
Jeg blev for nylig skældt ud for at foreslå, at et ikke-klynget indeks i nogle tilfælde vil klare sig bedre for en bestemt forespørgsel end det klyngede indeks. Denne person sagde, at det klyngede indeks altid er bedst, fordi det altid dækker pr. definition, og at ethvert ikke-klynget indeks med nogle eller alle de samme nøglekolonner altid var overflødige.
Jeg er heldigvis enig i, at det klyngede indeks altid dækker (og for at undgå enhver tvetydighed her, vil vi holde os til diskbaserede tabeller med traditionelle B-træindekser).
 Jeg er dog uenig i, at et klynget indeks altid er hurtigere end et ikke-klynget indeks. Jeg er også uenig i, at det altid er overflødigt at oprette et ikke-klynget indeks eller en unik begrænsning, der består af de samme (eller nogle af de samme) kolonner i klyngingsnøglen.
Jeg er dog uenig i, at et klynget indeks altid er hurtigere end et ikke-klynget indeks. Jeg er også uenig i, at det altid er overflødigt at oprette et ikke-klynget indeks eller en unik begrænsning, der består af de samme (eller nogle af de samme) kolonner i klyngingsnøglen.
Lad os tage dette eksempel, Warehouse.StockItemTransactions , fra WideWorldImporters. Det klyngede indeks implementeres gennem en primær nøgle på kun StockItemTransactionID kolonne (temmelig typisk, når du har en form for surrogat-id genereret af en IDENTITET eller en SEKVENS).
Det er en ret almindelig ting at kræve en optælling af hele bordet (selvom der i mange tilfælde er bedre måder). Dette kan være til tilfældig inspektion eller som en del af en pagineringsprocedure. De fleste mennesker vil gøre det på denne måde:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Med det aktuelle skema vil dette bruge et ikke-klynget indeks:
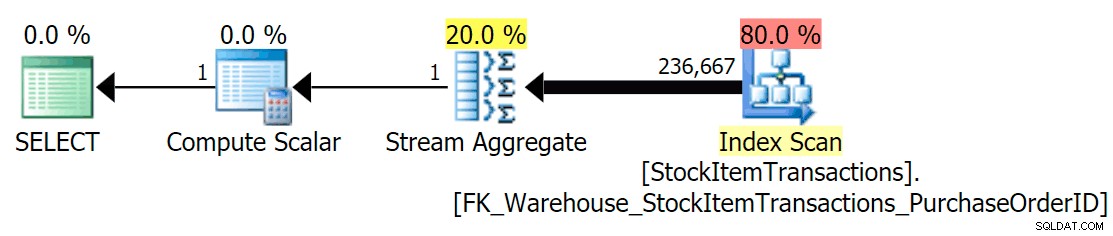
Vi ved, at det ikke-klyngede indeks ikke indeholder alle kolonnerne i det klyngede indeks. Optællingsoperationen skal kun være sikker på, at alle rækker er inkluderet, uden at bekymre sig om hvilke kolonner der er til stede, så SQL Server vil normalt vælge det indeks med det mindste antal sider (i dette tilfælde har det valgte indeks ~414 sider).
Lad os nu køre forespørgslen igen, denne gang sammenligne den med en antydet forespørgsel, der tvinger brugen af det klyngede indeks.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Vi får en næsten identisk planform, men vi kan se en enorm forskel i læsninger (414 for det valgte indeks vs. 1.982 for det klyngede indeks):
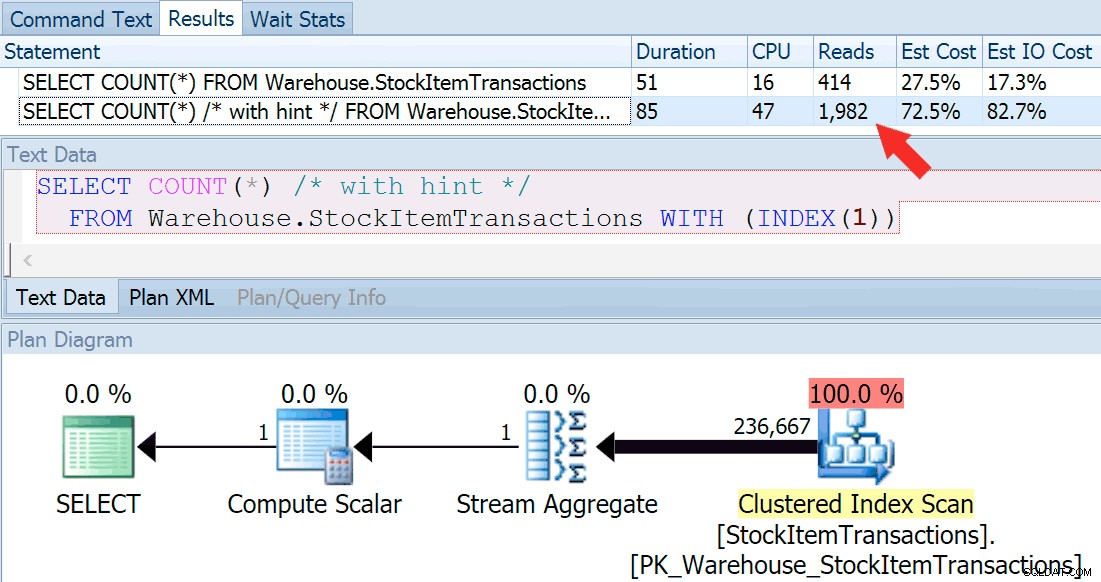
Varigheden er lidt højere for det klyngede indeks, men forskellen er ubetydelig, når vi har at gøre med en lille mængde cachelagrede data på en hurtig disk. Denne uoverensstemmelse ville være meget mere udtalt med flere data, på en langsom disk eller på et system med hukommelsestryk.
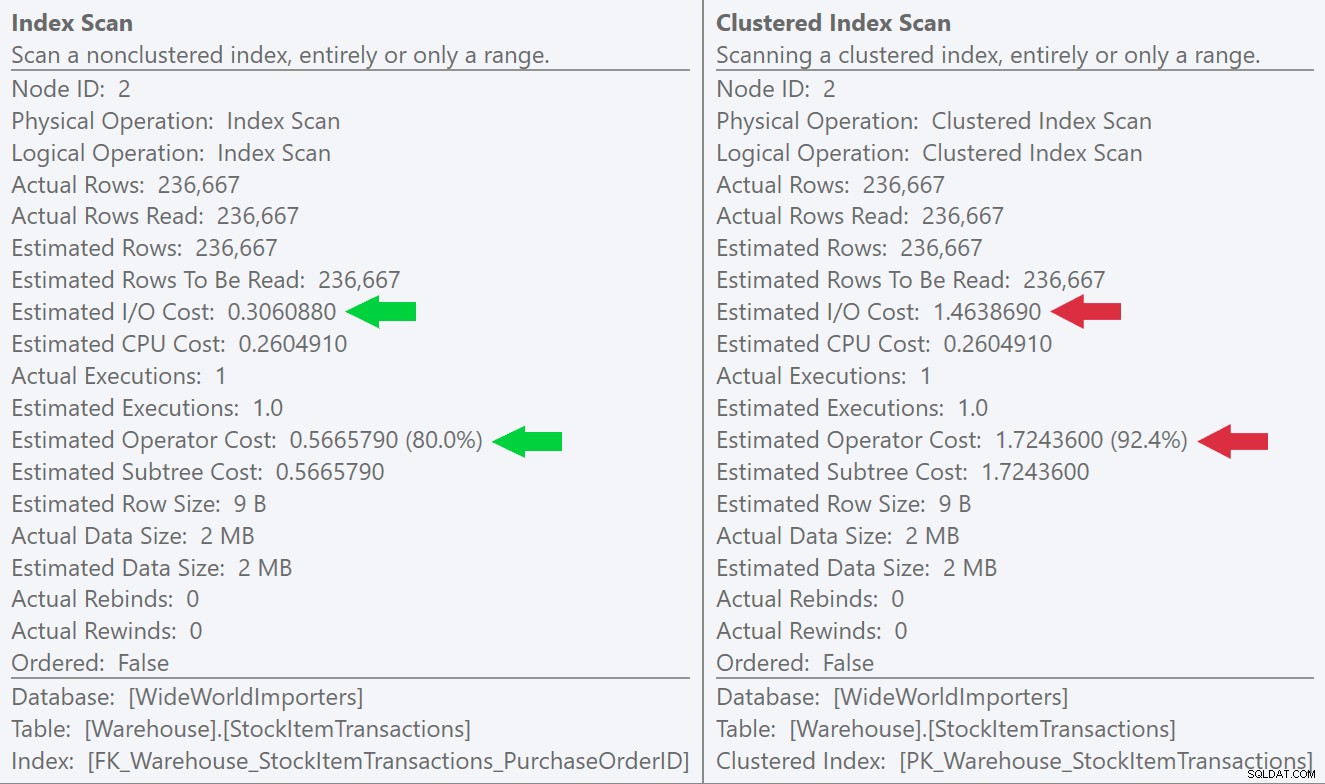
Hvis vi ser på værktøjstip til scanningsoperationerne, kan vi se, at selvom antallet af rækker og estimerede CPU-omkostninger er identiske, kommer den store forskel fra de estimerede I/O-omkostninger (fordi SQL Server ved, at der er flere sider i klynget indeks end det ikke-klyngede indeks):
Vi kan se denne forskel endnu tydeligere, hvis vi opretter et nyt, unikt indeks på kun ID-kolonnen (gør det "overflødigt" med det klyngede indeks, ikke?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
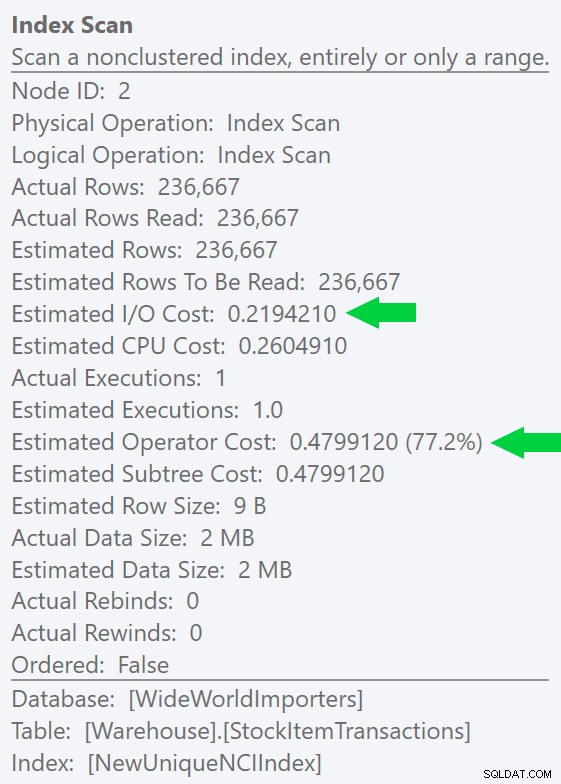 Kørsel af en lignende forespørgsel med et eksplicit indekstip producerer den samme planform, men en endnu lavere estimeret I/O pris (og endnu lavere varighed) - se billedet til højre. Og hvis du kører den originale forespørgsel uden hint, vil du se, at SQL Server nu også vælger dette indeks.
Kørsel af en lignende forespørgsel med et eksplicit indekstip producerer den samme planform, men en endnu lavere estimeret I/O pris (og endnu lavere varighed) - se billedet til højre. Og hvis du kører den originale forespørgsel uden hint, vil du se, at SQL Server nu også vælger dette indeks.
Det kan virke indlysende, men mange mennesker vil tro, at det klyngede indeks er det bedste valg her. SQL Server vil næsten altid gå stærkt ind for den metode, der giver den billigste måde at udføre hele I/O på, og i tilfælde af en fuld scanning vil det være det "slankeste" indeks. Dette kan også ske med begge typer søgninger (singleton- og rangescanninger), i det mindste når indekset dækker.
Nu, som altid, gør det ikke på nogen måde betyder, at du skal gå hen og oprette yderligere indekser på alle dine tabeller for at tilfredsstille tælleforespørgsler. Det er ikke kun en ineffektiv måde at kontrollere tabelstørrelse på (igen, se denne artikel), men et indeks til understøttelse, der skulle betyde, at du kører den forespørgsel oftere, end du opdaterer dataene. Husk, at hvert indeks kræver plads på disken, plads på hukommelsen, og alle skrivninger mod tabellen skal også røre hvert indeks (filtrerede indekser til side).
Oversigt
Jeg kunne komme med mange andre eksempler, der viser, hvornår en ikke-klynget kan være nyttig og værd at vedligeholde omkostningerne ved, selv når du dublerer nøglekolonnen(r) i det klyngede indeks. Ikke-klyngede indekser kan oprettes med de samme nøglekolonner, men i en anden nøglerækkefølge, eller med forskellige ASC/DESC på selve kolonnerne for bedre at understøtte en alternativ præsentationsrækkefølge. Du kan også have ikke-klyngede indekser, der kun bærer en lille delmængde af rækkerne ved brug af et filter. Endelig, hvis du kan tilfredsstille dine mest almindelige forespørgsler med tyndere, ikke-klyngede indekser, er det også bedre for hukommelsesforbruget.
Men egentlig er min pointe med denne serie blot at vise et modeksempel, der illustrerer det tåbelige i at komme med generelle udtalelser som denne. Jeg vil efterlade dig med en forklaring fra Paul White, som i et DBA.SE-svar forklarer, hvorfor et sådant ikke-klynget indeks faktisk kan klare sig meget bedre end et klynget indeks. Dette er sandt, selv når begge bruger begge typer søge:
- Forskellen mellem klynget indekssøgning og ikke-klynget indekssøgning