I en perfekt verden ville det være ligegyldigt, hvilken bestemt T-SQL-syntaks vi valgte til at udtrykke en forespørgsel. Enhver semantisk identisk konstruktion ville føre til nøjagtig den samme fysiske udførelsesplan med nøjagtig de samme præstationskarakteristika.
For at opnå det skal SQL Server-forespørgselsoptimeringsværktøjet kende enhver mulig logisk ækvivalens (forudsat at vi nogensinde kunne kende dem alle sammen) og få tid og ressourcer til at udforske alle mulighederne. I betragtning af det enorme antal mulige måder, vi kan udtrykke det samme krav i T-SQL, og det enorme antal mulige transformationer, bliver kombinationerne hurtigt uoverskuelige for alle undtagen de allersimpledeste tilfælde.
En "perfekt verden" med fuldstændig syntaksuafhængighed virker måske ikke helt så perfekt for brugere, der skal vente dage, uger eller endda år på, at en beskedent kompleks forespørgsel skal kompileres. Så forespørgselsoptimeringsværktøjet går på kompromis:den udforsker nogle almindelige ækvivalenser og prøver hårdt på at undgå at bruge mere tid på kompilering og optimering, end den sparer i eksekveringstid. Dens mål kan opsummeres som at forsøge at finde en rimelig eksekveringsplan inden for en rimelig tid, samtidig med at der forbruges rimelige ressourcer.
Et resultat af alt dette er, at eksekveringsplaner ofte er følsomme over for den skriftlige form af forespørgslen. Optimizeren har en vis logik til hurtigt at omdanne nogle udbredte ækvivalente konstruktioner til en fælles form, men disse evner er hverken veldokumenterede eller (nærmest) omfattende.
Vi kan helt sikkert maksimere vores chancer for at få en god eksekveringsplan ved at skrive enklere forespørgsler, levere nyttige indekser, vedligeholde gode statistikker og begrænse os til mere relationelle begreber (f.eks. ved at undgå markører, eksplicitte loops og ikke-inline funktioner), men dette er ikke en komplet løsning. Det er heller ikke muligt at sige, at én T-SQL-konstruktion altid vil producere en bedre eksekveringsplan end et semantisk-identisk alternativ.
Mit sædvanlige råd er at starte med den enkleste relationelle forespørgselsform, der opfylder dine behov, ved at bruge den T-SQL-syntaks, du finder at foretrække. Hvis forespørgslen ikke opfylder kravene efter fysisk optimering (f.eks. indeksering), kan det være værd at forsøge at udtrykke forespørgslen på en lidt anden måde, samtidig med at den originale semantik bibeholdes. Dette er den vanskelige del. Hvilken del af forespørgslen skal du prøve at omskrive? Hvilken omskrivning skal du prøve? Der er ikke noget enkelt ensartet svar på disse spørgsmål. Noget af det kommer ned til erfaring, selvom det også kan være en nyttig guide at vide lidt om forespørgselsoptimering og udførelsesmotorens interne funktioner.
Eksempel
Dette eksempel bruger AdventureWorks TransactionHistory-tabellen. Scriptet nedenfor laver en kopi af tabellen og opretter et klynget og ikke-klynget indeks. Vi vil slet ikke ændre dataene; dette trin er blot for at gøre indekseringen tydelig (og for at give tabellen et kortere navn):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Opgaven er at lave en liste over produkt- og historie-id'er for seks bestemte produkter. En måde at udtrykke forespørgslen på er:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Denne forespørgsel returnerer 764 rækker ved hjælp af følgende eksekveringsplan (vist i SentryOne Plan Explorer):

Denne enkle forespørgsel kvalificerer til TRIVIAL plan kompilering. Udførelsesplanen indeholder seks separate indekssøgningsoperationer i én:
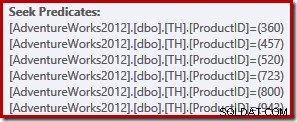
Ørneøjede læsere vil have bemærket, at de seks søgninger er opført i stigende produkt-id-rækkefølge, ikke i den (vilkårlige) rækkefølge, der er angivet i den oprindelige forespørgsels IN-liste. Hvis du selv kører forespørgslen, vil du sandsynligvis se resultater, der returneres i stigende produkt-id-rækkefølge. Forespørgslen er ikke garanteret at returnere resultater i den rækkefølge, selvfølgelig, fordi vi ikke specificerede en ORDER BY-klausul på øverste niveau. Vi kan dog tilføje en sådan ORDER BY-klausul uden at ændre den udførelsesplan, der er udarbejdet i dette tilfælde:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Jeg vil ikke gentage grafikken for eksekveringsplanen, fordi den er nøjagtig den samme:forespørgslen kvalificerer stadig til en triviel plan, de søgeoperationer er nøjagtig de samme, og de to planer har nøjagtig den samme anslåede pris. Tilføjelse af ORDER BY-klausulen kostede os præcis ingenting, men gav os en garanti for bestilling af resultatet.
Vi har nu en garanti for, at resultater vil blive returneret i produkt-id-rækkefølge, men vores forespørgsel specificerer i øjeblikket ikke, hvordan rækker med samme produkt-id vil blive bestilt. Når du ser på resultaterne, kan du se, at rækker for det samme produkt-id ser ud til at være sorteret efter transaktions-id, stigende.
Uden en eksplicit ORDER BY er dette blot endnu en observation (dvs. vi kan ikke stole på denne bestilling), men vi kan ændre forespørgslen for at sikre, at rækker er ordnet efter transaktions-id inden for hvert produkt-id:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Igen er udførelsesplanen for denne forespørgsel nøjagtig den samme som før; den samme trivielle plan med samme estimerede omkostninger fremstilles. Forskellen er, at resultaterne nu er garanteret bestilles først efter produkt-id og derefter efter transaktions-id.
Nogle mennesker kunne være fristet til at konkludere, at de to foregående forespørgsler også altid ville returnere rækker i denne rækkefølge, fordi udførelsesplanerne er de samme. Dette er ikke en sikker implikation, fordi ikke alle eksekveringsmotordetaljer er afsløret i eksekveringsplaner (selv i XML-formen). Uden en eksplicit orden efter klausul kan SQL Server frit returnere rækkerne i enhver rækkefølge, selvom planen ser ens ud for os (den kunne f.eks. udføre søgningerne i den rækkefølge, der er angivet i forespørgselsteksten). Pointen er, at forespørgselsoptimeringsværktøjet kender til og kan håndhæve visse adfærd i motoren, som ikke er synlige for brugerne.
Hvis du undrer dig over, hvordan vores ikke-unikke ikke-klyngede indeks på produkt-id kan returnere rækker i produkt og Transaktions-id ordre, svaret er, at den ikke-klyngede indeksnøgle inkorporerer Transaktions-ID (den unikke klyngede indeksnøgle). Faktisk det fysiske strukturen af vores ikke-klyngede indeks er præcis det samme, på alle niveauer, som hvis vi havde oprettet indekset med følgende definition:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Vi kan endda skrive forespørgslen med en eksplicit DISTINCT eller GROUP BY og stadig få nøjagtig den samme eksekveringsplan:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
For at være klar, kræver dette ikke på nogen måde at ændre det originale ikke-klyngede indeks. Som et sidste eksempel skal du bemærke, at vi også kan anmode om resultater i faldende rækkefølge:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Udførelsesplanens egenskaber viser nu, at indekset scannes bagud:

Bortset fra det er planen den samme – den blev produceret på trivielle planoptimeringsstadiet og har stadig de samme anslåede omkostninger.
Omskrivning af forespørgslen
Der er ikke noget galt med den tidligere forespørgsel eller udførelsesplan, men vi har måske valgt at udtrykke forespørgslen anderledes:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Det er klart, at denne formular specificerer nøjagtigt de samme resultater som originalen, og faktisk producerer den nye forespørgsel den samme eksekveringsplan (triviel plan, flere søgninger i én, samme estimerede pris). OR-formularen gør det måske lidt tydeligere, at resultatet er en kombination af resultaterne for de seks individuelle produkt-id'er, hvilket kan få os til at prøve en anden variant, der gør denne idé endnu mere eksplicit:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Udførelsesplanen for UNION ALL-forespørgslen er helt anderledes:
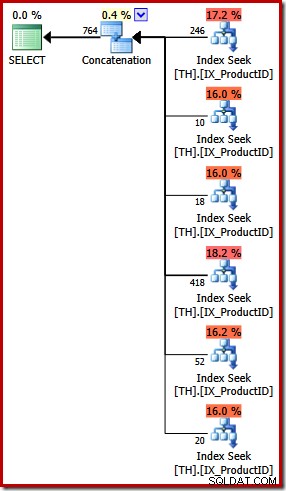
Bortset fra de åbenlyse visuelle forskelle krævede denne plan omkostningsbaseret (FULD) optimering (den kvalificerede sig ikke til en triviel plan), og de anslåede omkostninger er (relativt set) en del højere, omkring 0,02> enheder mod omkring 0,005 enheder før.
Dette går tilbage til mine indledende bemærkninger:forespørgselsoptimeringsværktøjet kender ikke til enhver logisk ækvivalens og kan ikke altid genkende alternative forespørgsler som angiver de samme resultater. Pointen, jeg gør på dette stadium, er, at udtrykket af denne særlige forespørgsel ved hjælp af UNION ALL frem for IN resulterede i en mindre optimal eksekveringsplan.
Andet eksempel
Dette eksempel vælger et andet sæt af seks produkt-id'er og anmoder om resultater i transaktions-id-ordre:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Vores ikke-klyngede indeks kan ikke levere rækker i den anmodede rækkefølge, så forespørgselsoptimeringsværktøjet har et valg at vælge mellem at søge på det ikke-klyngede indeks og sortere eller scanne det klyngede indeks (som er indtastet på transaktions-id alene) og anvende produkt-id-prædikaterne som en rest. De angivne produkt-id'er har tilfældigvis en lavere selektivitet end det forrige sæt, så optimeringsværktøjet vælger en klynget indeksscanning i dette tilfælde:
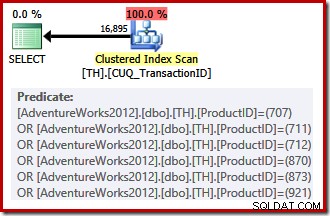
Fordi der er et omkostningsbaseret valg at træffe, kvalificerede denne udførelsesplan ikke til en triviel plan. De anslåede omkostninger ved den endelige plan er omkring 0,714 enheder. Scanning af det klyngede indeks kræver 797 logiske læsninger på udførelsestidspunktet.
Måske overrasket over, at forespørgslen ikke brugte produktindekset, kan vi prøve at fremtvinge en søgning af det ikke-klyngede indeks ved hjælp af et indekstip eller ved at angive FORCESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
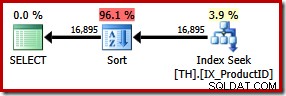
Dette resulterer i en eksplicit sortering efter transaktions-id. Den nye sortering anslås at udgøre 96 % af den nye plans 1.15 enhedspris. Denne højere estimerede pris forklarer, hvorfor optimizeren valgte den tilsyneladende billigere clustered index scan, når den blev overladt til sine egne enheder. I/O-omkostningerne for den nye forespørgsel er dog lavere:når den udføres, bruger indekssøgningen kun 49 logiske læsninger (ned fra 797).
Vi har måske også valgt at udtrykke denne forespørgsel ved hjælp af (den tidligere mislykkede) UNION ALL-idé:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Den producerer følgende udførelsesplan (klik på billedet for at forstørre i et nyt vindue):

Denne plan kan virke mere kompleks, men den har en anslået pris på kun 0,099 enheder, hvilket er meget lavere end den klyngede indeksscanning (0,714 enheder) eller søg plus sortering (1,15 enheder). Derudover bruger den nye plan kun 49 logiske læsninger på udførelsestidspunktet – det samme som søg + sorteringsplanen og meget lavere end de 797, der er nødvendige for den klyngede indeksscanning.
Denne gang gav det at udtrykke forespørgslen ved hjælp af UNION ALL en meget bedre plan, både med hensyn til estimerede omkostninger og logiske læsninger. Kildedatasættet er en smule for lille til at kunne foretage en virkelig meningsfuld sammenligning mellem forespørgselsvarigheder eller CPU-brug, men den klyngede indeksscanning tager dobbelt så lang tid (26 ms) som de to andre på mit system.
Den ekstra sortering i den antydede plan er sandsynligvis harmløs i dette simple eksempel, fordi det er usandsynligt, at det spilder til disken, men mange mennesker vil alligevel foretrække UNION ALL-planen, fordi den er ikke-blokerende, undgår en hukommelsesbevilling og ikke kræver en forespørgselstip.
Konklusion
Vi har set, at forespørgselssyntaks kan påvirke den eksekveringsplan, der er valgt af optimeringsværktøjet, selvom forespørgslerne logisk angiver nøjagtig det samme resultatsæt. Den samme omskrivning (f.eks. UNION ALL) vil nogle gange resultere i en forbedring og nogle gange medføre, at en dårligere plan vælges.
Omskrivning af forespørgsler og forsøg med alternativ syntaks er en gyldig indstillingsteknik, men der er behov for en vis omhu. En risiko er, at fremtidige ændringer af produktet kan forårsage, at den anderledes forespørgselsform pludselig holder op med at producere den bedre plan, men man kan hævde, at det altid er en risiko og afbødes af test før opgradering eller brug af planvejledninger.
Der er også en risiko for at blive revet med af denne teknik: Brug af "underlige" eller "usædvanlige" forespørgselskonstruktioner for at opnå en plan, der fungerer bedre, er ofte et tegn på, at en linje er blevet krydset. Præcis hvor skelnen ligger mellem gyldig alternativ syntaks og 'usædvanlig/underlig' er nok ret subjektivt; min egen personlige guide er at arbejde med tilsvarende relationelle forespørgselsformer og at holde tingene så enkle som muligt.