Et præstationsproblem, jeg ofte ser, er, når brugere skal matche en del af en streng med en forespørgsel som følgende:
... WHERE SomeColumn LIKE N'%SomePortion%';
Med et ledende jokertegn er dette prædikat "ikke-SARGable" – bare en fancy måde at sige, at vi ikke kan finde de relevante rækker ved at bruge en søgning mod et indeks på SomeColumn .
En løsning, vi bliver lidt bølgende over, er fuldtekstsøgning; dette er dog en kompleks løsning, og det kræver, at søgemønsteret består af hele ord, ikke bruger stopord, og så videre. Dette kan hjælpe, hvis vi leder efter rækker, hvor en beskrivelse indeholder ordet "blødt" (eller andre afledninger som "blødere" eller "blødt"), men det hjælper ikke, når vi leder efter strenge, der kunne være indeholdt i ord (eller som slet ikke er ord, som alle produkt-SKU'er, der indeholder "X45-B" eller alle nummerplader, der indeholder sekvensen "7RA").
Hvad hvis SQL Server på en eller anden måde vidste om alle de mulige dele af en streng? Min tankeproces er i stil med trigram / trigraph i PostgreSQL. Det grundlæggende koncept er, at motoren har evnen til at lave punkt-stil opslag på understrenge, hvilket betyder, at du ikke behøver at scanne hele tabellen og analysere hver fuld værdi.
Det specifikke eksempel, de bruger der, er ordet cat . Ud over det fulde ord kan det opdeles i dele:c , ca og at (de udelader a og t per definition – ingen efterfølgende understreng kan være kortere end to tegn). I SQL Server behøver vi ikke, at det er så komplekst; vi har kun brug for halvdelen af trigrammet – hvis vi tænker på at bygge en datastruktur, der indeholder alle understrengene af cat , vi har kun brug for disse værdier:
- kat
- på
- t
Vi har ikke brug for c eller ca , fordi alle, der søger efter LIKE '%ca%' kunne nemt finde værdi 1 ved at bruge LIKE 'ca%' i stedet. På samme måde kan enhver, der søger efter LIKE '%at%' eller LIKE '%a%' kunne kun bruge et efterfølgende jokertegn mod disse tre værdier og finde den, der matcher (f.eks. LIKE 'at%' vil finde værdi 2 og LIKE 'a%' vil også finde værdi 2, uden at skulle finde disse understrenge inde i værdi 1, som er hvor den virkelige smerte ville komme fra).
Så i betragtning af at SQL Server ikke har noget lignende indbygget, hvordan genererer vi sådan et trigram?
En separat fragmenttabel
Jeg vil stoppe med at referere til "trigram" her, fordi dette ikke er rigtigt analogt med den funktion i PostgreSQL. Grundlæggende er det, vi skal gøre, at bygge en separat tabel med alle "fragmenterne" af den originale streng. (Så i cat for eksempel ville der være en ny tabel med disse tre rækker og LIKE '%pattern%' søgninger vil blive rettet mod den nye tabel som LIKE 'pattern%' prædikater.)
Før jeg begynder at vise, hvordan min foreslåede løsning ville fungere, så lad mig være helt klar over, at denne løsning ikke bør bruges i hvert enkelt tilfælde, hvor LIKE '%wildcard%' søgninger er langsomme. På grund af den måde, vi kommer til at "eksplodere" kildedataene i fragmenter, er det sandsynligvis begrænset i praksis til mindre strenge, såsom adresser eller navne, i modsætning til større strenge, såsom produktbeskrivelser eller sessionsabstrakt.
Et mere praktisk eksempel end cat er at se på Sales.Customer tabel i WideWorldImporters eksempeldatabase. Den har adresselinjer (begge nvarchar(60) ), med de værdifulde adresseoplysninger i kolonnen DeliveryAddressLine2 (af ukendte årsager). Nogen leder måske efter nogen, der bor på en gade ved navn Hudecova , så de vil køre en søgning som denne:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ Som du ville forvente, skal SQL Server udføre en scanning for at finde disse to rækker. Hvilket burde være enkelt; men på grund af tabellens kompleksitet giver denne trivielle forespørgsel en meget rodet udførelsesplan (scanningen er fremhævet og har en advarsel om resterende I/O):
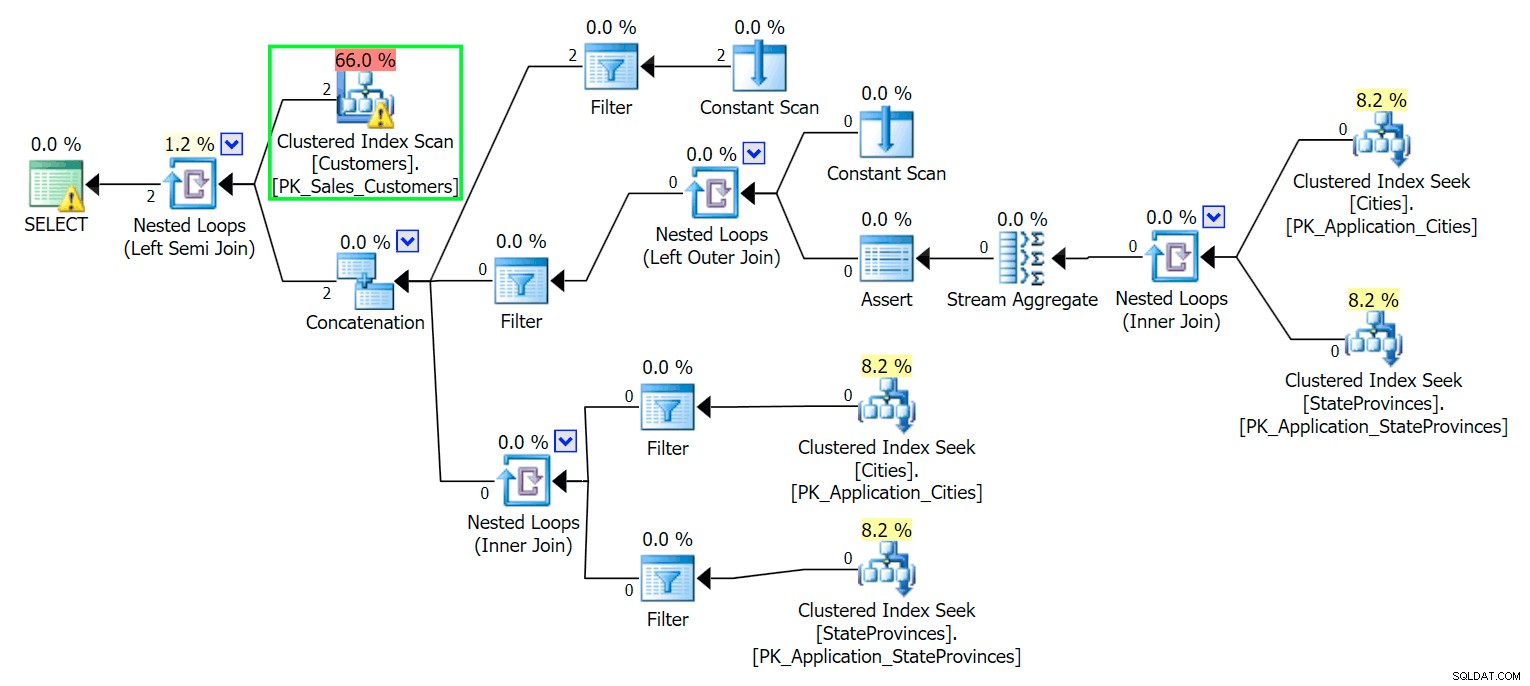
Blecch. For at holde vores liv enkelt, og for at sikre, at vi ikke jagter en flok røde sild, lad os oprette en ny tabel med en undergruppe af kolonnerne, og for at starte indsætter vi bare de samme to rækker fra oven:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
Nu, hvis vi kører den samme forespørgsel, som vi kørte mod hovedtabellen, får vi noget meget mere fornuftigt at se på som udgangspunkt. Dette vil stadig være en scanning, uanset hvad vi gør – hvis vi tilføjer et indeks med DeliveryAddressLine2 som den ledende nøglekolonne får vi højst sandsynligt en indeksscanning med et nøgleopslag afhængigt af om indekset dækker kolonnerne i forespørgslen. Som den er, får vi en klynget indeksscanning:
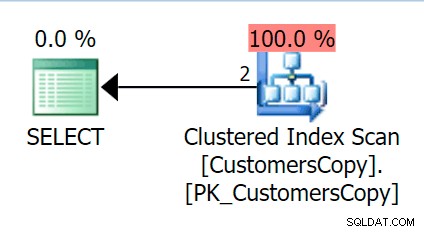
Lad os derefter oprette en funktion, der vil "eksplodere" disse adresseværdier i fragmenter. Vi ville forvente 1846 Hudecova Crescent , for eksempel at have følgende sæt fragmenter:
- 1846 Hudecova Halvmåne
- 846 Hudecova Halvmåne
- 46 Hudecova Halvmåne
- 6 Hudecova Halvmåne
- Hudecova Halvmåne
- Hudecova Halvmåne
- udecova Halvmåne
- decova Halvmåne
- ecova Halvmåne
- cova Halvmåne
- æg Halvmåne
- va Halvmåne
- en halvmåne
- Halvmåne
- halvmåne
- nylig
- escent
- duft
- cent
- ent
- nt
- t
Det er ret trivielt at skrive en funktion, der vil producere dette output – vi har bare brug for en rekursiv CTE, der kan bruges til at gå gennem hvert tegn i hele inputtet:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Lad os nu oprette en tabel, der gemmer alle adressefragmenterne, og hvilken kunde de tilhører:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Så kan vi udfylde det sådan her:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
For vores to værdier indsætter dette 42 rækker (den ene adresse har 20 tegn, og den anden har 22). Nu bliver vores forespørgsel:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Her er en meget pænere plan – to klyngede indeks *søger* og en indlejret sløjfe forbinder sig:
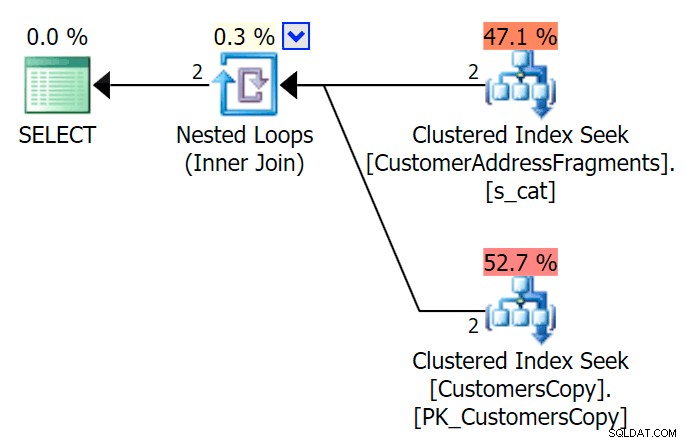
Vi kan også gøre dette på en anden måde ved at bruge EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Her er den plan, som på overfladen ser ud til at være dyrere - den vælger at scanne CustomersCopy-tabellen. Vi vil snart se, hvorfor dette er den bedre forespørgselstilgang:
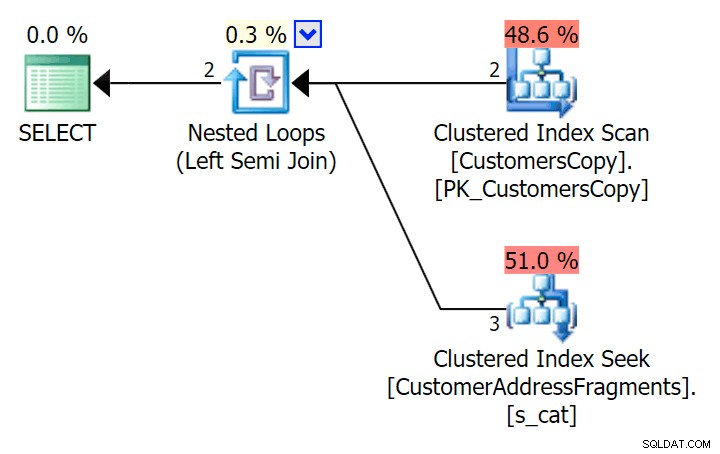
Nu, på dette massive datasæt på 42 rækker, er forskellene set i varighed og I/O så små, at de er irrelevante (og faktisk ser scanningen mod basistabellen billigere ud med hensyn til I/O i denne lille størrelse). O end de to andre planer, der bruger fragmenttabellen):

Hvad hvis vi skulle udfylde disse tabeller med meget flere data? Min kopi af Sales.Customers har 663 rækker, så hvis vi krydser det med sig selv, ville vi få et sted i nærheden af 440.000 rækker. Så lad os bare samle 400K og generere en meget større tabel:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
For nu at sammenligne ydeevne- og udførelsesplaner givet en række mulige søgeparametre, testede jeg ovenstående tre forespørgsler med disse prædikater:
| Forespørgsel | prædikater | ||||
|---|---|---|---|---|---|
| HVOR DeliveryLineAddress2 LIKE … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| JOIN … HVOR Fragment LIKE … | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| HVOR FINNES (… HVOR Fragment LIKE …) | |||||
Når vi fjerner bogstaver fra søgemønsteret, ville jeg forvente at se flere rækker output og måske forskellige strategier valgt af optimeringsværktøjet. Lad os se, hvordan det gik for hvert mønster:
Hudecova%
For dette mønster var scanningen stadig den samme for LIKE-tilstanden; men med flere data er omkostningerne meget højere. Søgningerne i fragmenttabellen betaler sig virkelig ved dette rækkeantal (1.206), selv med virkelig lave estimater. EXISTS-planen tilføjer en særskilt sortering, som du ville forvente at tilføje til omkostningerne, selvom den i dette tilfælde ender med at læse færre:

 Plan for JOIN til fragmenttabellen
Plan for JOIN til fragmenttabellen 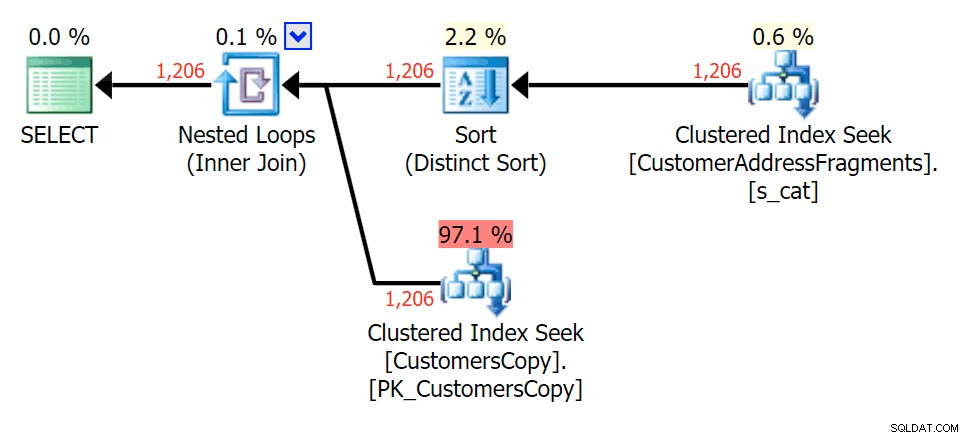 Plan for EXISTS mod fragmenttabellen
Plan for EXISTS mod fragmenttabellen cova%
Efterhånden som vi fjerner nogle bogstaver fra vores prædikat, ser vi læsningerne faktisk en smule højere end med den originale clustered index-scanning, og nu er vi over - estimere rækkerne. Alligevel forbliver vores varighed væsentligt lavere med begge fragmentforespørgsler; forskellen denne gang er mere subtil – begge har sorter (kun EKSISTERER er forskellig):

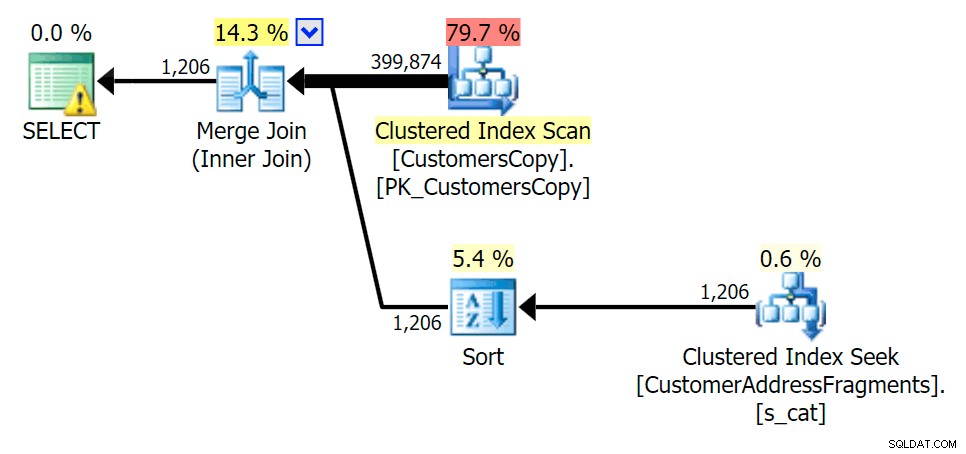 Plan for JOIN til fragmenttabellen
Plan for JOIN til fragmenttabellen 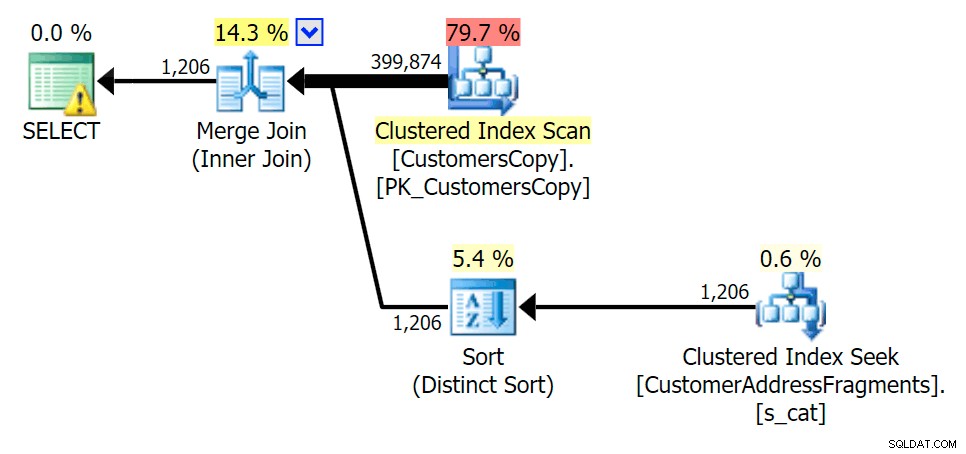 Plan for EXISTS mod fragmenttabellen
Plan for EXISTS mod fragmenttabellen ova%
At fjerne et ekstra bogstav ændrede ikke meget; selvom det er værd at bemærke, hvor meget de estimerede og faktiske rækker hopper her - hvilket betyder, at dette kan være et almindeligt delstrengmønster. Den originale LIKE-forespørgsel er stadig en del langsommere end fragmentforespørgslerne.

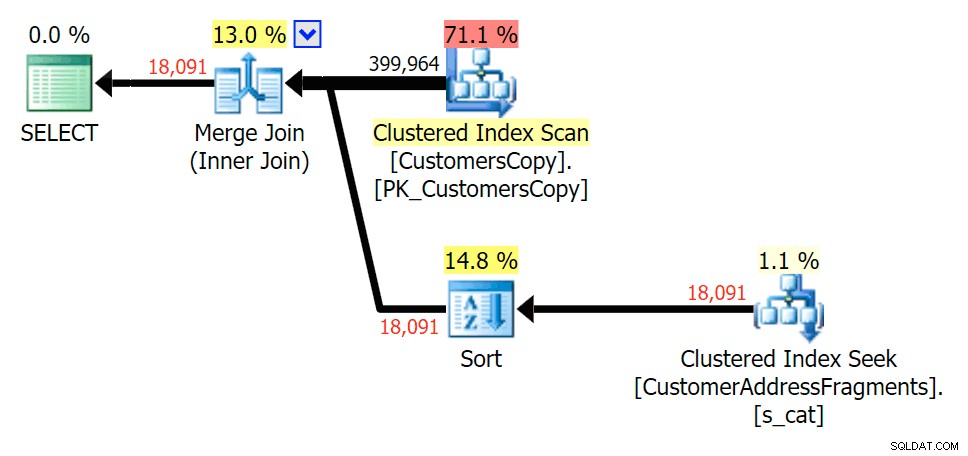 Plan for JOIN til fragmenttabellen
Plan for JOIN til fragmenttabellen 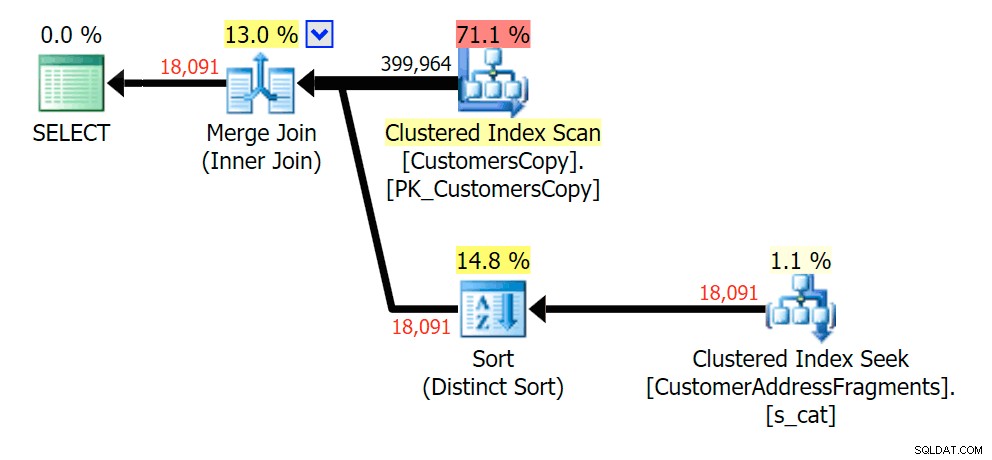 Plan for EXISTS mod fragmenttabellen
Plan for EXISTS mod fragmenttabellen va%
Ned til to bogstaver introducerer dette vores første uoverensstemmelse. Bemærk, at JOIN producerer mere rækker end den oprindelige forespørgsel eller EXISTS. Hvorfor skulle det være det?

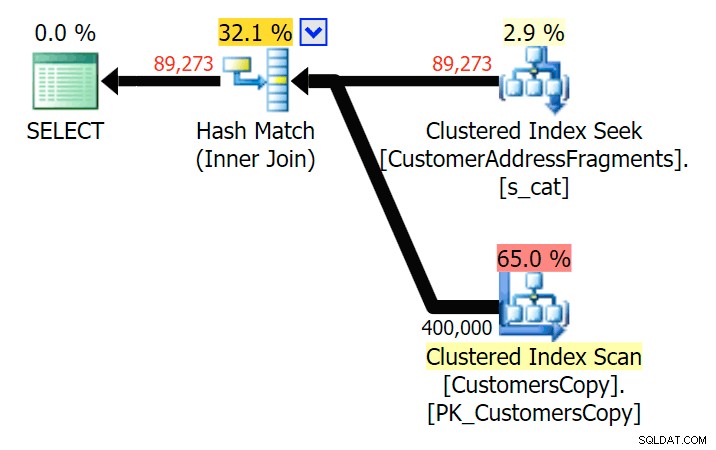 Plan for JOIN til fragmenttabellen
Plan for JOIN til fragmenttabellen 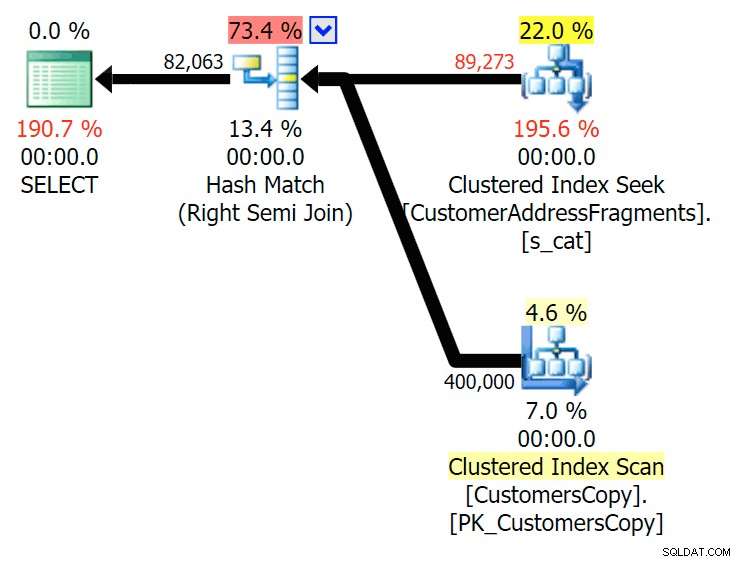 Plan for EXISTS mod fragmenttabellen Vi skal ikke lede langt. Husk, at der er et fragment, der starter fra hvert efterfølgende tegn i den oprindelige adresse, hvilket betyder noget i stil med
Plan for EXISTS mod fragmenttabellen Vi skal ikke lede langt. Husk, at der er et fragment, der starter fra hvert efterfølgende tegn i den oprindelige adresse, hvilket betyder noget i stil med 899 Valentova Road vil have to rækker i fragmenttabellen, der starter med va (kassefølsomhed til side). Så du matcher på begge Fragment = N'Valentova Road' og Fragment = N'va Road' . Jeg sparer dig for søgningen og giver et enkelt eksempel af mange: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Dette forklarer let, hvorfor JOIN producerer flere rækker; hvis du vil matche outputtet fra den originale LIKE-forespørgsel, skal du bruge EXISTS. At de korrekte resultater som regel også kan opnås på en mindre ressourcekrævende måde er blot en bonus. (Jeg ville være nervøs for at se folk vælge JOIN, hvis det var den gentagne gange mere effektive mulighed – du bør altid foretrække korrekte resultater frem for at bekymre dig om ydeevne.)
Oversigt
Det er klart, at i dette specifikke tilfælde – med en adressekolonne nvarchar(60) og en maks. længde på 26 tegn – at opdele hver adresse i fragmenter kan give en vis lettelse for ellers dyre "ledende jokertegn"-søgninger. Jo bedre udbytte ser ud til at ske, når søgemønsteret er større og som et resultat mere unikt. Jeg har også demonstreret, hvorfor EXISTS er bedre i scenarier, hvor flere matches er mulige – med en JOIN vil du få redundant output, medmindre du tilføjer nogle "største n pr. gruppe"-logik.
Forbehold
Jeg vil være den første til at indrømme, at denne løsning er ufuldkommen, ufuldstændig og ikke grundigt udfyldt:
- Du bliver nødt til at holde fragmenttabellen synkroniseret med basistabellen ved hjælp af triggere – det enkleste ville være for indsættelser og opdateringer, slet alle rækker for disse kunder og genindsæt dem, og for sletninger skal du naturligvis fjerne rækkerne fra fragmenterne bord.
- Som nævnt fungerede denne løsning bedre til denne specifikke datastørrelse og gør sig muligvis ikke så godt til andre strenglængder. Det ville berettige yderligere test for at sikre, at det passer til din kolonnestørrelse, gennemsnitlige værdilængde og typiske søgeparameterlængde.
- Da vi vil have mange kopier af fragmenter som "Crescent" og "Street" (gled med de samme eller lignende gadenavne og husnumre), kunne vi normalisere det yderligere ved at gemme hvert unikt fragment i en fragmenttabel, og så endnu en tabel, der fungerer som en mange-til-mange krydstabel. Det ville være meget mere besværligt at sætte op, og jeg er ikke helt sikker på, at der ville være meget at vinde.
- Jeg har ikke helt undersøgt sidekomprimering endnu, det ser ud til, at dette – i hvert fald i teorien – kunne give en vis fordel. Jeg har også en fornemmelse af, at en kolonnebutikimplementering også kan være gavnlig i nogle tilfælde.
Alligevel, når det er sagt, ville jeg bare dele det som en udviklende idé og anmode om enhver feedback om dens praktiske funktion til specifikke brugstilfælde. Jeg kan grave i flere detaljer til et fremtidigt indlæg, hvis du kan fortælle mig, hvilke aspekter af denne løsning der interesserer dig.