Skærmbillede #1 viser nogle få punkter til at skelne mellem Merge Join transformation og Lookup transformation .
Angående opslag:
Hvis du ønsker at finde rækker, der matcher i kilde 2 baseret på input fra kilde 1, og hvis du ved, at der kun vil være ét match for hver inputrække, så vil jeg foreslå at bruge opslagsoperation. Et eksempel kunne være dig OrderDetails tabel, og du vil finde det matchende Order Id og Customer Number , så er Lookup en bedre mulighed.
Angående Merge Join:
Hvis du vil udføre joins som at hente alle adresser (hjem, arbejde, andet) fra Address tabel for en given kunde i Customer tabel, så skal du gå med Merge Join, fordi kunden kan have 1 eller flere adresser tilknyttet.
Et eksempel til sammenligning:
Her er et scenarie for at demonstrere ydeevneforskellene mellem Merge Join og Lookup . De data, der bruges her, er en en-til-en-forbindelse, hvilket er det eneste scenarie, der er fælles for dem at sammenligne.
-
Jeg har tre tabeller med navnet
dbo.ItemPriceInfo,dbo.ItemDiscountInfoogdbo.ItemAmount. Opret scripts til disse tabeller findes under SQL scripts sektionen. -
Tabeller
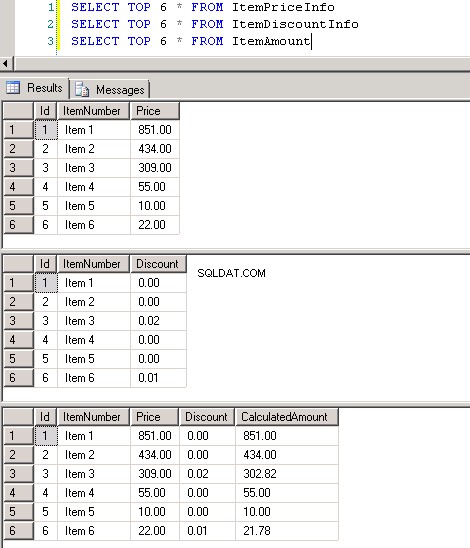
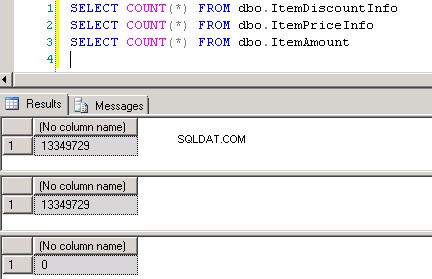
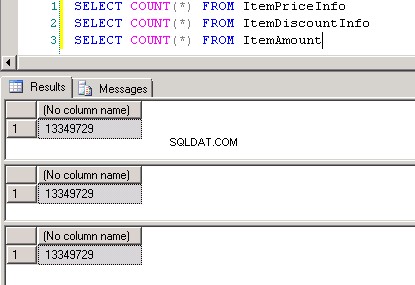
dbo.ItemPriceInfoogdbo.ItemDiscountInfobegge har 13.349.729 rækker. Begge tabeller har ItemNumber som fælles kolonne. ItemPriceInfo har prisoplysninger og ItemDiscountInfo har rabatoplysninger. Skærmbillede #2 viser rækkeantallet i hver af disse tabeller. Skærmbillede #3 viser de øverste 6 rækker for at give en idé om dataene i tabellerne. -
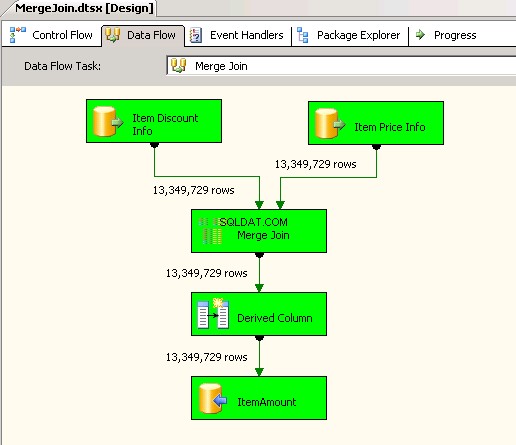
Jeg oprettede to SSIS-pakker for at sammenligne ydeevnen af Merge Join- og Lookup-transformationer. Begge pakker skal tage informationen fra tabellerne
dbo.ItemPriceInfoogdbo.ItemDiscountInfo, udregn det samlede beløb og gem det i tabellendbo.ItemAmount. -
Første pakke brugt
Merge Jointransformation og indeni at den brugte INNER JOIN til at kombinere dataene. Skærmbilleder #4 og #5 vis prøvepakkens udførelse og udførelsesvarigheden. Det tog05minutter14sekunder719millisekunder for at udføre den Merge Join-transformationsbaserede pakke. -
Anden pakke brugte
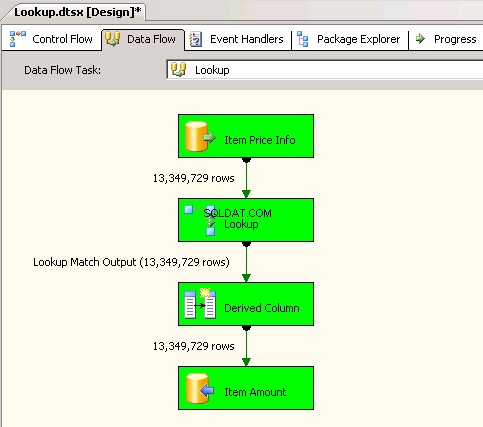
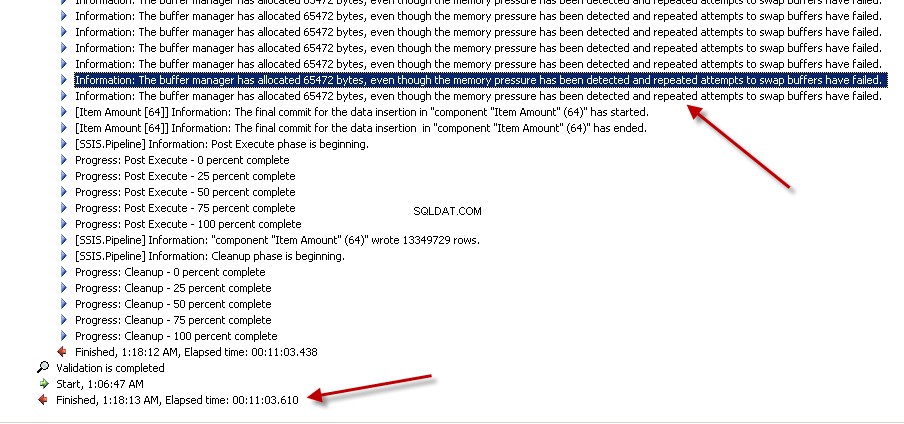
Lookuptransformation med fuld cache (som er standardindstillingen). creenshots #6 og #7 vis prøvepakkens udførelse og udførelsesvarigheden. Det tog11minutter03sekunder610millisekunder for at udføre den opslagstransformationsbaserede pakke. Du kan støde på advarselsmeddelelsen Information:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Her er et link der taler om, hvordan man beregner opslagscachestørrelse. Under denne pakkekørsel, selvom dataflow-opgaven blev fuldført hurtigere, tog Pipeline-oprydningen meget tid. -
Dette ikke betyder, at opslagstransformation er dårlig. Det er bare, at det skal bruges fornuftigt. Jeg bruger det ret ofte i mine projekter, men igen beskæftiger jeg mig ikke med 10+ millioner rækker til opslag hver dag. Normalt håndterer mine job mellem 2 og 3 millioner rækker, og for det er præstationen rigtig god. Op til 10 millioner rækker, begge klarede sig lige godt. Det meste af tiden, hvad jeg har bemærket, er, at flaskehalsen viser sig at være destinationskomponenten snarere end transformationerne. Du kan overvinde det ved at have flere destinationer. Her er et eksempel, der viser implementeringen af flere destinationer.
-
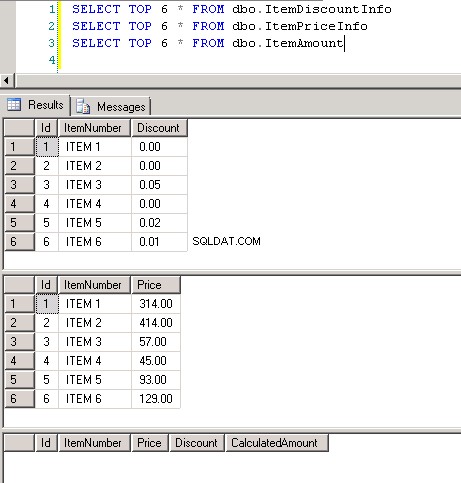
Skærmbillede #8 viser rekordtallet i alle tre tabeller. Skærmbillede #9 viser top 6 poster i hver af tabellerne.
Håber det hjælper.
SQL-scripts:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Skærmbillede #1:

Skærmbillede #2:
Skærmbillede #3:
Skærmbillede #4:
Skærmbillede #5:

Skærmbillede #6:
Skærmbillede #7:
Skærmbillede #8:
Skærmbillede #9: