASE er ikke helt komplet . Dette er noteret i KB-artiklen under understøttede objekter; objekter såsom hukommelsesoptimerede tabeller og filtabeller kopieres ikke, fuldtekst understøttes ikke osv.
Nu er klondatabasen ikke uden ulemper. Hvis du ved et uheld kører en indeksgenopbygning eller en opdatering af statistik i den database, har du lige slettet dine testdata. Du vil miste den originale statistik, hvilket er, hvad du sandsynligvis virkelig ønskede i første omgang. For eksempel, hvis jeg tjekker statistik for det klyngede indeks på SalesOrderHeader lige nu, får jeg dette:
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Original statistik for SalesOrderHeader
Original statistik for SalesOrderHeader
Nu, hvis jeg opdaterer statistik mod den tabel, får jeg dette:
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Opdateret (tom) statistik for SalesOrderHeader
Opdateret (tom) statistik for SalesOrderHeader
Som en ekstra sikkerhed er det nok en god idé at deaktivere automatiske opdateringer til statistik:
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
Hvis du tilfældigvis opdaterer statistik utilsigtet, skal du køre DBCC CLONEDATABASE og det er ikke så svært at gennemgå backup- og gendannelsesprocessen, og du vil få det automatiseret på ingen tid.
Du kan tilføje data til databasen. Dette kan være nyttigt, hvis du vil eksperimentere med statistik (f.eks. forskellige samplingsfrekvenser, filtrerede statistikker), og du har nok lagerplads til at opbevare en kopi af tabellens data.
Uden data i databasen vil du naturligvis ikke få pålideligt repræsentativ varighed og I/O-data. Det er ok. Hvis du har brug for data om reelt ressourceforbrug, skal du have en kopi af din database med alle dataene i den. DBCC CLONEDATABASE handler i virkeligheden om at teste forespørgselsydeevne; det er det. Det er på ingen måde en erstatning for traditionel opgraderingstest – men det er en ny mulighed for at validere, hvordan SQL Server optimerer en forespørgsel med forskellige versioner og kompatibilitetstilstande. God test!