Jeg skrev tidligere om ejendommen Actual Rows Read. Den fortæller dig, hvor mange rækker der faktisk læses af en indekssøgning, så du kan se, hvor selektivt søgeprædikatet er sammenlignet med selektiviteten af søgeprædikatet plus restprædikatet kombineret.
Men lad os se på, hvad der faktisk foregår inde i Seek-operatøren. For jeg er ikke overbevist om, at "Faktiske Rows Read" nødvendigvis er en præcis beskrivelse af, hvad der foregår.
Jeg vil gerne se på et eksempel på, at forespørgsler på adresser af bestemte adressetyper for en kunde, men princippet her ville let gælde i mange andre situationer, hvis formen på din forespørgsel passer, såsom at slå attributter op i en nøgle-værdi-par-tabel, for eksempel.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Jeg ved, at jeg ikke har vist dig noget om metadataene - det vender jeg tilbage til om et øjeblik. Lad os overveje denne forespørgsel, og hvilken slags indeks vi gerne vil have til den.
For det første kender vi KundeID nøjagtigt. Et ligestillingsmatch som dette gør det generelt til en fremragende kandidat til den første kolonne i et indeks. Hvis vi havde et indeks på denne kolonne, kunne vi dykke direkte ind i adresserne for den kunde - så jeg vil sige, at det er en sikker antagelse.
Den næste ting at overveje er det filter på AddressTypeID. Det er helt rimeligt at tilføje en anden kolonne til nøglerne i vores indeks, så lad os gøre det. Vores indeks er nu tændt (kunde-id, adressetype-id). Og lad os også INKLUDERE FullAddress, så vi ikke behøver at foretage nogen opslag for at fuldende billedet.
Og jeg tror, vi er færdige. Vi burde sikkert kunne antage, at det ideelle indeks for denne forespørgsel er:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Vi kunne potentielt erklære det som et unikt indeks – vi vil se på virkningen af det senere.
Så lad os oprette en tabel (jeg bruger tempdb, fordi jeg ikke har brug for den til at fortsætte ud over dette blogindlæg) og teste dette af.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Jeg er ikke interesseret i fremmednøglebegrænsninger eller hvilke andre kolonner der kan være. Jeg er kun interesseret i mit Ideal Index. Så lav det også, hvis du ikke allerede har gjort det.
Min plan virker ret perfekt.
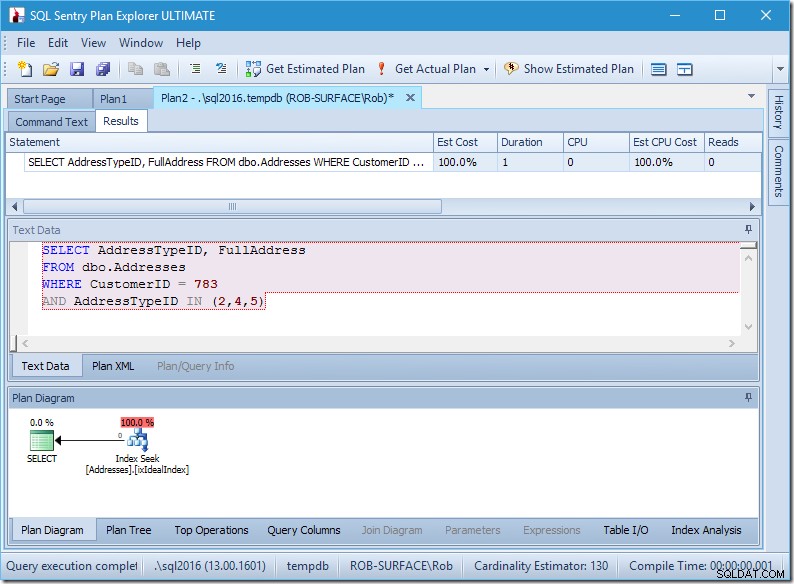
Jeg har en indekssøgning, og det er det.
Indrømmet, der er ingen data, så der er ingen læsninger, ingen CPU, og den kører også ret hurtigt. Hvis bare alle forespørgsler kunne tunes så godt som dette.
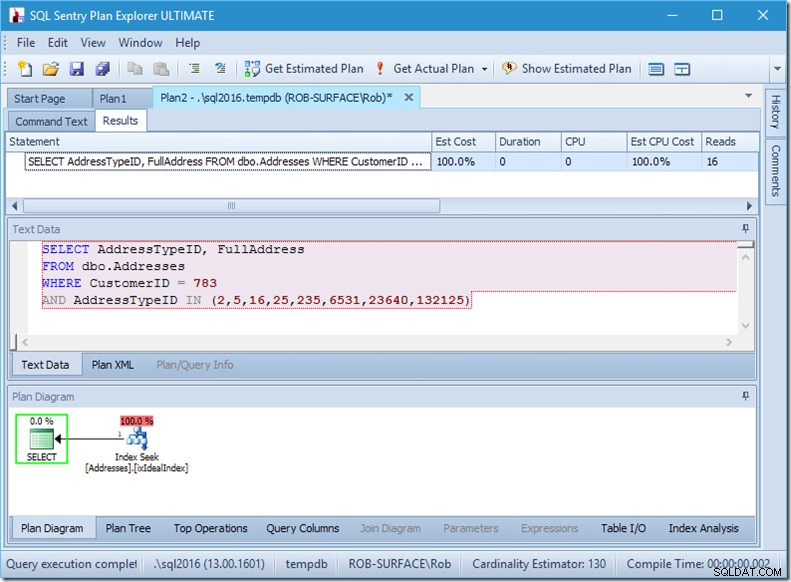
Lad os se, hvad der foregår lidt nærmere, ved at se på egenskaberne for Seek.
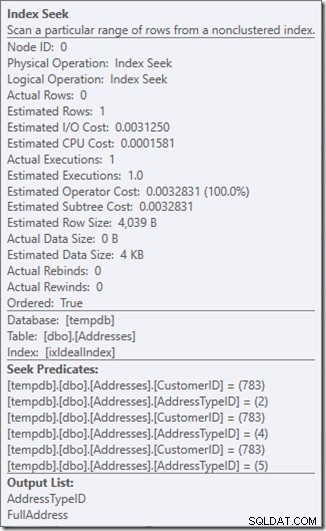
Vi kan se Seek-prædikaterne. Der er seks. Tre om kunde-ID og tre om AddressTypeID. Det, vi faktisk har her, er tre sæt søgeprædikater, der indikerer tre søgeoperationer inden for den enkelte søgeoperator. Den første søgning leder efter kunde 783 og adressetype 2. Den anden leder efter 783 og 4, og den sidste 783 og 5. Vores søgeoperatør dukkede op én gang, men der var tre søgninger i gang inde i den.
Vi har ikke engang data, men vi kan se, hvordan vores indeks vil blive brugt.
Lad os lægge nogle dummy-data ind, så vi kan se på noget af virkningen af dette. Jeg vil indsætte adresser for type 1 til 6. Hver kunde (over 2000, baseret på størrelsen på master..spt_values ) vil have en adresse af type 1. Måske er det den primære adresse. Jeg lader 80 % have en type 2-adresse, 60 % en type 3 og så videre, op til 20 % for type 5. Række 783 får adresser af type 1, 2, 3 og 4, men ikke 5. Jeg ville hellere have gået med tilfældige værdier, men jeg vil gerne sikre mig, at vi er på samme side for eksemplerne.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Lad os nu se på vores forespørgsel med data. To rækker kommer ud. Det er som før, men vi ser nu de to rækker komme ud af Seek-operatoren, og vi ser seks læsninger (øverst til højre).
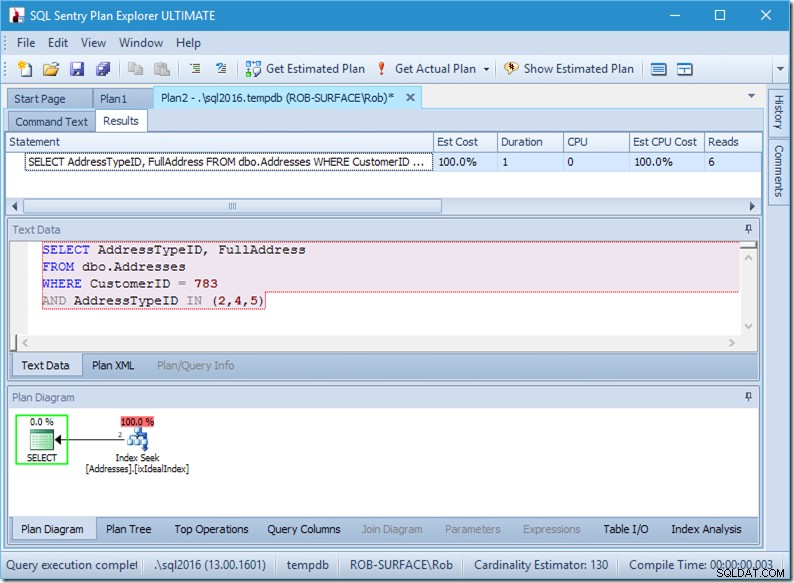
Seks læsninger giver mening for mig. Vi har et lille bord, og indekset passer på kun to niveauer. Vi laver tre søgninger (inden for vores ene operatør), så motoren læser rodsiden, finder ud af, hvilken side den skal gå ned til og læser den, og gør det tre gange.
Hvis vi bare skulle lede efter to AddressTypeID'er, ville vi kun se 4 læsninger (og i dette tilfælde udsendes en enkelt række). Fremragende.
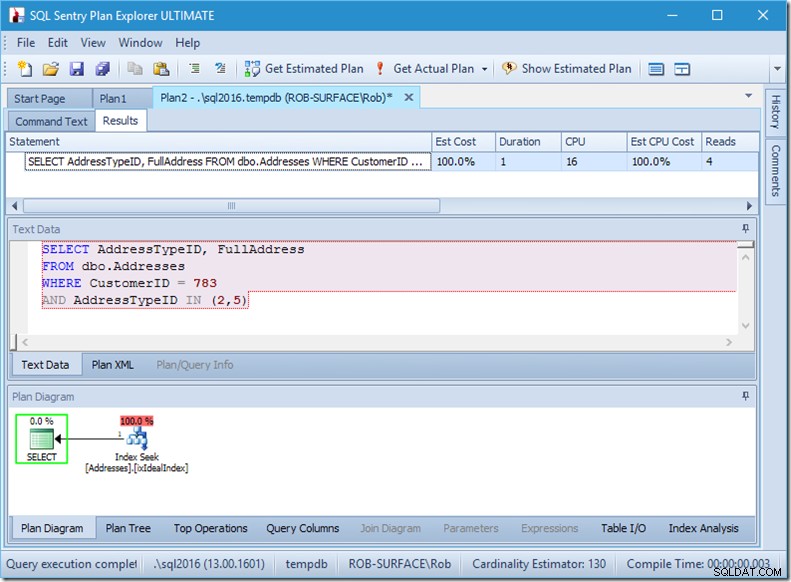
Og hvis vi ledte efter 8 adressetyper, så ville vi se 16.
Alligevel viser hver af disse, at de faktiske rækker, der er læst, matcher de faktiske rækker nøjagtigt. Ingen ineffektivitet overhovedet!
Lad os gå tilbage til vores oprindelige forespørgsel og lede efter adressetyperne 2, 4 og 5 (som returnerer 2 rækker) og tænke over, hvad der foregår i søgningen.
Jeg vil antage, at forespørgselsmotoren allerede har gjort arbejdet med at finde ud af, at indekssøgningen er den rigtige handling, og at den har sidenummeret på indeksroden ved hånden.
På dette tidspunkt indlæser den siden i hukommelsen, hvis den ikke allerede er der. Det er den første læsning, der bliver talt med i udførelsen af eftersøgningen. Derefter finder den sidenummeret for den række, den leder efter, og læser den side ind. Det er den anden læsning.
Men vi overskygger ofte, at 'lokaliserer sidenummeret'-bit.
Ved at bruge DBCC IND(2, N'dbo.Address', 2); (den første 2 er database-id'et, fordi jeg bruger tempdb; den anden 2 er indeks-id'et for ixIdealIndex ), kan jeg opdage, at 712 i fil 1 er siden med det højeste IndexLevel. På skærmbilledet nedenfor kan jeg se, at side 668 er IndexLevel 0, som er rodsiden.

Så nu kan jeg bruge DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); for at se indholdet af side 712. På min maskine får jeg 84 rækker, der kommer tilbage, og jeg kan se, at kunde-id 783 vil være på side 1004 i fil 5.
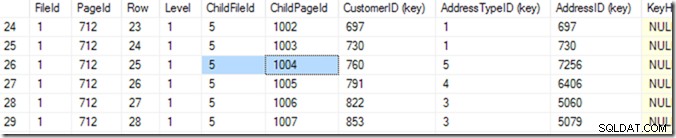
Men jeg ved det ved at scrolle gennem min liste, indtil jeg ser den, jeg vil have. Jeg startede med at scrolle lidt ned, og kom så op igen, indtil jeg fandt den række jeg ville have. En computer kalder dette en binær søgning, og den er lidt mere præcis end mig. Den leder efter rækken, hvor kombinationen (Kunde-ID, AddressTypeID) er mindre end den, jeg leder efter, hvor den næste side er større eller den samme som den. Jeg siger "det samme", fordi der kunne være to, der matcher, fordelt på to sider. Den ved, at der er 84 rækker (0 til 83) af data på den side (den læser det i sidehovedet), så den starter med at tjekke række 41. Derfra ved den, hvilken halvdel den skal søge i, og (i dette eksempel), vil den læse række 20. Et par læsninger mere (gør 6 eller 7 i alt)* og den ved, at række 25 (se venligst kolonnen kaldet 'Række' for denne værdi, ikke rækkenummeret fra SSMS ) er for lille, men række 26 er for stor – så 25 er svaret!
*I en binær søgning kan søgningen være marginalt hurtigere, hvis den er heldig, når den deler blokken i to, hvis der ikke er nogen midterplads, og afhængigt af om den midterste plads kan elimineres eller ej.
Nu kan den gå ind på side 1004 i fil 5. Lad os bruge DBCC PAGE på den.
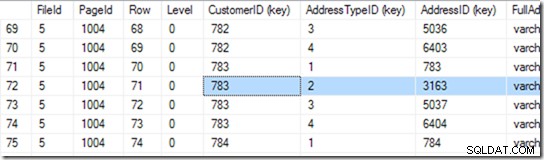
Denne giver mig 94 rækker. Den foretager endnu en binær søgning for at finde begyndelsen af det område, den leder efter. Den skal kigge gennem 6 eller 7 rækker for at finde det.
"Begyndelsen af rækken?" Jeg kan høre dig spørge. Men vi leder efter adresse type 2 på kunde 783.
Okay, men vi erklærede ikke dette indeks som unikt. Så der kunne være to. Hvis det er unikt, kan søgningen udføre en singleton-søgning og kan snuble over det under den binære søgning, men i dette tilfælde skal den fuldføre den binære søgning for at finde den første række i området. I dette tilfælde er det række 71.
Men vi stopper ikke her. Nu skal vi se, om der virkelig er en anden! Så den læser også række 72 og finder ud af, at kunde-ID+adressetype-parret faktisk er for stort, og dets søgning er udført.
Og dette sker tre gange. Tredje gang finder den ikke en række for kunde 783 og adressetype 5, men den ved det ikke på forhånd og skal stadig fuldføre søgningen.
Så rækkerne, der rent faktisk læses på tværs af disse tre søgninger (for at finde to rækker til output) er meget mere end det tal, der returneres. Der er omkring 7 på indeksniveau 1, og omkring 7 mere på bladniveau bare for at finde begyndelsen af rækken. Så læser den rækken, vi holder af, og så rækken efter det. Det lyder mere som 16 for mig, og det gør det tre gange, hvilket giver omkring 48 rækker.
Men Faktisk Rows Read handler ikke om antallet af rækker, der faktisk læses, men antallet af rækker, der returneres af Seek-prædikatet, som bliver testet mod Residual-prædikatet. Og i det er det kun de 2 rækker, der bliver fundet af de 3 søgninger.
Du tænker måske på dette tidspunkt, at der er en vis grad af ineffektivitet her. Den anden søgning ville også have læst side 712, kontrolleret de samme 6 eller 7 rækker der og derefter læst side 1004 og søgt igennem den... ligesom den tredje søgning.
Så måske ville det have været bedre at få dette på en enkelt søgning, idet du kun læste side 712 og side 1004 én gang hver. Når alt kommer til alt, hvis jeg gjorde dette med et papirbaseret system, ville jeg have søgt at finde kunde 783 og derefter scannet gennem alle deres adressetyper. For jeg ved, at en kunde ikke plejer at have mange adresser. Det er en fordel, jeg har i forhold til databasemotoren. Databasemotoren ved gennem sin statistik, at en søgning vil være bedst, men den ved ikke, at søgningen kun skal gå et niveau ned, når den kan fortælle, at den har, hvad der ligner det ideelle indeks.
Hvis jeg ændrer min forespørgsel for at få fat i en række adressetyper, fra 2 til 5, får jeg næsten den adfærd, jeg ønsker:
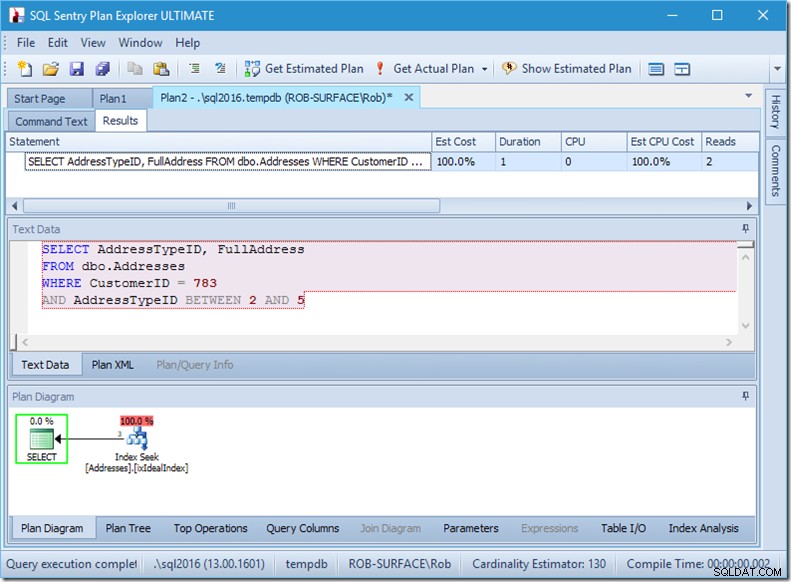
Se – læsningerne er nede på 2, og jeg ved, hvilke sider de er...
…men mine resultater er forkerte. Fordi jeg kun vil have adressetyperne 2, 4 og 5, ikke 3. Jeg skal fortælle den ikke at have 3, men jeg skal passe på, hvordan jeg gør dette. Se på de næste to eksempler.
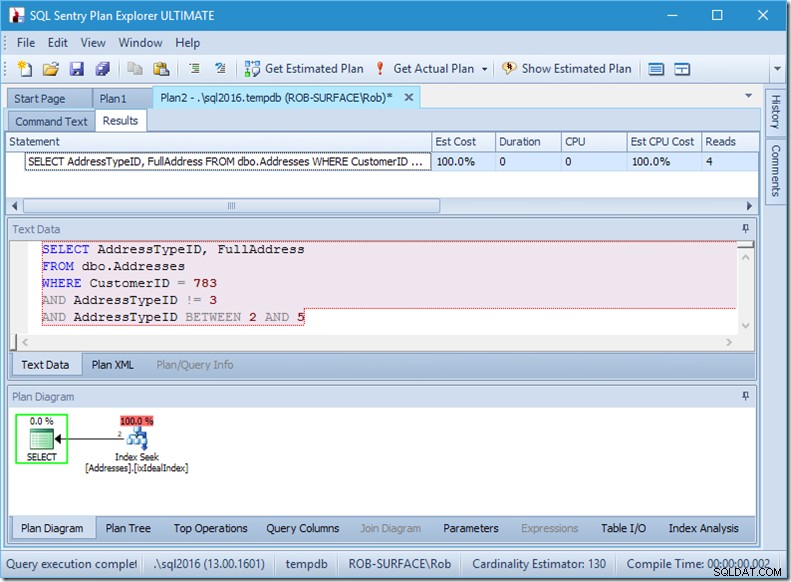
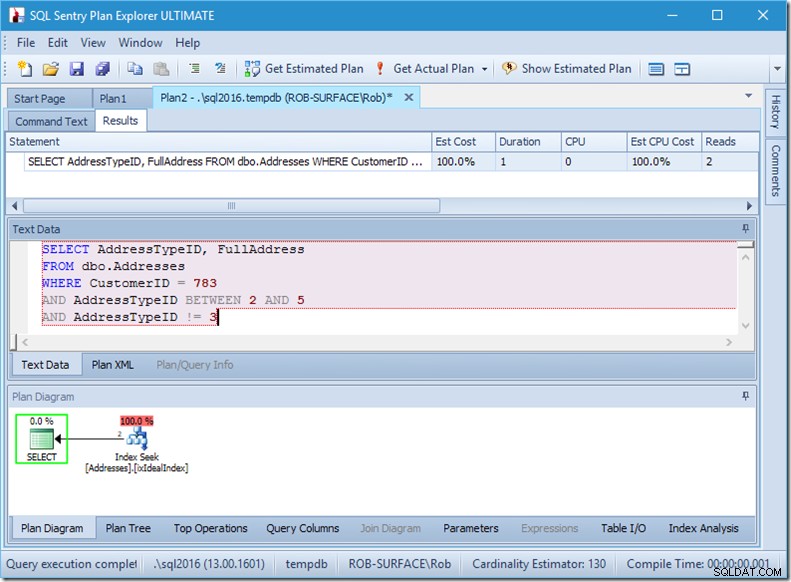
Jeg kan forsikre dig om, at prædikatrækkefølgen ikke betyder noget, men her gør det klart det. Hvis vi sætter "ikke 3" først, udfører den to søgninger (4 læsninger), men hvis vi sætter "ikke 3" nummer to, udfører den en enkelt søgning (2 læsninger).
Problemet er, at AddressTypeID !=3 bliver konverteret til (AddressTypeID> 3 OR AddressTypeID <3), som så ses som to meget nyttige søgeprædikater.
Og så min præference er at bruge et ikke-sargerbart prædikat til at fortælle det, at jeg kun vil have adressetyperne 2, 4 og 5. Og det kan jeg gøre ved at ændre AddressTypeID på en eller anden måde, såsom at tilføje nul til det.
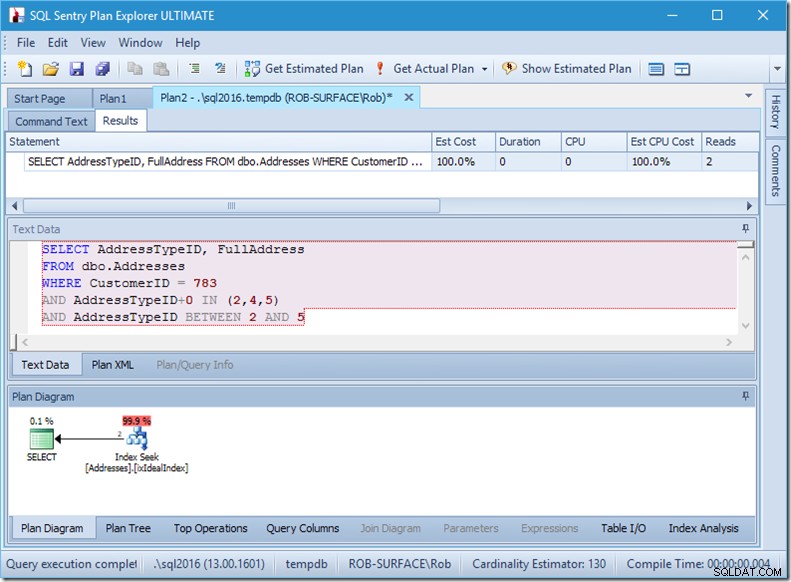
Nu har jeg en flot og stram rækkeviddescanning inden for en enkelt søgning, og jeg sørger stadig for, at min forespørgsel kun returnerer de rækker, jeg ønsker.
Åh, men den faktiske Rows Read-ejendom? Det er nu højere end egenskaben Faktisk rækker, fordi søgeprædikatet finder adressetype 3, som det resterende prædikat afviser.
Jeg har byttet tre perfekte søgninger for en enkelt ufuldkommen søgning, som jeg retter op med et resterende prædikat.
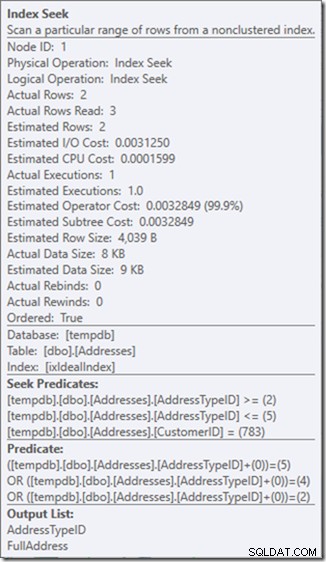
Og for mig er det nogle gange en pris, der er værd at betale, da jeg får en forespørgselsplan, som jeg er meget gladere for. Det er ikke væsentligt billigere, selvom det kun har en tredjedel af læsterne (fordi der kun ville være to fysiske læs), men når jeg tænker på det arbejde, det udfører, er jeg meget mere komfortabel med det, jeg beder om det. at gøre på denne måde.