I sidste uge præsenterede jeg min T-SQL :Dårlige vaner og bedste praksis-session under GroupBy-konferencen. En videogentagelse og andet materiale er tilgængeligt her:
- T-SQL:Dårlige vaner og bedste praksis
En af de ting, jeg altid nævner i den session, er, at jeg generelt foretrækker GROUP BY frem for DISTINCT, når jeg eliminerer dubletter. Selvom DISTINCT bedre forklarer hensigten, og GROUP BY kun er påkrævet, når der er aggregeringer til stede, er de i mange tilfælde udskiftelige.
Lad os starte med noget simpelt ved hjælp af Wide World Importers. Disse to forespørgsler giver det samme resultat:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
Og faktisk udlede deres resultater ved hjælp af nøjagtig den samme udførelsesplan:

Samme operatører, samme antal læsninger, ubetydelige forskelle i CPU og samlet varighed (de skiftes til at "vinde").
Så hvorfor vil jeg anbefale at bruge den ordligere og mindre intuitive GROUP BY-syntaks over DISTINCT? Nå, i dette simple tilfælde er det et møntskift. I mere komplekse tilfælde kan DISTINCT dog ende med at udføre mere arbejde. I det væsentlige indsamler DISTINCT alle rækkerne, inklusive alle udtryk, der skal evalueres, og smider derefter dubletter ud. GROUP BY kan (igen, i nogle tilfælde) bortfiltrere de duplikerede rækker før udfører noget af det arbejde.
Lad os for eksempel tale om strengaggregering. Mens du i SQL Server v.Next vil være i stand til at bruge STRING_AGG (se indlæg her og her), er vi andre nødt til at fortsætte med FOR XML PATH (og før du fortæller mig om, hvor fantastiske rekursive CTE'er er til dette, venligst læs også dette indlæg). Vi har muligvis en forespørgsel som denne, som forsøger at returnere alle ordrer fra tabellen Sales.OrderLines sammen med varebeskrivelser som en rørsepareret liste:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Dette er en typisk forespørgsel til at løse denne type problemer med følgende udførelsesplan (advarslen i alle planerne er kun for den implicitte konvertering, der kommer ud af XPath-filteret):
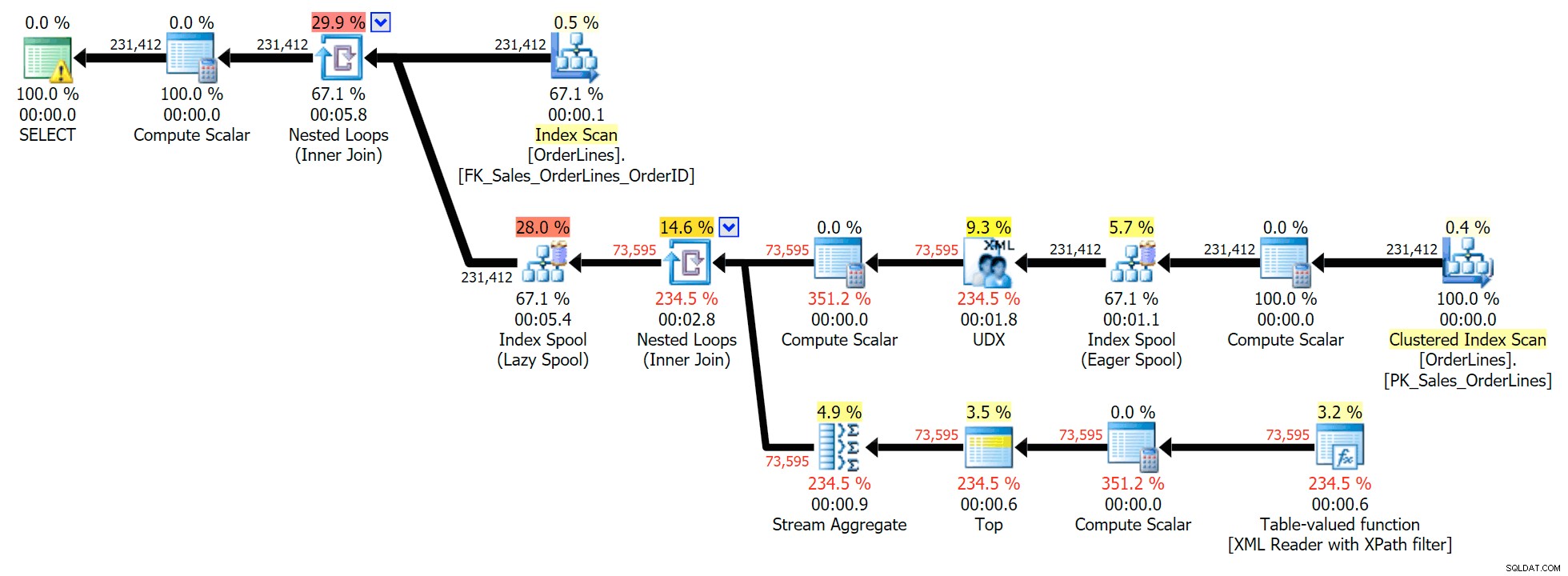
Det har dog et problem, som du måske bemærker i output-antallet af rækker. Du kan helt sikkert få øje på det, når du tilfældigt scanner output:

For hver ordre ser vi den rør-separerede liste, men vi ser en række for hver vare i hver rækkefølge. Knæfaldsreaktionen er at smide en DISTINCT på kolonnelisten:
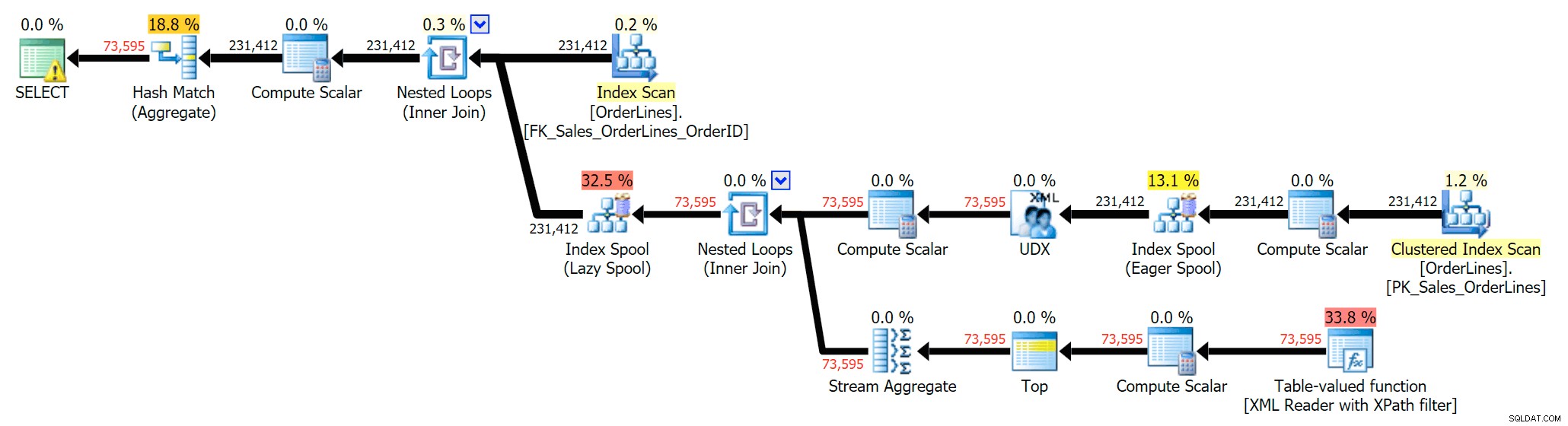
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Det eliminerer dubletterne (og ændrer bestillingsegenskaberne på scanningerne, så resultaterne ikke nødvendigvis vises i en forudsigelig rækkefølge) og producerer følgende udførelsesplan:
En anden måde at gøre dette på er at tilføje en GROUP BY for OrderID'et (da underforespørgslen ikke udtrykkeligt behøves skal refereres igen i GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Dette giver de samme resultater (selvom ordren er vendt tilbage) og en lidt anden plan:
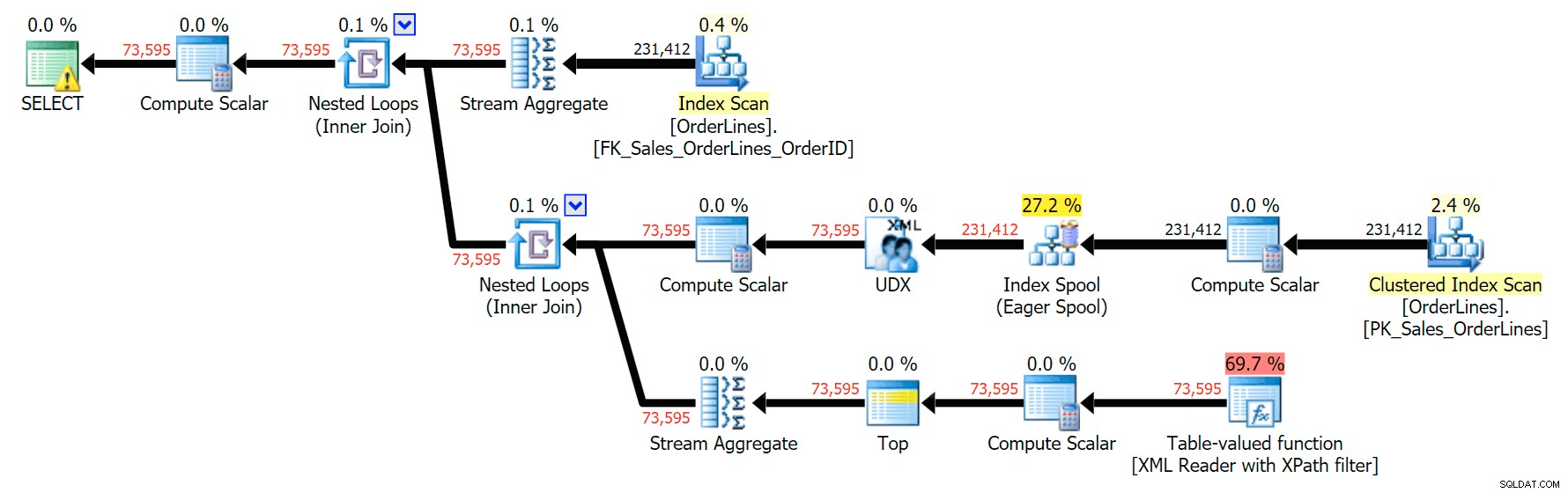
Ydeevnemålingerne er dog interessante at sammenligne.

DISTINCT-variationen tog 4X så lang tid, brugte 4X CPU'en og næsten 6X læsningerne sammenlignet med GROUP BY-variationen. (Husk, at disse forespørgsler giver nøjagtig de samme resultater.)
Vi kan også sammenligne udførelsesplanerne, når vi ændrer omkostningerne fra CPU + I/O kombineret til kun I/O, en funktion, der er eksklusiv for Plan Explorer. Vi viser også de omprissatte værdier (som er baseret på de faktiske). omkostninger observeret under udførelse af forespørgsler, en funktion som også kun findes i Plan Explorer). Her er DISTINCT-planen:
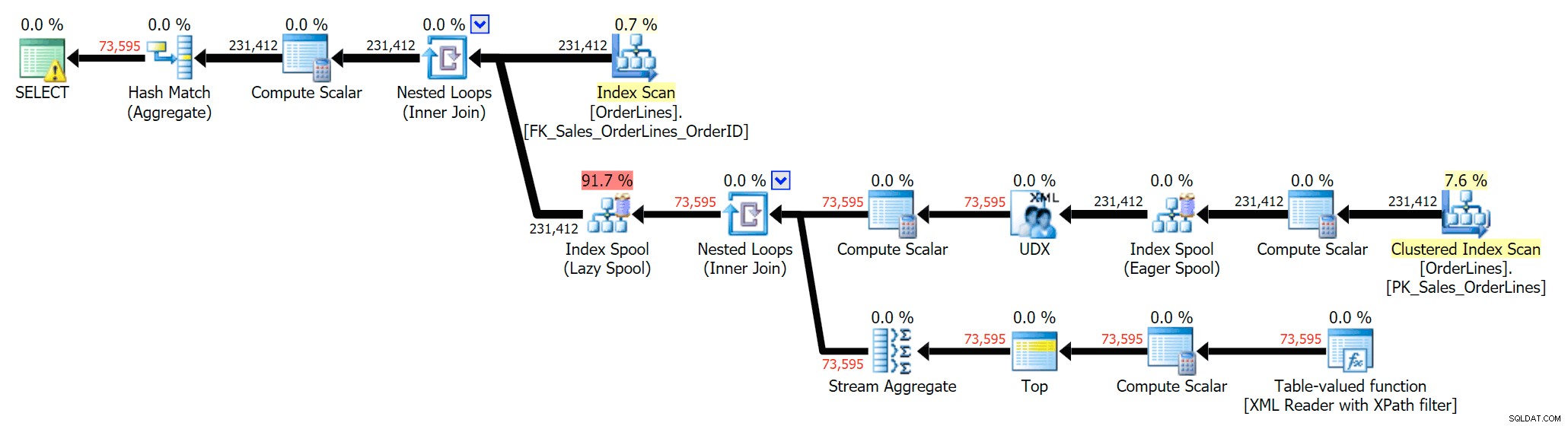
Og her er GROUP BY-planen:
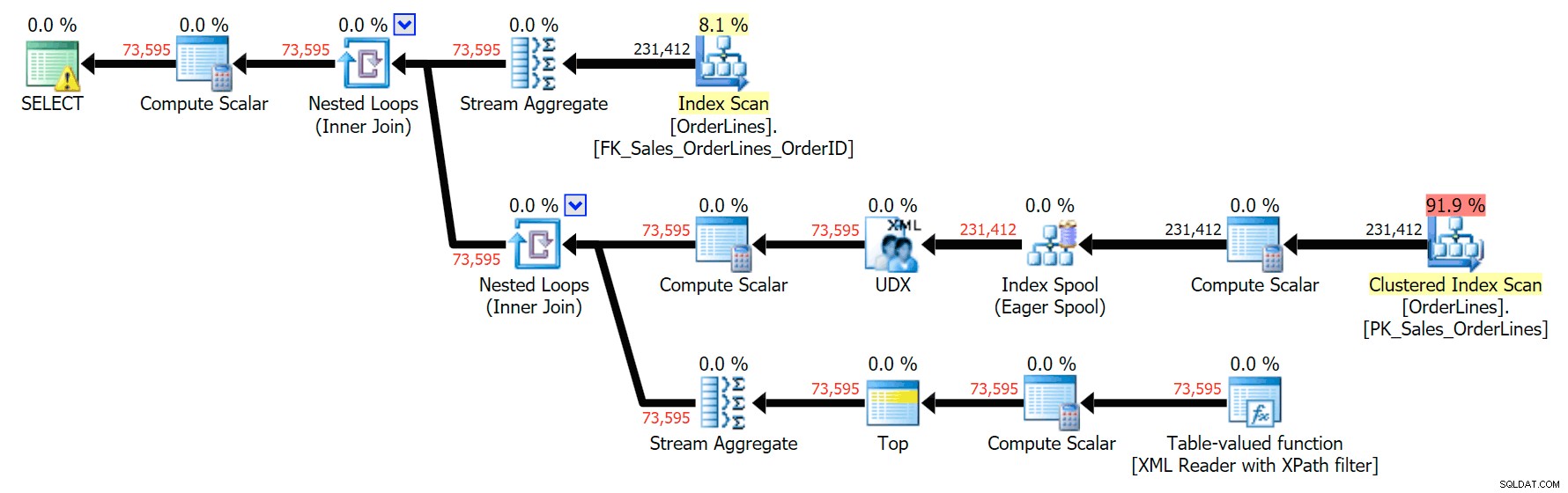
Du kan se, at i GROUP BY-planen er næsten alle I/O-omkostninger i scanningerne (her er værktøjstip til CI-scanningen, der viser en I/O-omkostning på ~3,4 "forespørgselsbukker"). Men i DISTINCT-planen er det meste af I/O-omkostningerne i indeksspolen (og her er det værktøjstip; I/O-omkostningerne her er ~41,4 "forespørgselsbukke"). Bemærk, at CPU'en også er meget højere med indeksspolen. Vi vil tale om "query bucks" en anden gang, men pointen er, at indeksspolen er mere end 10 gange så dyr som scanningen - alligevel er scanningen stadig den samme 3.4 i begge planer. Dette er en af grundene til, at det altid irriterer mig, når folk siger, at de skal "rette" operatøren i planen med de højeste omkostninger. Nogle operatører i planen vil altid være den dyreste; det betyder ikke, at det skal rettes.
@AaronBertrand disse forespørgsler er ikke rigtig logisk ækvivalente — DISTINCT er på begge kolonner, hvorimod din GROUP BY kun er på den ene
— Adam Machanic (@AdamMachanic) 20. januar 2017
Mens Adam Machanic har ret, når han siger, at disse forespørgsler er semantisk forskellige, er resultatet det samme – vi får det samme antal rækker, der indeholder nøjagtig de samme resultater, og vi gjorde det med langt færre læsninger og CPU.
Så selvom DISTINCT og GROUP BY er identiske i mange scenarier, er her et tilfælde, hvor GROUP BY-tilgangen helt sikkert fører til bedre ydeevne (på bekostning af mindre klar deklarativ hensigt i selve forespørgslen). Jeg ville være interesseret i at vide, om du synes, der er nogle scenarier, hvor DISTINCT er bedre end GROUP BY, i det mindste med hensyn til ydeevne, hvilket er langt mindre subjektivt end stil, eller om et udsagn skal være selvdokumenterende.
Dette indlæg passer ind i min "overraskelser og antagelser"-serier, fordi mange ting, vi holder som sandheder baseret på begrænsede observationer eller særlige tilfælde, kan testes, når de bruges i andre scenarier. Vi skal bare huske at tage os tid til at gøre det som en del af SQL-forespørgselsoptimering...
Referencer
- Grupperet sammenkædning i SQL Server
- Gruppert sammenkædning:Bestilling og fjernelse af dubletter
- Fire praktiske anvendelsessager til grupperet sammenkædning
- SQL Server v.Next:STRING_AGG() ydeevne
- SQL Server v.Next :STRING_AGG Performance, del 2