Dette indlæg er en del af en serie af artikler om rækkemål. Du kan finde den første del her:
- Del 1:Opstilling og identifikation af rækkemål
Det er relativt velkendt at bruge TOP eller en FAST n forespørgselstip kan angive et rækkemål i en eksekveringsplan (se Indstilling og identifikation af rækkemål i eksekveringsplaner, hvis du har brug for en genopfriskning af rækkemål og deres årsager). Det er ret mindre almindeligt anerkendt, at semi joins (og anti joins) også kan introducere et rækkemål, selvom dette er noget mindre sandsynligt end tilfældet er for TOP , HURTIG , og INDSTIL RÆKKETAL .
Denne artikel hjælper dig med at forstå, hvornår og hvorfor en semi-join påkalder optimizerens rækkemålslogik.
Semi-tilmelding
En semi-join returnerer en række fra én join-input (A), hvis der er mindst én matchende række på den anden join-input (B).
De væsentlige forskelle mellem en semi join og en almindelig join er:
- Semi join returnerer enten hver række fra input A, eller også gør den ikke. Der kan ikke forekomme række duplikering.
- Almindelig joinforbindelse dublerer rækker, hvis der er flere matches på joinprædikatet.
- Semi join er defineret til kun at returnere kolonner fra input A.
- Almindelig joinforbindelse kan returnere kolonner fra enten (eller begge) join-input.
T-SQL mangler i øjeblikket understøttelse af direkte syntaks som FRA EN SEMI JOIN B PÅ A.x =B.y , så vi skal bruge indirekte former som EXISTS , NOGLE/NOT (inklusive den tilsvarende stenografi IN for lighedssammenligninger), og indstil INTERSECT .
Beskrivelsen af en semi-join ovenfor antyder naturligvis anvendelsen af et rækkemål, da vi er interesserede i at finde en hvilken som helst matchende række i B, ikke alle sådanne rækker . Ikke desto mindre fører en logisk semi-join udtryk i T-SQL muligvis ikke til en eksekveringsplan, der bruger et rækkemål af flere årsager, som vi vil pakke ud herefter.
Transformation og forenkling
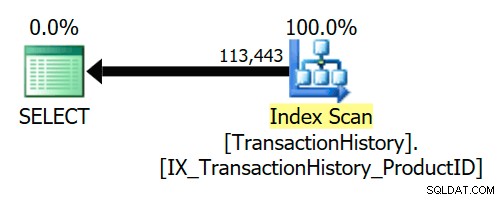
En logisk semi join kan forenkles væk eller erstattes med noget andet under forespørgselskompilering og optimering. AdventureWorks-eksemplet nedenfor viser, at en semi-join bliver fjernet helt på grund af et betroet udenlandsk nøgleforhold:
VÆLG TH.ProductID FROM Production.TransactionHistory AS THWHERE TH.ProductID IN( SELECT P.ProductID FROM Production.Product AS P);
Fremmednøglen sikrer, at Product rækker vil altid eksistere for hver historie række. Som følge heraf får eksekveringsplanen kun adgang til TransactionHistory tabel:
Et mere almindeligt eksempel ses, når semi-sammenføjningen kan transformeres til en indre sammenføjning. For eksempel:
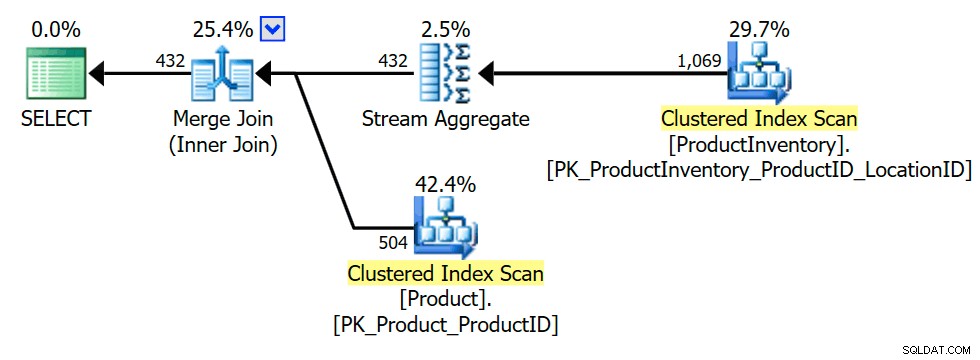
SELECT P.ProductID FROM Production.Product AS P WHERE EXISTS( SELECT * FROM Production.ProductInventory AS INV WHERE INV.ProductID =P.ProductID);
Udførelsesplanen viser, at optimeringsværktøjet introducerede et aggregat (gruppering på INV.ProductID ) for at sikre, at den indre forbindelse kun kan returnere Produkt rækker én gang eller slet ikke (alt efter behov for at bevare semantikkens semantik):
Transformationen til indre joinforbindelse undersøges tidligt, fordi optimeringsværktøjet kender flere tricks til indre equijoins, end det gør for semi-joins, hvilket potentielt kan føre til flere optimeringsmuligheder. Naturligvis er det endelige planvalg stadig en omkostningsbaseret beslutning blandt de undersøgte alternativer.
Tidlige optimeringer
Selvom T-SQL mangler direkte SEMI JOIN syntaks, ved optimeringsværktøjet alt om semi joins native og kan manipulere dem direkte. Den almindelige løsning af semi-join-syntakser transformeres til en "rigtig" intern semi-join tidligt i forespørgselskompileringsprocessen (godt før selv en triviel plan overvejes).
De to primære løsninger til syntaksgrupper er EXISTS/INTERSECT , og ANY/NOGLE/IN . INTERSECT tilfælde adskiller sig kun ved, at sidstnævnte kommer med en implicit DISTINCT (gruppering på alle projicerede søjler). Begge FINDER og INTERSECT parses som en EXISTS med korreleret underforespørgsel. ANY/SOME/IN repræsentationer tolkes alle som en NOGET operation. Vi kan tidligt udforske denne optimeringsaktivitet med nogle få udokumenterede sporingsflag, som sender oplysninger om optimeringsaktivitet til fanen SSMS-meddelelser.
For eksempel kan den semi-join, vi har brugt indtil videre, også skrives med IN :
SELECT P.ProductIDFROM Production.Product AS PWHERE P.ProductID IN /* or =ANY/SOME */( SELECT TH.ProductIDFROM Production.TransactionHistory AS TH)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON1);<86221); /pre>Optimizer-inputtræet er som følger:
Den skalære operator ScaOp_SomeComp er
NOGLEsammenligning nævnt ovenfor. 2'eren er koden for en lighedstest, daINsvarer til=SOME. Hvis du er interesseret, er der koder fra 1 til 6, der repræsenterer henholdsvis (<, =, <=,>, !=,>=) sammenligningsoperatorer.Vender tilbage til
EXISTSsyntaks, som jeg foretrækker at bruge oftest til at udtrykke en semi join indirekte:SELECT P.ProductIDFROM Production.Product AS PWHERE EXISTS( SELECT * FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);Optimeringsinputtræet er:
Det træ er en ret direkte oversættelse af forespørgselsteksten; Bemærk dog, at
SELECT *er allerede blevet erstattet af en projektion af den konstante heltalværdi 1 (se næstsidste tekstlinje).Den næste ting, optimizeren gør, er at fjerne underforespørgslen i det relationelle udvalg (=filter) ved hjælp af reglen RemoveSubqInSel . Optimizeren gør dette altid, da den ikke kan fungere direkte på underforespørgsler. Resultatet er en anvend (a.k.a korreleret eller lateral sammenføjning):
(Den samme regel for fjernelse af underforespørgsler producerer det samme output for
SOMEogså inputtræ).Det næste trin er at omskrive ansøgningen som en almindelig joinforbindelse ved hjælp af ApplyHandler regere familie. Dette er noget, optimizeren altid forsøger at gøre, fordi den har flere udforskningsregler for joins, end den gør for at anvende. Ikke alle ansøgninger kan omskrives som en joinforbindelse, men det aktuelle eksempel er ligetil og lykkes:
Bemærk, at typen af sammenføjningen er venstre semi. Dette er faktisk præcis det samme træ, som vi ville få med det samme, hvis T-SQL understøttede syntaks som:
VÆLG P.ProductID FRA Production.Product AS P LEFT SEMI JOIN Production.TransactionHistory AS TH ON TH.ProductID =P.ProductID;Det ville være rart at kunne udtrykke forespørgsler mere direkte på denne måde. I hvert fald opfordres den interesserede læser til at udforske ovenstående forenklingsaktiviteter med andre logisk ækvivalente måder at skrive denne semi-join i T-SQL på.
Den vigtige takeaway på dette trin er, at optimeringsværktøjet altid fjerner underforespørgsler , og erstatte dem med en ansøgning. Den forsøger derefter at omskrive ansøgningen som en almindelig joinforbindelse for at maksimere chancerne for at finde en god plan. Husk, at alt det foregående finder sted, før selv en triviel plan overvejes. Under omkostningsbaseret optimering kan optimeringsværktøjet også overveje at transformere joinforbindelsen tilbage til en ansøgning.
Hash og Merge Semi Join
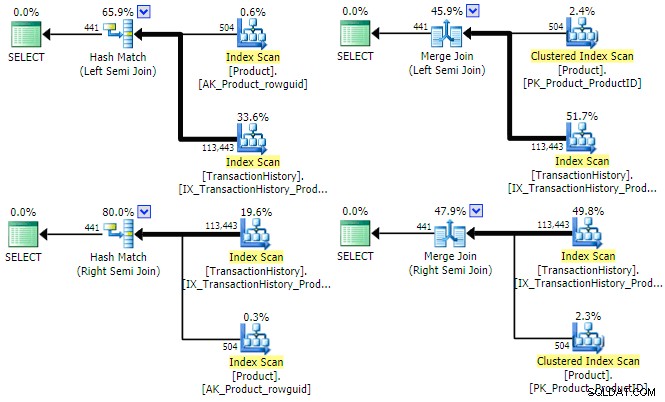
SQL Server har tre primære fysiske implementeringsmuligheder tilgængelige for en logisk semi join. Så længe et equijoin-prædikat er til stede, er hash og merge join tilgængelige; begge kan fungere i venstre- og højre-semi join-tilstande. Indlejrede loops join understøtter kun venstre (ikke højre) semi join, men kræver ikke et equijoin prædikat. Lad os se på hashen og flette fysiske muligheder for vores eksempelforespørgsel (skrevet som et sæt skærer denne gang):
SELECT P.ProductID FROM Production.Product AS PINTERSECTSELECT TH.ProductID FROM Production.TransactionHistory AS TH;Optimeringsværktøjet kan finde en plan for alle fire kombinationer af (venstre/højre) og (hash/fletning) semi join for denne forespørgsel:
Det er værd at nævne kort, hvorfor optimeringsværktøjet kan overveje både venstre og højre semi joins for hver jointype. For hash-semi-join er en væsentlig omkostningsbetragtning den estimerede størrelse af hash-tabellen, som altid er det venstre (øverste) input til at begynde med. For merge semi join bestemmer egenskaberne for hver input, om en en-til-mange eller mindre effektiv mange-til-mange fletning med arbejdstabel vil blive brugt.
Det fremgår måske af ovenstående eksekveringsplaner, at hverken hash eller merge semi join ville drage fordel af at sætte et rækkemål . Begge jointyper tester altid joinprædikatet ved selve joinforbindelsen og sigter mod at forbruge alle rækker fra begge input for at returnere et komplet resultatsæt. Det betyder ikke, at ydeevneoptimeringer ikke eksisterer for hash og merge join generelt - for eksempel kan begge bruge bitmaps til at reducere antallet af rækker, der når sammenføjningen. Pointen er snarere, at et rækkemål på begge input ikke ville gøre en hash eller flette semi join mere effektiv.
Indlejrede løkker og påfør semi-join
Den resterende fysiske jointype er indlejrede løkker, som findes i to varianter:almindelige (ukorrelerede) indlejrede løkker og anvend indlejrede sløjfer (nogle gange også omtalt som en korreleret eller lateral deltage).
Regulære indlejrede loops-join ligner hash- og merge-join, idet join-prædikatet evalueres ved join-forbindelsen. Som før betyder det, at der ikke er nogen værdi i at sætte et rækkemål på begge input. Det venstre (øverste) input vil altid være fuldt forbrugt til sidst, og det indre input har ingen mulighed for at bestemme, hvilke række(r) der skal prioriteres, da vi ikke kan vide, om en række vil joine eller ej, før prædikatet er testet ved sammenkædningen .
I modsætning hertil har en anvend indlejret loops-join en eller flere ydre referencer (korrelerede parametre) ved joinforbindelsen, med join-prædikatet trykket ned den indvendige (nederste) side af samlingen. Dette skaber en mulighed for nyttig anvendelse af et rækkemål. Husk på, at en semi-join kun kræver, at vi kontrollerer, om der findes en række på join-input B, der matcher den aktuelle række på join-input A (tænker kun på indlejrede loops join-strategier nu).
Med andre ord, ved hver iteration af en ansøgning kan vi stoppe med at se på input B, så snart det første match er fundet, ved at bruge det nedpressede join-prædikat. Det er præcis den slags ting, et rækkemål er godt til:at generere en del af en plan, der er optimeret til hurtigt at returnere de første n matchende rækker (hvor
n =1her).Selvfølgelig kan et rækkemål være en god ting eller ej, alt efter omstændighederne. Der er ikke noget særligt ved semi join row-målet i den forbindelse. Overvej en situation, hvor den indvendige side af semi-sammenføjningen er mere kompleks end en enkelt enkel bordadgang, måske en flerbordssammenføjning. Angivelse af et rækkemål kan hjælpe optimeringsværktøjet med at vælge en effektiv navigationsstrategi kun for det pågældende undertræ , at finde den første matchende række til at opfylde semi-sammenføjningen via indlejrede loops-sammenføjninger og indekssøgninger. Uden rækkemålet kan optimeringsværktøjet naturligvis vælge hash eller flette sammenføjninger med sorteringer for at minimere de forventede omkostninger ved at returnere alle mulige rækker. Bemærk, at der er en antagelse her, nemlig at folk typisk skriver semi joins med en forventning om, at der faktisk eksisterer en række, der matcher søgebetingelsen. Dette forekommer mig at være en rimelig nok antagelse.
Uanset hvad er det vigtige punkt på dette stadium:Kun ansøg indlejrede loops join har et rækkemål anvendt af optimeringsværktøjet (husk dog, at et rækkemål for anvend indlejrede loops-sammenføjning kun tilføjes, hvis rækkemålet er mindre end estimatet uden det). Vi vil se på et par bearbejdede eksempler for forhåbentlig at gøre alt dette klart næste gang.
Eksempler på indlejrede løkker, semi-sammenføjning
Følgende script opretter to heap midlertidige tabeller. Den første har tal fra 1 til 20 inklusive; den anden har 10 kopier af hvert nummer i den første tabel:
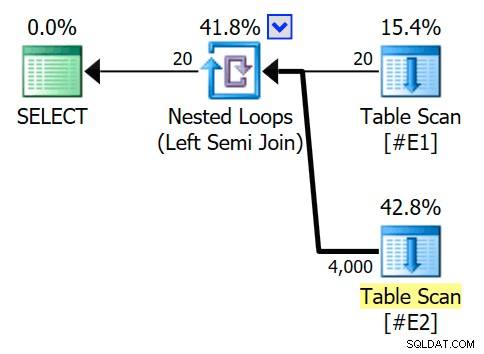
DROP TABEL HVIS FINDER #E1, #E2; CREATE TABLE #E1 (c1 heltal NULL); CREATE TABLE #E2 (c1 heltal NULL); INSERT #E1 (c1)SELECT SV.numberFROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' OG SV.number>=1 OG SV.number <=20; INSERT #E2 (c1)SELECT (SV.number % 20) + 1FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' OG SV.number>=1 AND SV.number <=200;Uden indekser og et relativt lille antal rækker vælger optimeringsværktøjet en indlejret loops (i stedet for hash eller fletning) implementering for den følgende semi join-forespørgsel). De udokumenterede sporingsflag giver os mulighed for at se optimeringsoutputtræet og rækkemåloplysninger:
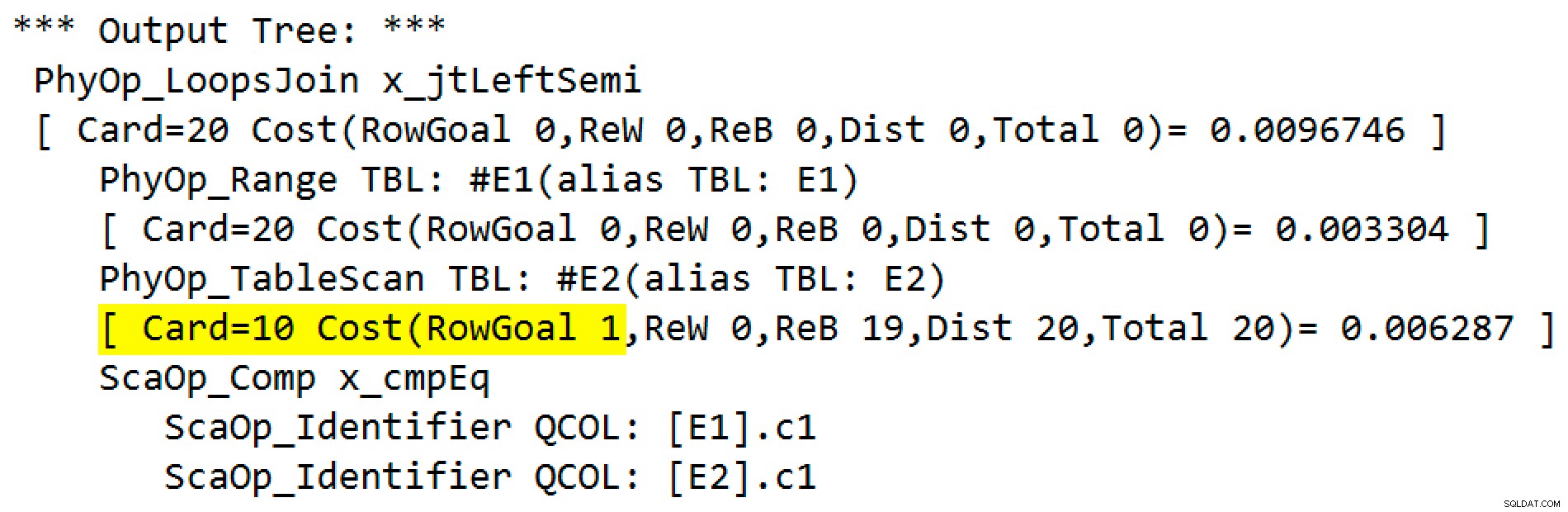
VÆLG E1.c1 FRA #E1 SOM E1HVOR E1.c1 IN (VÆLG E2.c1 FRA #E2 SOM E2)MULIGHED (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Den estimerede udførelsesplan har en semi-sammenføjning indlejrede loops-sammenføjninger med 200 rækker pr. fuld scanning af tabel
#E2. De 20 iterationer af løkken giver et samlet estimat på 4.000 rækker:
Egenskaberne for den indlejrede sløjfer-operator viser, at prædikatet anvendes ved joinforbindelsen hvilket betyder, at dette er en ukorreleret indlejret sløjfesammenføjning :
Sporingsflagoutputtet (på fanen SSMS-beskeder) viser en indlejret loops semi join og intet rækkemål (RowGoal 0):
Bemærk, at efterudførelsesplanen for denne legetøjsforespørgsel ikke vil vise 4.000 rækker læst fra tabel #E2 i alt. Indlejrede løkker semi-sammenføjning (korreleret eller ej) vil stoppe med at lede efter flere rækker på indersiden (per iteration), så snart den første match for den aktuelle ydre række stødes på. Nu er rækkefølgen af rækker fundet fra heap-scanningen af #E2 på hver iteration ikke-deterministisk (og kan være forskellig på hver iteration), så i princippet næsten alle rækkerne kunne testes på hver iteration i tilfælde af, at den matchende række stødes på så sent som muligt (eller i tilfælde af ingen matchende række slet ikke).
For eksempel, hvis vi antager en runtime-implementering, hvor rækker tilfældigvis bliver scannet i samme rækkefølge (f.eks. "indsættelsesrækkefølge") hver gang, vil det samlede antal rækker, der scannes i dette legetøjseksempel, være 20 rækker ved den første iteration, 1 række på den anden iteration, 2 rækker på den tredje iteration, og så videre for i alt 20 + 1 + 2 + (…) + 19 =210 rækker. Faktisk vil du sandsynligvis observere denne total, som siger mere om begrænsningerne ved simpel demonstrationskode, end det gør om noget andet. Man kan ikke stole på rækkefølgen af rækker, der returneres fra en uordnet adgangsmetode, ligesom man kan stole på det tilsyneladende ordnede output fra en forespørgsel uden en
ORDER BYpå øverste niveau. klausul.Anvend Semi Join
Vi opretter nu et ikke-klynget indeks på den større tabel (for at opmuntre optimeringsværktøjet til at vælge en anvende semi-join) og kører forespørgslen igen:
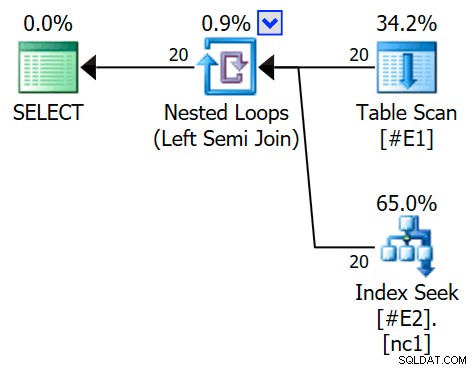
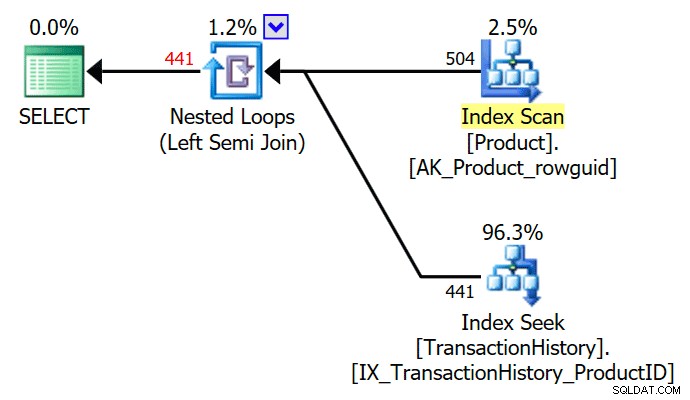
OPRET IKKE-KLYNGERET INDEKS nc1 PÅ #E2 (c1); VÆLG E1.c1 FRA #E1 SOM E1HVOR E1.c1 IN (VÆLG E2.c1 FRA #E2 SOM E2)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Udførelsesplanen indeholder nu en applicer semi join, med 1 række pr. indekssøgning (og 20 iterationer som før):
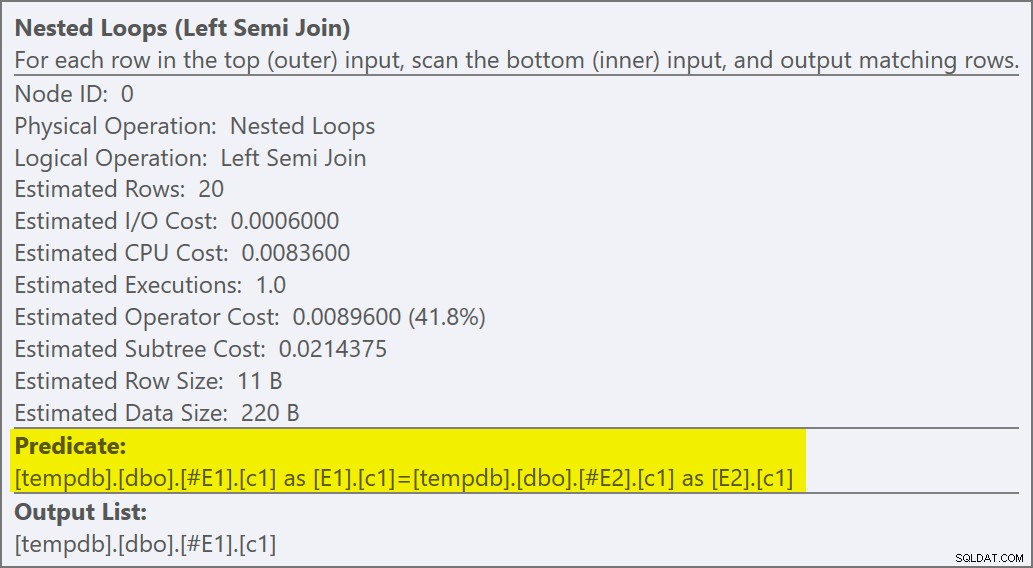
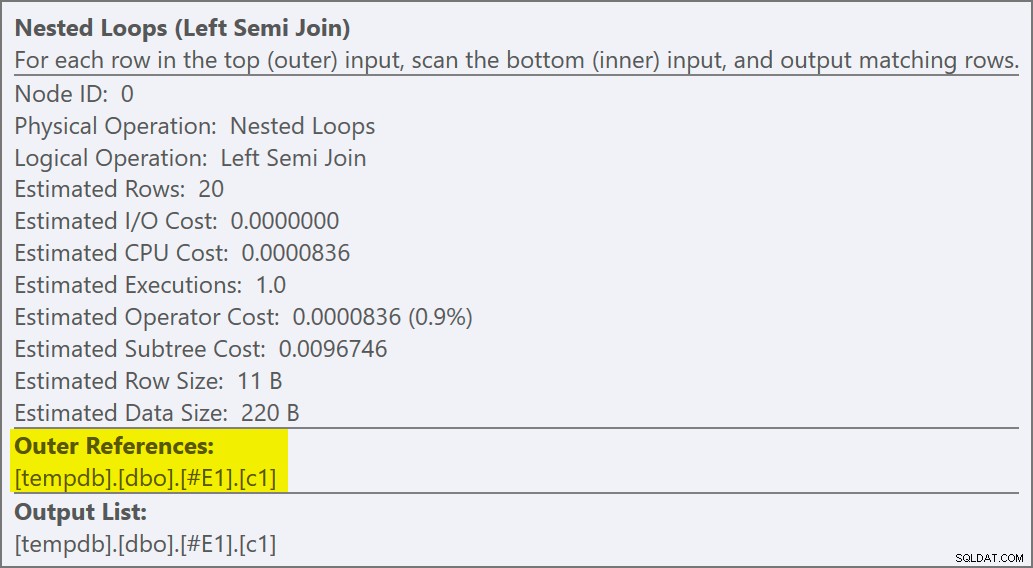
Vi kan se, at det er en anvend semi join fordi sammenføjningsegenskaberne viser en ydre reference i stedet for et join-prædikat:
Sammenføjningsprædikatet er blevet skubbet ned indersiden af ansøgningen, og matchet til det nye indeks:
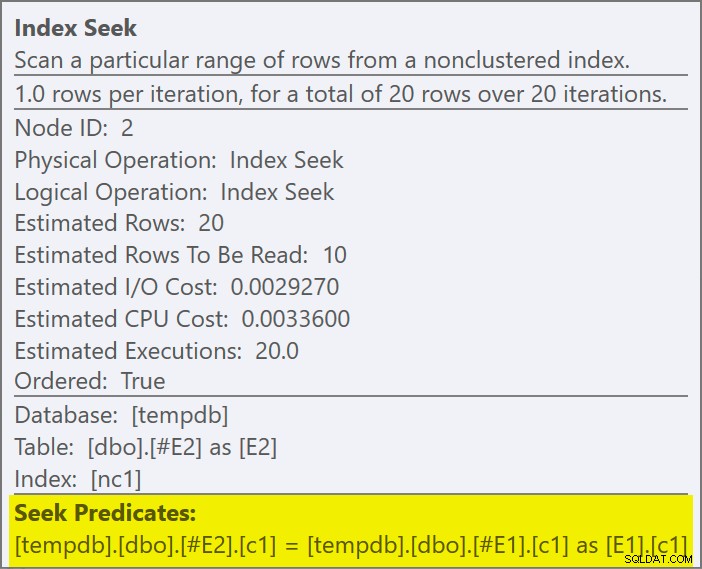
Hver søgning forventes at returnere 1 række, på trods af at hver værdi er duplikeret 10 gange i den tabel; dette er en effekt af rækkemålet . Rækkemålet vil være lettere at identificere på SQL Server-builds, der afslører EstimateRowsWithoutRowGoal plan attribut (SQL Server 2017 CU3 i skrivende stund). I en kommende version af Plan Explorer vil dette også blive afsløret på værktøjstip til relevante operatører:
Sporingsflagets output er:
Den fysiske operatør har ændret sig fra en loops join til en application, der kører i venstre semi join mode. Adgang til tabel
#E2har opnået et rækkemål på 1 (kardinaliteten uden rækkemålet vises som 10). Rækkemålet er ikke en stor sag i dette tilfælde, fordi omkostningerne ved at hente anslået ti rækker pr. søgning ikke er meget mere end for en række. Deaktivering af rækkemål for denne forespørgsel (ved hjælp af sporingsflag 4138 ellerDISABLE_OPTIMIZER_ROWGOALforespørgselstip) ville ikke ændre formen på planen.Ikke desto mindre, i mere realistiske forespørgsler, kan omkostningsreduktionen på grund af inderside-rækkemålet gøre forskellen mellem konkurrerende implementeringsmuligheder. Deaktivering af rækkemålet kan f.eks. få optimeringsværktøjet til at vælge en hash eller flette semi join i stedet, eller en af mange andre muligheder, der overvejes for forespørgslen. Om ikke andet afspejler rækkemålet her nøjagtigt det faktum, at en anvendelig semi-join stopper med at søge på indersiden, så snart den første match er fundet, og går videre til den næste ydre siderække.
Bemærk, at dubletter blev oprettet i tabel
#E2så målet for anvendelse af semi join-rækken (1) ville være lavere end det normale estimat (10, fra information om statistiktæthed). Hvis der ikke var nogen dubletter, rækkeestimatet for hver søgning i#E2ville også være 1 række, så et rækkemål på 1 ville ikke blive anvendt (husk den generelle regel om dette!)Rækkemål kontra top
I betragtning af at eksekveringsplaner slet ikke indikerer tilstedeværelsen af et rækkemål før SQL Server 2017 CU3, kunne man tro, at det ville have været klarere at implementere denne optimering ved hjælp af en eksplicit Top-operator frem for en skjult egenskab som et rækkemål. Ideen ville være blot at placere en Top (1) operator på indersiden af en applicer semi/anti join i stedet for at sætte et rækkemål ved selve joinningen.
At bruge en Top-operatør på denne måde ville ikke have været helt uden præcedens. For eksempel er der allerede en speciel version af Top kendt som en rækketæller-top set i datamodifikationsudførelsesplaner, når en
SET ROWCOUNTikke er nul er i kraft (bemærk, at denne specifikke brug er blevet forældet siden 2005, selvom den stadig er tilladt i SQL Server 2017). Implementeringen af rækkeoptællingens top er lidt klodset, idet topoperatøren altid vises som en top (0) i udførelsesplanen, uanset den faktiske rækkeantalgrænse, der er gældende.Der er ingen tvingende grund til, at målet for anvend semi join-rækker ikke kunne være blevet erstattet med en eksplicit Top (1) operator. Når det er sagt, er der nogle grunde til at foretrække ikke at gøre det:






- At tilføje en eksplicit Top (1) kræver mere optimeringskodningsindsats og -test end at tilføje et rækkemål (som allerede bruges til andre ting).
- Top er ikke en relationel operator; optimeringsværktøjet har ringe støtte til at ræsonnere om det. Dette kan påvirke plankvaliteten negativt ved at begrænse optimizerens mulighed for at transformere dele af en forespørgselsplan, f.eks. ved at flytte aggregater, fagforeninger, filtre og sammenføjninger rundt.
- Det ville introducere en tæt kobling mellem den anvendelige implementering af semi-sammenføjningen og toppen. Særlige tilfælde og tæt kobling er gode måder at introducere fejl på og gøre fremtidige ændringer vanskeligere og mere udsatte for fejl.
- Toppen (1) ville være logisk overflødig og kun til stede for dens rækkemåls bivirkning.
Det sidste punkt er værd at udvide med et eksempel:
VÆLG P.ProductID FRA Production.Product AS PWHERE EXISTS (VÆLG TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
TOP (1) i den eksisterende underforespørgsel er forenklet væk af optimizeren, hvilket giver en simpel semi join-udførelsesplan:
Optimeringsværktøjet kan også fjerne en overflødig DISTINCT eller GRUPPER EFTER i underforespørgslen. Følgende producerer alle den samme plan som ovenfor:
-- Redundant DISTINCTSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS (SELECT DISTINCT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID ); -- Redundant GROUP BYSELECT P.ProductID FRA Production.Product AS PWHERE EXISTS (VÆLG TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID GROUP BY TH.ProductID); -- Redundant DISTINCT TOP (1)VÆLG P.ProductID FROM Production.Product AS PWHERE EXISTS (SELECT DISTINCT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
Opsummering og endelige tanker
Kun ansøg indlejrede loops semi join kan have et rækkemål sat af optimizeren. Dette er den eneste jointype, der skubber joinprædikatet/-erne ned fra joinforbindelsen, hvilket gør det muligt at teste eksistensen af et match tidligt . Ikke-korrelerede indlejrede sløjfer semi-sammenføjning næsten aldrig* sætter et rækkemål, og en hash- eller flette-semi-join gør heller ikke. Anvend indlejrede sløjfer kan skelnes fra ukorrelerede indlejrede sløjfer sammenføjning ved tilstedeværelsen af ydre referencer (i stedet for et prædikat) på de indlejrede sløjfer join-operator for en ansøgning.
Chancerne for at se en ansøgt semi slutte sig til den endelige udførelsesplan afhænger i nogen grad af tidlig optimeringsaktivitet. I mangel af direkte T-SQL-syntaks er vi nødt til at udtrykke semi-sammenføjninger i indirekte termer. Disse parses i et logisk træ, der indeholder en underforespørgsel, som tidlig optimeringsaktivitet omdannes til en anvendelse, og derefter til en ukorreleret semi-join, hvor det er muligt.
Denne forenklingsaktivitet bestemmer, om en logisk semi-join præsenteres for den omkostningsbaserede optimizer som en anvendelig eller almindelig semi-join. Når præsenteret som en logisk anvend semi join, er CBO'en næsten sikker på at producere en endelig udførelsesplan med fysiske påføringsindlejrede sløjfer (og dermed sætte et rækkemål). Når præsenteret for en ukorreleret semi join, kan CBO'en må overveje transformation til en ansøgning (eller måske ikke). Det endelige valg af plan er en række omkostningsbaserede beslutninger som sædvanligt.
Ligesom alle rækkemål kan semi join-rækkemålet være en god eller en dårlig ting for præstationen. At vide, at en anvende semi join sætter et rækkemål, vil i det mindste hjælpe folk med at genkende og løse årsagen, hvis et problem skulle opstå. Løsningen vil ikke altid (eller endda normalt) være at deaktivere rækkemål for forespørgslen. Forbedringer i indeksering (og/eller forespørgslen) kan ofte foretages for at give en effektiv måde at finde den første matchende række på.
Jeg vil dække anti semi joins i en separat artikel, som fortsætter rækkemålsserien.
* Undtagelsen er en ukorreleret indlejret loops semi join uden join-prædikat (et usædvanligt syn). Dette sætter et rækkemål.