Tilbage i 2013 skrev jeg om en fejl i optimizeren, hvor 2. og 3. argumenter til DATEDIFF() kan byttes – hvilket kan føre til forkerte rækketællingsestimater og til gengæld dårligt valg af eksekveringsplan:
- Ydeevne-overraskelser og antagelser:DATEDIFF
I den forgangne weekend lærte jeg om en lignende situation og gjorde den umiddelbare antagelse, at det var det samme problem. Trods alt virkede symptomerne næsten identiske:
- Der var en dato/tidsfunktion i
WHEREklausul.- Denne gang var det
DATEADD()i stedet forDATEDIFF().
- Denne gang var det
- Der var et åbenlyst ukorrekt rækkeantal på 1 sammenlignet med et faktisk rækkeantal på over 3 millioner.
- Dette var faktisk et estimat på 0, men SQL Server runder altid sådanne estimater op til 1.
- Der blev foretaget et dårligt planvalg (i dette tilfælde blev der valgt en loop-sammenføjning) på grund af det lave estimat.
Det stødende mønster så således ud:
WHERE [datetime2(7) column] >= DATEADD(DAY, -365, SYSUTCDATETIME());
Brugeren prøvede flere variationer, men intet ændrede sig; det lykkedes dem til sidst at omgå problemet ved at ændre prædikatet til:
WHERE DATEDIFF(DAY, [column], SYSUTCDATETIME()) <= 365;
Dette fik et bedre skøn (det typiske gæt på 30 % ulighed); så ikke helt rigtigt. Og selvom det eliminerede loop join, er der to store problemer med dette prædikat:
- Det er ikke den samme forespørgsel, da den nu leder efter, at 365 dages grænser er passeret, i modsætning til at være større end et bestemt tidspunkt for 365 dage siden. Statistisk signifikant? Måske ikke. Men rent teknisk set er det ikke det samme.
- Anvendelse af funktionen mod kolonnen gør hele udtrykket ikke-sargerbart – hvilket fører til en fuld scanning. Når tabellen kun indeholder lidt over et års data, er dette ikke en big deal, men efterhånden som tabellen bliver større, eller prædikatet bliver smallere, vil dette blive et problem.
Igen sprang jeg til den konklusion, at DATEADD() operation var problemet, og anbefalede en tilgang, der ikke var afhængig af DATEADD() – opbygning af en datetime fra alle dele af den aktuelle tid, hvilket giver mig mulighed for at trække et år uden at bruge DATEADD() :
WHERE [column] >= DATETIMEFROMPARTS(
DATEPART(YEAR, SYSUTCDATETIME())-1,
DATEPART(MONTH, SYSUTCDATETIME()),
DATEPART(DAY, SYSUTCDATETIME()),
DATEPART(HOUR, SYSUTCDATETIME()),
DATEPART(MINUTE, SYSUTCDATETIME()),
DATEPART(SECOND, SYSUTCDATETIME()), 0); Ud over at være omfangsrig havde dette nogle egne problemer, nemlig at der skulle tilføjes en masse logik for at kunne tage højde for skudår. For det første, så den ikke fejler, hvis den tilfældigvis løber den 29. februar, og for det andet at inkludere præcis 365 dage i alle tilfælde (i stedet for 366 i løbet af året efter en skuddag). Nemme rettelser, selvfølgelig, men de gør logikken meget grimmere – især fordi forespørgslen skulle eksistere inde i en visning, hvor mellemliggende variabler og flere trin ikke er mulige.
I mellemtiden indsendte OP et Connect-element, forfærdet over 1-række-estimatet:
- Forbind #2567628:Begrænsning med DateAdd() giver ikke gode estimater
Så kom Paul White (@SQL_Kiwi) og kastede som mange gange før noget ekstra lys over problemet. Han delte et relateret Connect-emne indgivet af Erland Sommarskog tilbage i 2011:
- Forbind #685903:Forkert estimat, når sysdatetime vises i et dateadd()-udtryk
Grundlæggende er problemet, at et dårligt estimat ikke kun kan foretages, når SYSDATETIME() (eller SYSUTCDATETIME() ) vises, som Erland oprindeligt rapporterede, men når nogen datetime2 udtryk er involveret i prædikatet (og måske kun når DATEADD() bruges også). Og det kan gå begge veje – hvis vi bytter >= for <= , bliver estimatet hele tabellen, så det ser ud til, at optimeringsværktøjet kigger på SYSDATETIME() værdi som en konstant og ignorerer fuldstændigt alle operationer som DATEADD() der udføres imod det.
Paul delte, at løsningen simpelthen er at bruge en datetime tilsvarende ved beregning af datoen, før den konverteres til den korrekte datatype. I dette tilfælde kan vi udskifte SYSUTCDATETIME() og ændre det til GETUTCDATE() :
WHERE [column] >= CONVERT(datetime2(7), DATEADD(DAY, -365, GETUTCDATE()));
Ja, dette resulterer i et lille tab af præcision, men det kan også en støvpartikel, der bremser din finger på vej til at trykke på

Aflæsningerne ligner hinanden, fordi tabellen næsten udelukkende indeholder data fra det seneste år, så selv en søgning bliver en rækkeviddescanning af det meste af tabellen. Rækketællingerne er ikke identiske, fordi (a) den anden forespørgsel afbrydes ved midnat, og (b) den tredje forespørgsel inkluderer en ekstra dag med data på grund af skuddagen tidligere i år. Under alle omstændigheder viser dette stadig, hvordan vi kan komme tættere på korrekte estimater ved at eliminere DATEADD() , men den korrekte løsning er at fjerne den direkte kombination af DATEADD() og datetime2 .
For yderligere at illustrere, hvordan estimaterne får det forkerte, kan du se, at hvis vi videregiver forskellige argumenter og retninger til den oprindelige forespørgsel og Pauls omskrivning, er antallet af estimerede rækker for førstnævnte altid baseret på det aktuelle tidspunkt – de gør ikke ændres ikke med antallet af dage, der er gået (hvorimod Pauls er relativt nøjagtig hver gang):
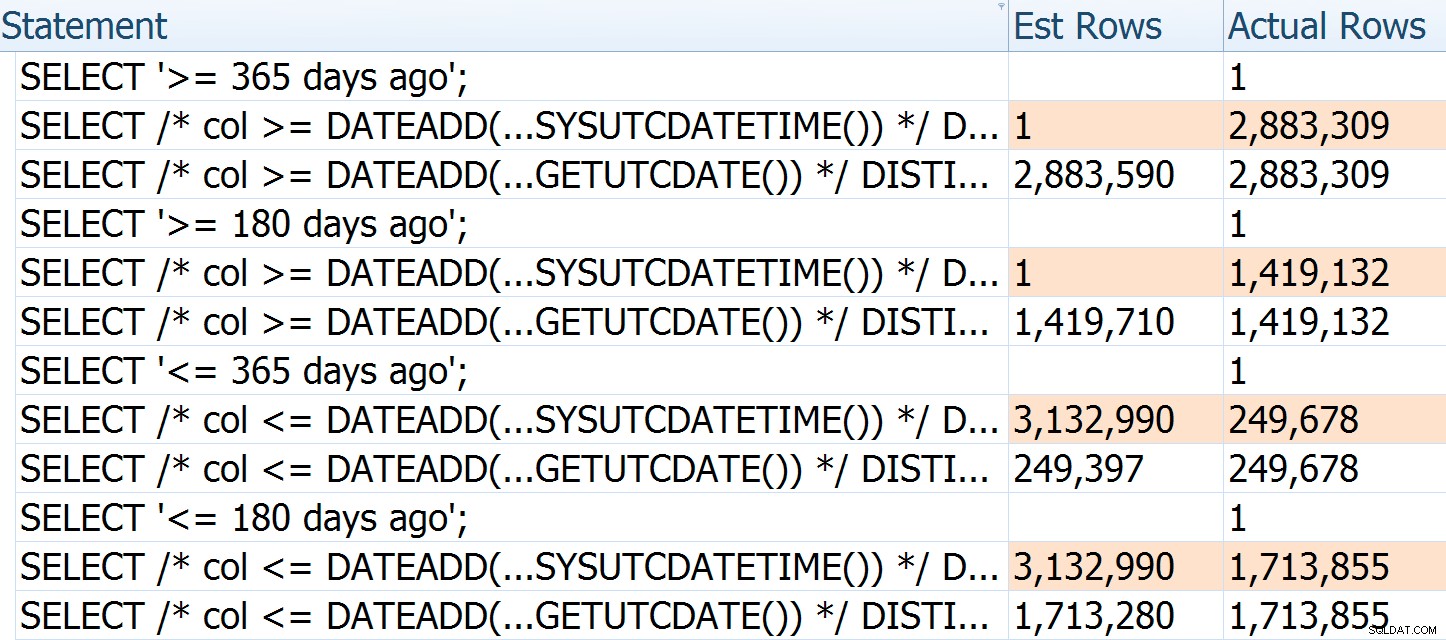 Faktiske rækker for den første forespørgsel er lidt lavere, fordi denne blev udført efter en længere lur
Faktiske rækker for den første forespørgsel er lidt lavere, fordi denne blev udført efter en længere lur
Estimaterne vil ikke altid være så gode; mit bord har bare relativt stabil fordeling. Jeg udfyldte den med følgende forespørgsel og opdaterede derefter statistikker med fullscan, hvis du vil prøve dette på egen hånd:
-- OP's table definition:
CREATE TABLE dbo.DateaddRepro
(
SessionId int IDENTITY(1, 1) NOT NULL PRIMARY KEY,
CreatedUtc datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME()
);
GO
CREATE NONCLUSTERED INDEX [IX_User_Session_CreatedUtc]
ON dbo.DateaddRepro(CreatedUtc) INCLUDE (SessionId);
GO
INSERT dbo.DateaddRepro(CreatedUtc)
SELECT dt FROM
(
SELECT TOP (3150000) dt = DATEADD(HOUR, (s1.[precision]-ROW_NUMBER()
OVER (PARTITION BY s1.[object_id] ORDER BY s2.[object_id])) / 15, GETUTCDATE())
FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2
) AS x;
UPDATE STATISTICS dbo.DateaddRepro WITH FULLSCAN;
SELECT DISTINCT SessionId FROM dbo.DateaddRepro
WHERE /* pick your WHERE clause to test */; Jeg kommenterede det nye Connect-element og vil sandsynligvis gå tilbage og opdatere mit Stack Exchange-svar.
Moralen i historien
Prøv at undgå at kombinere DATEADD() med udtryk, der giver datetime2 , især på ældre versioner af SQL Server (dette var på SQL Server 2012). Det kan også være et problem, selv på SQL Server 2016, når du bruger den ældre model for estimering af kardinalitet (på grund af lavere kompatibilitetsniveau eller eksplicit brug af sporingsflag 9481). Problemer som dette er subtile og ikke altid umiddelbart indlysende, så forhåbentlig tjener dette som en påmindelse (måske endda for mig, næste gang jeg støder på et lignende scenario). Som jeg foreslog i det sidste indlæg, hvis du har forespørgselsmønstre som dette, skal du kontrollere, at du får korrekte estimater, og notere et sted for at tjekke dem igen, når der er større ændringer i systemet (som en opgradering eller en servicepakke).