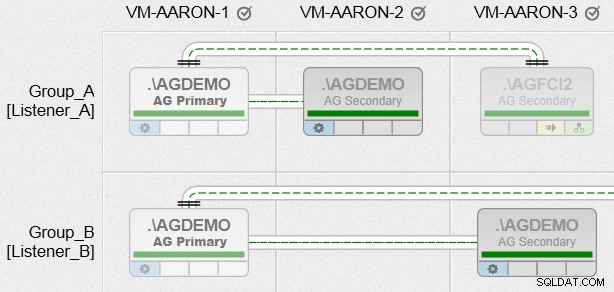
For et par uger siden begyndte jeg at konfigurere et demomiljø med flere konfigurationer af AlwaysOn Availability Groups. Jeg havde en 5-node WSFC-klynge – hver node havde en selvstændig navngivet forekomst af SQL Server 2012, og der var også to Failover Cluster Instances (FCI'er), der blev sat op oven på disse noder. Et hurtigt diagram:
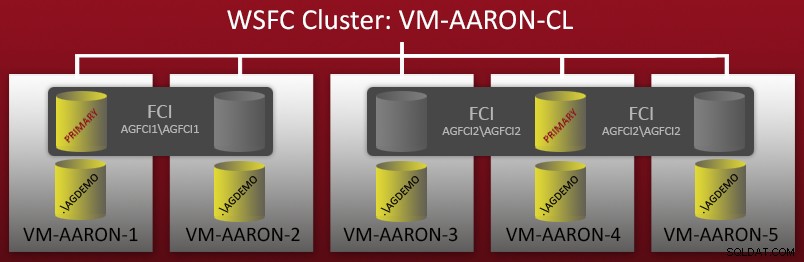
Så du kan se, at der er 5 selvstændige navngivne forekomster (.\AGDEMO på hver node), og derefter to FCI'er – en med mulige ejere VM-AARON-1 og VM-AARON-2 (AGFCI1\AGFCI1 ), og derefter en med mulige ejere VM-AARON-3, VM-AARON-4 og VM-AARON-5 (AGFCI2\AGFCI2 ). Nu skulle det blive væsentligt mere komplekst at tegne dette manuelt (mere om det senere), så jeg vil undgå det af indlysende årsager. Grundlæggende var kravet at have flere typer AG-konfigurationer:
- Primær på en FCI med en replika på en eller flere selvstændige forekomster
- Primær på en FCI med en replika på en anden FCI
- Primær på en selvstændig instans med en replika på en eller flere FCI'er
- Primær på en selvstændig instans med en replika på en eller flere selvstændige instanser
- Primær på en selvstændig instans med replikaer på både selvstændige instanser og FCI'er
Og så kombinationer (hvor det er muligt) af synkron vs. asynkron commit, manuel vs. automatisk failover og skrivebeskyttede sekundære. Der er nogle tekniske begrænsninger, der ville begrænse de mulige permutationer her, for eksempel:
- Manuel failover er nødvendig med enhver replika, der er på en FCI
- Ingen WSFC-node kan være vært for – eller endda være mulige ejere af – flere instanser, uanset om de er selvstændige eller grupperede, der er involveret i den samme tilgængelighedsgruppe. Du får denne fejlmeddelelse:Kunne ikke oprette, deltage i eller tilføje replika til tilgængelighedsgruppen 'MyGroup', fordi node 'VM-AARON-1' er en mulig ejer af både replika 'AGFCI1\AGFCI1' og 'VM-AARON-1\ AGDEMO'. Hvis en replika er failover-klyngeforekomst, skal du fjerne den overlappede node fra dens mulige ejere og prøve igen. (Microsoft SQL Server, fejl:19405)
De fleste af de scenarier, jeg prøvede at repræsentere, er ikke praktiske i scenarier i den virkelige verden, men de er stort set og teoretisk mulige . Hvis du ikke har gættet det nu, bliver dette miljø konfigureret eksplicit for at teste ny funktionalitet omkring Availability Groups, som vi planlægger at tilbyde i en fremtidig version af SQL Sentry. Vi gav et smugkig på noget af denne teknologi under vores keynote med Fusion-io på den nylige SQL Intersection-konference i Las Vegas.
Forhindring #1
Opsætning af tilgængelighedsgrupper ved hjælp af guiden i SSMS er ret nemt. Medmindre du for eksempel har heterogene filstier. Guiden har validering, der sikrer, at de samme data og logstier findes på alle replikaer. Dette kan være en smerte, hvis du bruger standarddatastien til to forskellige navngivne forekomster, eller hvis du har forskellige drevbogstavkonfigurationer (hvilket ofte vil ske, når FCI'er er involveret).
Kontrol af kompatibilitet af databasefilplaceringen på den sekundære replika resulterede i en fejl. (Microsoft.SqlServer.Management.HadrTasks)Følgende mappeplaceringer findes ikke på den serverinstans, der er vært for den sekundære replika VM-AARON-1\AGDEMO:
P:\MSSQL11.AGFCI2\MSSQL\DATA;
(Microsoft.SqlServer.Management.HadrTasks)
Nu burde det være en selvfølge, at du ikke ønsker at opsætte dette scenarie i nogen form for miljø, der skal bestå tidens tand. Det går meget hurtigt sydpå, hvis du for eksempel senere tilføjer en ny fil til en af databaserne. Men for et test-/demomiljø, proof of concept eller et miljø, du forventer at være stabilt i lang tid, skal du ikke bekymre dig:du kan stadig gøre dette uden guiden.
For at føje spot til skade, lader guiden dig desværre ikke skrive det. Du kan ikke komme forbi valideringsfejlen, og der er intet Script knap:
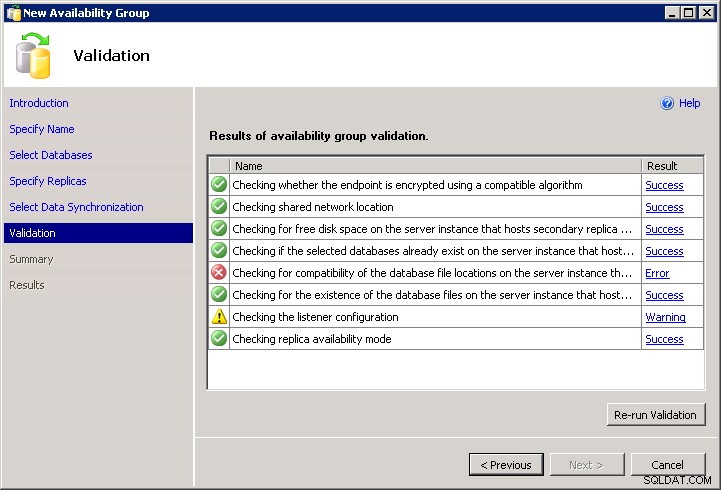
Så det betyder, at du skal kode det selv (da DDL ikke udfører nogen "nyttig" validering for dig). Hvis du har andre tilfælde, hvor de samme stier findes, kan du gøre dette ved at følge den samme guide, komme forbi valideringsskærmen og derefter klikke på Script i stedet for Finish , og skift servernavne og tilføj med WITH MOVE muligheder til den indledende gendannelse. Eller du kan bare skrive din egen fra bunden, noget som dette (scriptet antager, at du allerede har endepunkter og tilladelser konfigureret, og at alle forekomster har funktionen Tilgængelighedsgrupper aktiveret):
-- Brug SQLCMD-tilstand og fjern kommentarer til :CONNECT-kommandoerne-- eller kør bare de to segmenter separat / skift forbindelse-- :CONNECT Server1 OPRET TILGÆNGELIGHEDSGRUPPE [Gruppenavn] MED (AUTOMATED_BACKUP_PREFERENCE =SEKUNDÆR) FOR DATABASE [Database1] -- , ... REPLICA ON -- primær:N'Server1' WITH (ENDPOINT_URL =N'TCP://Server1:5022', FAILOVER_MODE =MANUAL, AVAILABILITY_MODE =ASYNCHRONOUS_COMMIT, BACKUP_PRIORITY =50, SEKUNDÆR_INGEN_ROLE), -SEKUNDÆR_INGEN_ROLE), - sekundær:N'Server2' WITH (ENDPOINT_URL =N'TCP://Server2:5022', FAILOVER_MODE =MANUAL, AVAILABILITY_MODE =ASYNCHRONOUS_COMMIT, BACKUP_PRIORITY =50, SEKUNDÆR_ROLE(ALLOW =_NONECTION)); ALTER AVAILABILITY GROUP [Gruppenavn] TILFØJ LYTTER N'ListenerName' (MED IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433); BACKUP DATABASE Database1 TO DISK ='\\Server1\Share\db1.bak' MED INIT, COPY_ONLY, KOMPRESSION; BACKUP LOG Database1 TO DISK ='\\Server1\Share\db1.trn' MED INIT, KOMPRESSION; -- :CONNECT Server2ALTER AVAILABILITY GROUP [Gruppenavn] JOIN; GENDAN DATABASE Database1 FRA DISK ='\\Server1\Share\db1.bak' MED REPLACE, NORECOVERY, NOUNLOAD, FLYT 'data_file_name' TIL 'P:\path\file.mdf', FLYT 'log_file_name' TIL 'P:\path \file.ldf'; GENDAN LOG Database1 FRA DISK ='\\Server1\Share\db1.trn' MED NORRECOVERY, NOUNLOAD; ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP =[Gruppenavn];
Forhindring #2
Hvis du har flere forekomster på den samme server, kan du opleve, at begge forekomster ikke kan dele port 5022 for deres databasespejlingsendepunkt (som er det samme slutpunkt, som bruges af Availability Groups). Det betyder, at du bliver nødt til at droppe og genskabe slutpunktet for at sætte det til en tilgængelig port i stedet.
DROP ENDPOINT [Hadr_endpoint];GO OPRET ENDPOINT [Hadr_endpoint] STATE =STARTET SOM TCP ( LISTENER_PORT =5023 ) TIL DATABASE_MIRRORING (ROLE =ALLE);
Nu kunne jeg angive en instans med et slutpunkt på ServerName:5023 .
Forhindring #3
Men når jeg gjorde dette, da jeg nåede det sidste trin i scriptet ovenfor, efter præcis 48 sekunder – hver gang – ville jeg få denne uhensigtsmæssige fejlmeddelelse:
Msg 35250, Level 16, State 7, Line 2Forbindelsen til den primære replika er ikke aktiv. Kommandoen kan ikke behandles.
Dette fik mig til at jage alle mulige mulige problemer – for eksempel at tjekke firewalls og SQL Server Configuration Manager for alt, der ville blokere portene mellem instanser. Nada. Jeg fandt forskellige fejl i SQL Servers fejllog:
Forsøg på login til databasespejling mislykkedes med fejl:'Forbindelseshåndtryk mislykkedes. Der er ingen kompatibel krypteringsalgoritme. Tilstand 22.'.Forsøg på login til databasespejling mislykkedes med fejl:'Forbindelseshåndtryk mislykkedes. Et OS-kald mislykkedes:(80090303) 0x80090303(Det angivne mål er ukendt eller kan ikke nås). Tilstand 66.'.
Der opstod en forbindelsestimeout under forsøg på at etablere en forbindelse til tilgængelighedsreplika 'VM-AARON-1\AGDEMO' med id [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0]. Enten eksisterer der et netværks- eller firewallproblem, eller også er den endepunktsadresse, der er angivet for replikaen, ikke det databasespejlingsendepunkt for værtsserverforekomsten.
Det viser sig (og takket være Thomas Stringer (@SQLife)), at dette problem var forårsaget af en kombination af symptomer:(a) Kerberos var ikke konfigureret korrekt, og (b) krypteringsalgoritmen for hadr_endpoint, jeg havde oprettet, var standard til RC4. Dette ville være okay, hvis alle de selvstændige forekomster også brugte RC4, men det var de ikke. Lang historie kort, jeg droppede og genskabte slutpunkterne igen , i alle tilfælde. Da dette var et laboratoriemiljø, og jeg ikke rigtig havde brug for Kerberos-support (og fordi jeg allerede havde investeret nok tid i disse problemer til, at jeg ikke også ønskede at forfølge Kerberos-problemer), satte jeg alle endepunkter op til at bruge Negotiate med AES:
DROP ENDPOINT [Hadr_endpoint];GO OPRET ENDPOINT [Hadr_endpoint] STATE =STARTET SOM TCP ( LISTENER_PORT =5023 ) FOR DATABASE_MIRRORING (GODKENDELSE =WINDOWS FORHANDLING, KRYPTERING =PRØVET ALLE KRÆVET =PRØVET =PRØVET ELLER KRÆVET);(Ted Krueger (@onpnt) bloggede også for nylig om et lignende problem.)
Nu var jeg endelig i stand til at oprette tilgængelighedsgrupper med alle de forskellige krav, jeg havde, mellem noder med heterogene filstier og ved at bruge flere forekomster på den samme node (bare ikke i den samme gruppe). Her er et kig på, hvordan en af vores AlwaysOn Management-visninger vil se ud (klik for at forstørre for et meget bedre overblik):
Nu er det bare lidt af en drilleri, og det er fuldt ud med vilje. Jeg vil blogge mere om denne funktionalitet i de kommende uger!
Konklusion
Når du bruger længe nok på at se på et problem, kan du overse nogle ret indlysende ting. I dette tilfælde var der nogle åbenlyse problemer skjult af nogle direkte uintuitive fejlmeddelelser. Jeg vil gerne takke Joe Sack (@JosephSack), Allan Hirt (@SQLHA) og Thomas Stringer (@SQLife) for at droppe alt for at hjælpe et andet samfundsmedlem i nød.