TimescaleDB er en open source-database opfundet for at gøre SQL skalerbar til tidsseriedata. Det er et relativt nyt databasesystem. TimescaleDB er blevet introduceret på markedet for to år siden og nåede version 1.0 i september 2018. Ikke desto mindre er det konstrueret oven på et modent RDBMS-system.
TimescaleDB er pakket som en PostgreSQL-udvidelse. Al kode er licenseret under Apache-2 open source-licensen, med undtagelse af noget kildekode relateret til tidsserievirksomhedsfunktioner, der er licenseret under Timescale License (TSL).
Som en tidsseriedatabase giver den automatisk opdeling på tværs af dato og nøgleværdier. TimescaleDB native SQL-understøttelse gør det til en god mulighed for dem, der planlægger at gemme tidsseriedata og allerede har solid SQL-sprogkendskab.
Hvis du leder efter en tidsseriedatabase, der kan bruge rig SQL, HA, en solid backup-løsning, replikering og andre virksomhedsfunktioner, kan denne blog sætte dig på rette vej.
Hvornår skal TimescaleDB bruges
Før vi starter med TimescaleDB-funktioner, lad os se, hvor det kan passe. TimescaleDB blev designet til at tilbyde det bedste fra både relationel og NoSQL, med fokus på tidsserier. Men hvad er tidsseriedata?
Tidsseriedata er kernen i Internet of Things, overvågningssystemer og mange andre løsninger med fokus på hyppigt skiftende data. Som navnet "tidsserier" antyder, taler vi om data, der ændrer sig med tiden. Mulighederne for en sådan type DBMS er uendelige. Du kan bruge det i forskellige industrielle IoT-brugssager på tværs af fremstilling, minedrift, olie og gas, detailhandel, sundhedspleje, udviklingsovervågning eller finansiel informationssektor. Det kan også i høj grad passe ind i maskinlæringspipelines eller som en kilde til forretningsdrift og intelligens.
Der er ingen tvivl om, at efterspørgslen efter IoT og lignende løsninger vil vokse. Når det er sagt, kan vi også forvente behovet for at analysere og behandle data på mange forskellige måder. Tidsseriedata er typisk kun tilføjet - det er ret usandsynligt, at du opdaterer gamle data. Du sletter typisk ikke bestemte rækker, på den anden side vil du måske have en form for sammenlægning af data over tid. Vi ønsker ikke kun at gemme, hvordan vores data ændrer sig med tiden, men også analysere og lære af det.
Problemet med nye typer databasesystemer er, at de normalt bruger deres eget forespørgselssprog. Det tager tid for brugerne at lære et nyt sprog. Den største forskel mellem TimescaleDB og andre populære tidsseriedatabaser er understøttelsen af SQL. TimescaleDB understøtter hele rækken af SQL-funktionalitet inklusive tidsbaserede aggregater, joinforbindelser, underforespørgsler, vinduesfunktioner og sekundære indekser. Desuden, hvis din applikation allerede bruger PostgreSQL, er der ingen ændringer nødvendige i klientkoden.
Grundlæggende om arkitektur
TimescaleDB er implementeret som en udvidelse på PostgreSQL, hvilket betyder, at en tidsskaladatabase kører i en samlet PostgreSQL-instans. Udvidelsesmodellen gør det muligt for databasen at drage fordel af mange af PostgreSQL's egenskaber såsom pålidelighed, sikkerhed og tilslutning til en lang række tredjepartsværktøjer. Samtidig udnytter TimescaleDB den høje grad af tilpasning, der er tilgængelig for udvidelser, ved at tilføje hooks dybt ind i PostgreSQL's forespørgselsplanlægger, datamodel og eksekveringsmotor.
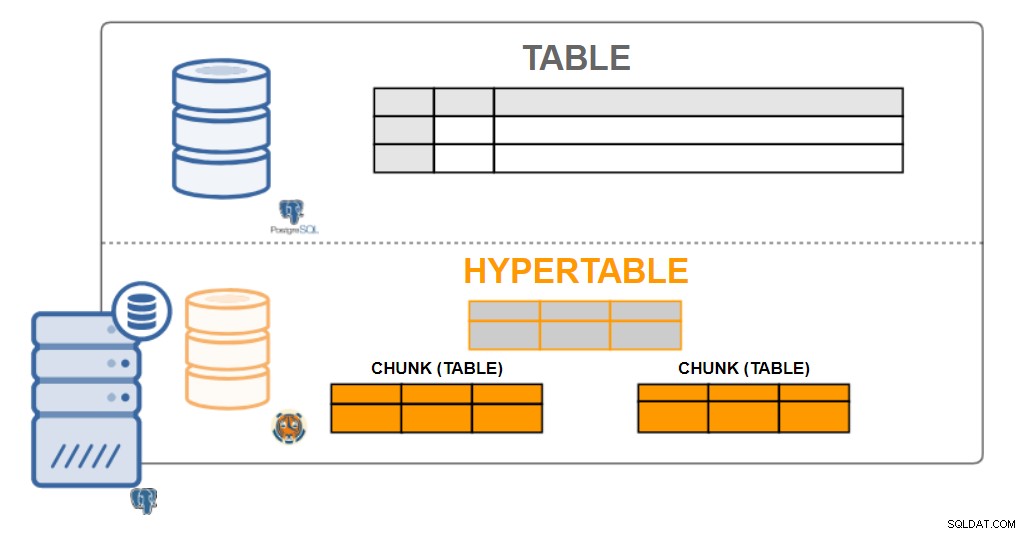 TimescaleDB-arkitektur
TimescaleDB-arkitektur Hypertabeller
Fra et brugerperspektiv ser TimescaleDB-data ud som enkeltstående tabeller, kaldet hypertabeller. Hypertabeller er et koncept eller en implicit visning af mange individuelle tabeller, der indeholder dataene kaldet chunks. Hypertabellens data kan være enten en eller to dimensioner. Den kan aggregeres med et tidsinterval og med en (valgfri) "partitionsnøgle"-værdi.
Praktisk talt alle brugerinteraktioner med TimescaleDB er med hypertabeller. Oprettelse af tabeller, indekser, ændring af tabeller, udvælgelse af data, indsættelse af data ... bør alt sammen udføres på hypertabellen.
TimescaleDB udfører denne omfattende partitionering både på enkelt-node-implementeringer såvel som klyngede implementeringer (under udvikling). Mens partitionering traditionelt kun bruges til at skalere ud på tværs af flere maskiner, giver det os også mulighed for at skalere op til høje skrivehastigheder (og forbedrede paralleliserede forespørgsler) selv på enkelte maskiner.
Relationel dataunderstøttelse
Som en relationel database har den fuld understøttelse af SQL. TimescaleDB understøtter fleksible datamodeller, der kan optimeres til forskellige use cases. Dette gør Timescale noget anderledes end de fleste andre tidsseriedatabaser. DBMS er optimeret til hurtig indlæsning og komplekse forespørgsler, baseret på PostgreSQL, og efter behov har vi adgang til robust tidsseriebehandling.
Installation
TimescaleDB på samme måde som PostgreSQL understøtter mange forskellige måder at installere på, inklusive installation på Ubuntu, Debian, RHEL/Centos, Windows eller cloud-platforme.
En af de mest bekvemme måder at spille med TimescaleDB på er et docker-billede.
Nedenstående kommando vil trække et Docker-billede fra Docker Hub, hvis det ikke allerede er installeret, og derefter køre det.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbFørste brug
Da vores instans er oppe og køre, er det tid til at oprette vores første timescaledb-database. Som du kan se nedenfor, forbinder vi via standard PostgreSQL-konsollen, så hvis du har PostgreSQL-klientværktøjer (f.eks. psql) installeret lokalt, kan du bruge dem til at få adgang til TimescaleDB docker-instansen.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Dag til dag drift
Fra perspektivet af både brug og administration ser og føles TimescaleDB bare som PostgreSQL og kan administreres og forespørges som sådan.
De vigtigste punktpunkter for den daglige drift er:
- Eksisterer sammen med andre TimescaleDB'er og PostgreSQL-databaser på en PostgreSQL-server.
- Bruger SQL som grænsefladesprog.
- Bruger almindelige PostgreSQL-stik til tredjepartsværktøjer til sikkerhedskopiering, konsol osv.
TidsskalaDB-indstillinger
PostgreSQL's out-of-the-box-indstillinger er typisk for konservative til moderne servere og TimescaleDB. Du bør sikre dig, at dine postgresql.conf-indstillinger er indstillet, enten ved at bruge timescaledb-tune eller ved at gøre det manuelt.
$ timescaledb-tuneScriptet vil bede dig om at bekræfte ændringer. Disse ændringer skrives derefter til din postgresql.conf og træder i kraft ved genstart.
Lad os nu tage et kig på nogle grundlæggende handlinger fra TimescaleDB tutorial, som kan give dig en idé om, hvordan du arbejder med det nye databasesystem.
For at oprette en hypertabel starter du med en almindelig SQL-tabel og konverterer den derefter til en hypertabel via funktionen create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Konverter det til hypertable er enkelt som:
SELECT create_hypertable('conditions', 'time');Indsættelse af data i hypertabellen sker via normale SQL-kommandoer:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);At vælge data, er gammel god SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Som vi kan se nedenfor, kan vi lave en gruppe efter, rækkefølge efter og funktioner. Derudover inkluderer TimescaleDB funktioner til tidsserieanalyse, som ikke er til stede i vanilla PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;