@rob_farley din seneste stackoverflow-løsning til at bestille efter en værdi først, derefter er et felt geni! Vil gerne takke dig personligt.
— Joel Sacco (@Jsac90) 11. august 2016
Jeg så dette tweet komme igennem...
Og det fik mig til at se på, hvad det refererede til, for jeg havde ikke skrevet noget 'for nylig' på StackOverflow om bestilling af data. Det viste sig, at det var dette svar, jeg havde skrevet , som selvom det ikke var det accepterede svar, har samlet over hundrede stemmer.
Den person, der stillede spørgsmålet, havde et meget simpelt problem - at ville få bestemte rækker til at blive vist først. Og min løsning var enkel:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Det ser ud til at have været et populært svar, også for Joel Sacco (ifølge ovenstående tweet).
Tanken er at danne et udtryk, og bestille efter det. ORDER BY er ligeglad med, om det er en egentlig kolonne eller ej. Du kunne have gjort det samme ved at bruge APPLY, hvis du virkelig foretrækker at bruge en 'kolonne' i din ORDER BY-klausul.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Hvis jeg bruger nogle forespørgsler mod WideWorldImporters, kan jeg vise dig, hvorfor disse to forespørgsler virkelig er nøjagtig de samme. Jeg vil forespørge i Sales.Orders-tabellen og bede om, at Orders for Salesperson 7 vises først. Jeg vil også oprette et passende dækkende indeks:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Planerne for disse to forespørgsler ser identiske ud. De udfører identisk - samme læsninger, samme udtryk, de er virkelig den samme forespørgsel. Hvis der er en lille forskel i den faktiske CPU eller varighed, så er det et lykketræf på grund af andre faktorer.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
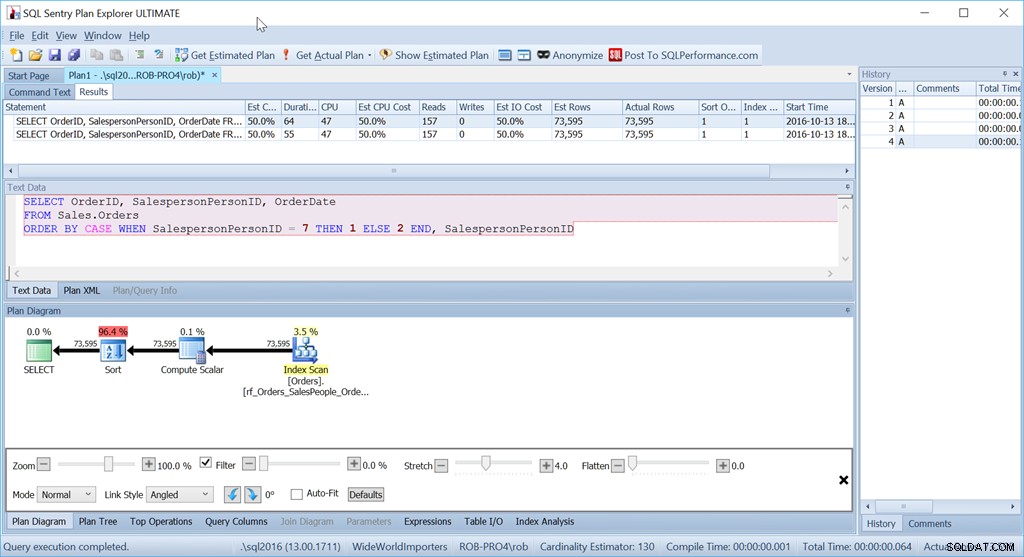
Og alligevel er det ikke den forespørgsel, jeg faktisk ville bruge i denne situation. Ikke hvis præstation var vigtig for mig. (Det er det normalt, men det er ikke altid værd at skrive en forespørgsel den lange vej, hvis mængden af data er lille.)
Det, der generer mig, er den Sort-operatør. Det er 96,4% af prisen!
Overvej om vi blot ønsker at bestille efter SalespersonPersonID:
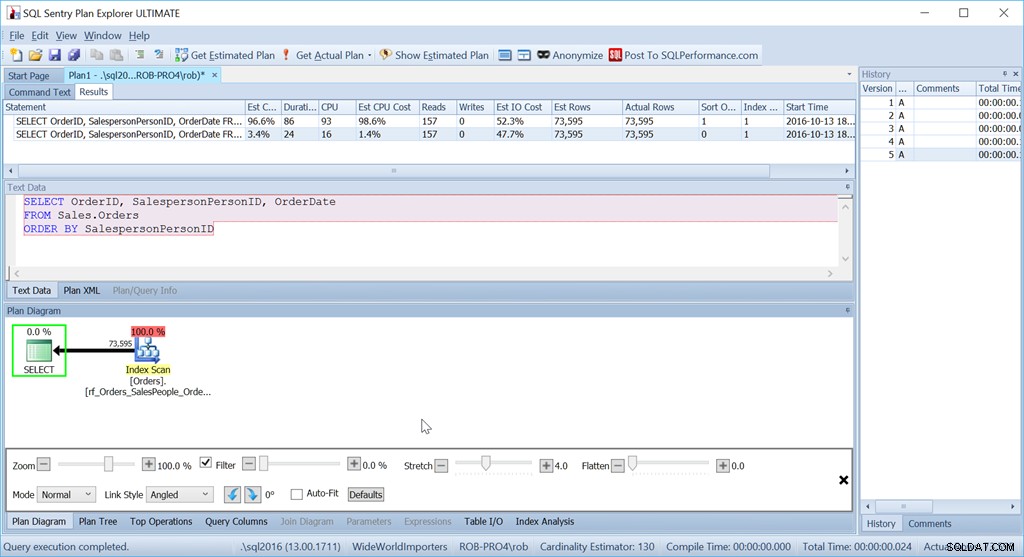
Vi ser, at denne simplere forespørgsels estimerede CPU-omkostning er 1,4 % af batchen, mens den specialsorterede version er 98,6 %. Det er 70 GANGE værre. Læsningerne er dog de samme – det er godt. Varigheden er langt værre, og det samme er CPU.
Jeg er ikke vild med Sorts. De kan være grimme.
En mulighed, jeg har her, er at tilføje en beregnet kolonne til min tabel og indeksere den, men det vil have en indvirkning på alt, der søger efter alle kolonnerne i tabellen, såsom ORM'er, Power BI eller noget, der gør SELECT * . Så det er ikke så fantastisk (selvom hvis vi nogensinde kommer til at tilføje skjulte beregnede kolonner, ville det være en rigtig god mulighed her).
En anden mulighed, som er mere omstændelig (nogle vil måske foreslå, at det ville passe mig – og hvis du troede det:Oi! Vær ikke så uhøflig!), og bruger flere læsninger, er at overveje, hvad vi ville gøre i det virkelige liv, hvis vi var nødt til at gøre dette.
Hvis jeg havde en bunke på 73.595 ordrer, sorteret efter sælgerordre, og jeg skulle returnere dem med en bestemt sælger først, ville jeg ikke se bort fra den rækkefølge, de var i og simpelthen sortere dem alle, jeg ville starte med at dykke ind og finde dem til Sælger 7 – holde dem i den rækkefølge, de var i. Så ville jeg finde dem, der ikke var dem, der ikke var Sælger 7 – ved at sætte dem efter, og igen holde dem i den rækkefølge, de allerede var ind.
I T-SQL gøres det sådan:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Dette får to sæt data og sammenkæder dem. Men Query Optimizer kan se, at den skal vedligeholde SalespersonPersonID-rækkefølgen, når de to sæt er sammenkædet, så den udfører en særlig form for sammenkædning, der opretholder denne rækkefølge. Det er en Merge Join (Concatenation) join, og planen ser sådan ud:
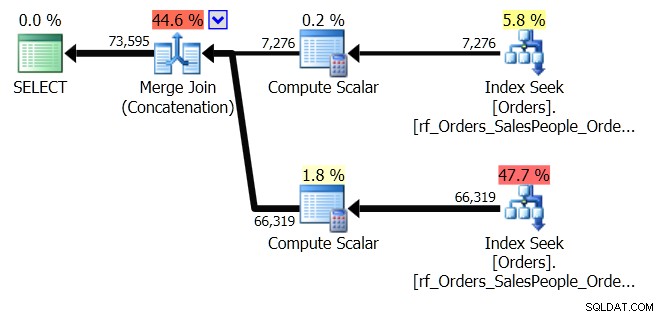
Du kan se, det er meget mere kompliceret. Men forhåbentlig vil du også bemærke, at der ikke er nogen sorteringsoperatør. Merge Join (sammenkædning) trækker dataene fra hver gren og producerer et datasæt, som er i den rigtige rækkefølge. I dette tilfælde vil den trække alle 7.276 rækker for sælger 7 først og derefter trække de andre 66.319, fordi det er den påkrævede rækkefølge. Inden for hvert sæt er dataene i SalespersonPersonID-rækkefølge, som vedligeholdes, efterhånden som dataene strømmer igennem.
Jeg nævnte tidligere, at den bruger flere læsninger, og det gør den. Hvis jeg viser SET STATISTICS IO-outputtet og sammenligner de to forespørgsler, ser jeg dette:
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.Tabel 'Ordre'. Scanningsantal 1, logisk læser 157, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Ordre '. Scanningsantal 3, logisk læser 163, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Ved at bruge "Custom Sort"-versionen er det kun en scanning af indekset, der bruger 157 læsninger. Ved at bruge "Union All"-metoden er det tre scanninger – en for SalespersonPersonID =7, en for SalespersonPersonID <7 og en for SalespersonPersonID> 7. Vi kan se de to sidste ved at se på egenskaberne for den anden Index Seek:
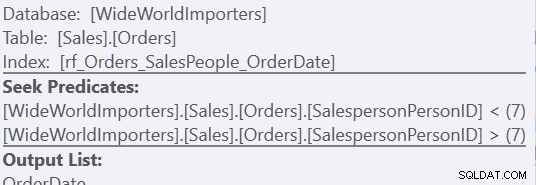
For mig kommer fordelen dog igennem manglen på et arbejdsbord.
Se på de anslåede CPU-omkostninger:

Det er ikke så lille som vores 1,4 %, når vi helt undgår sorteringen, men det er stadig en stor forbedring i forhold til vores Custom Sort-metode.
Men en advarsel...
Antag, at jeg havde oprettet det indeks anderledes og havde OrderDate som en nøglekolonne i stedet for som en inkluderet kolonne.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
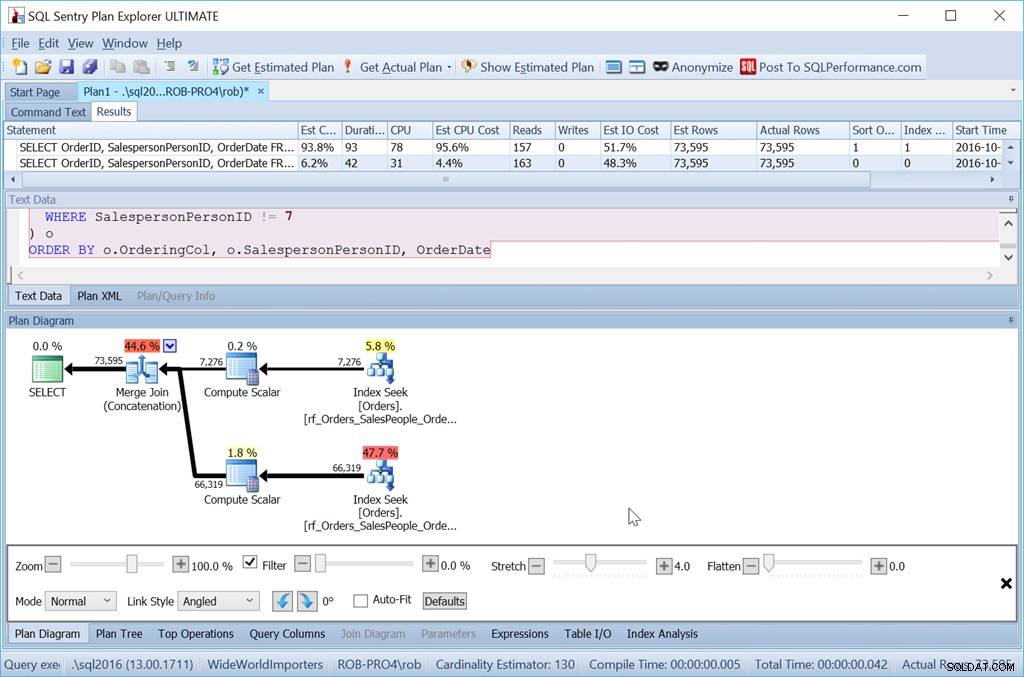
Nu virker min "Union All" metode slet ikke efter hensigten.
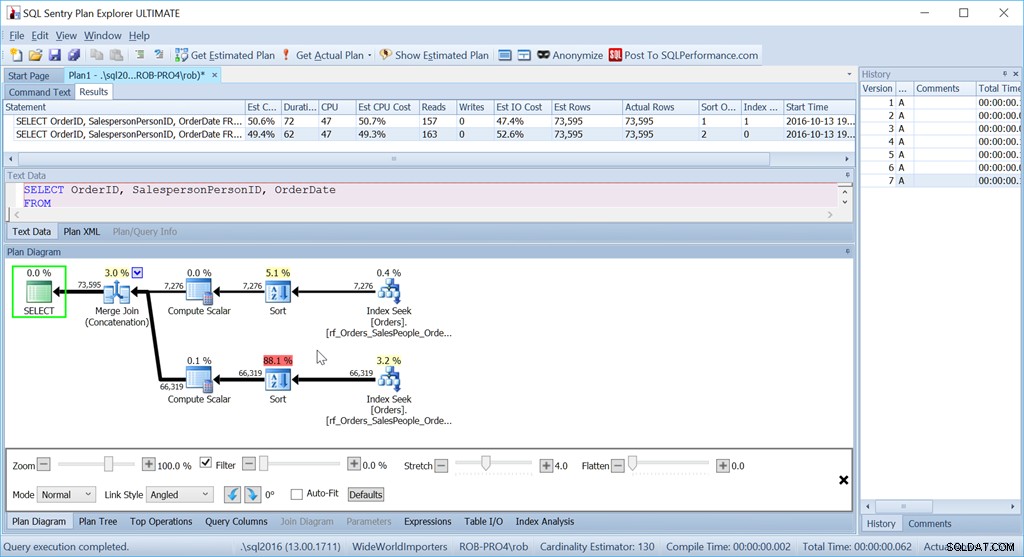
På trods af at jeg brugte nøjagtig de samme forespørgsler som før, har min gode plan nu to sorteringsoperatorer, og den klarer sig næsten lige så dårligt som min originale Scan + Sort-version.
Årsagen til dette er et særpræg ved Merge Join (Concatenation)-operatoren, og ledetråden er i Sort-operatoren.

Det er bestilling efter SalespersonPersonID efterfulgt af OrderID – som er den grupperede indeksnøgle i tabellen. Den vælger dette, fordi dette er kendt for at være unikt, og det er et mindre sæt kolonner at sortere efter end SalespersonPersonID efterfulgt af OrderDate efterfulgt af OrderID, som er datasættets rækkefølge, der produceres af tre indeksområdescanninger. En af de gange, hvor Query Optimizer ikke bemærker en bedre mulighed, der er lige der.
Med dette indeks ville vi også have brug for vores datasæt ordnet efter OrderDate for at producere vores foretrukne plan.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
Så det er bestemt mere indsats. Forespørgslen er længere for mig at skrive, den er mere læst, og jeg skal have et indeks uden ekstra nøglekolonner. Men det er bestemt hurtigere. Med endnu flere rækker er påvirkningen endnu større, og jeg skal heller ikke risikere, at en Sort spilder til tempdb.
For små sæt er mit StackOverflow-svar stadig godt. Men når den sorteringsoperatør koster mig i ydeevne, så bruger jeg metoden Union All / Merge Join (sammenkædning).